이 글에서는 초창기 Object Detection 분야에 큰 획을 그은 모델인 R-CNN (Regions with CNN features)에 대해 다룬다.
📌 R-CNN이란?
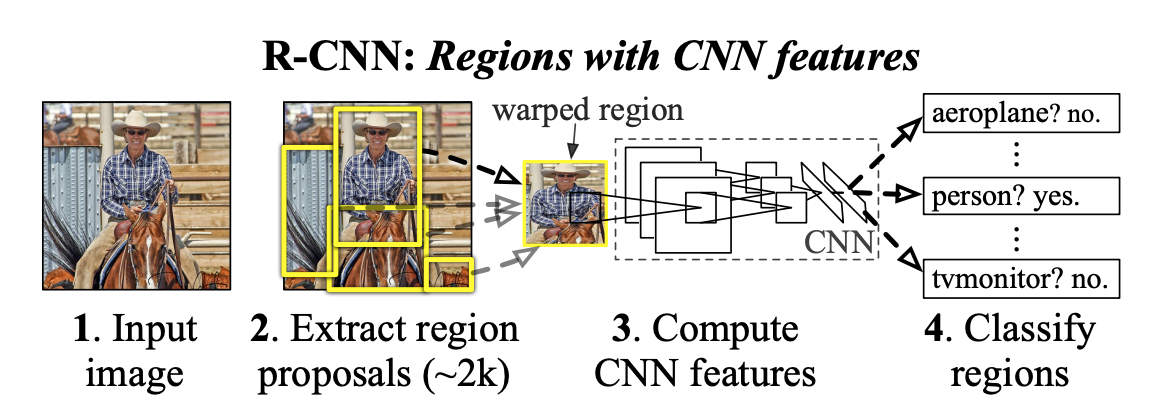
R-CNN이란 이미지 내에서 객체의 위치를 찾고 (Localization) 그 종류를 분류(Classification)하는 딥러닝(CNN)을 본격적으로 도입한 객체 탐지 (Object Detection) 모델이다.
구조
🎯 R-CNN의 수행 과정
-
Input Image
먼저 탐지하고자 하는 이미지를 입력한다. -
Region proposal
입력 이미지에 Selective search 알고리즘을 적용하여, 객체가 존재할 가능성이 높은 영역 (Region Proposal)을 약 2000개를 추출하고 각각에 Bounding Box를 생성한다. -
Warping
추출된 2,000개의 후보 영역들은 저마다 크기와 비율이 다르다. 이를 CNN 모델에 넣기 위해서는 크기를 통일해야 하므로, 비율을 무시하고 강제로 늘리거나 줄여 227x227 픽셀 사이즈로 변형(Warping) 한다.
💡 왜 227x227 픽셀인가?
R-CNN은 특징 추출을 위해 당시 ImageNet 우승 모델이었던 AlexNet을 가져와 사용하였다. 이 모델의 고정된 입력 사이즈가 바로 227x227 픽셀이다.
-
CNN feature extract
Warping을 통해 동일한 크기로 조절된 2,000개의 Bounding Box 들을 CNN에 통과시켜, 이미지를 대표하는 고유한 특징 벡터(Feature Vector)를 추출한다. -
Image Classification
CNN을 통해 추출된 특징 벡터를 바탕으로, 해당 영역이 어떤 객체인지 분류합니다. 이때 분류기(Classifier)로는 딥러닝 내부의 Softmax 대신, 기계학습 모델인 SVM (Support Vector Machine)을 사용한다.
💡 왜 분류기로 SVM을 썼을까?
논문에 따르면, 당시 CNN 자체의 분류기(Softmax)를 사용하는 것보다 SVM을 따로 붙여서 학습시키는 것이 정확도 측면에서 더 좋은 결과를 보여주었기 때문이다. SVM을 거치고 나면 2,000개의 Bounding Box들은 각각 특정 객체일 확률값을 가지게 된다.
-
Non-Maximum Suppression(NMS)
2,000개의 박스를 모두 최종 결과로 사용지는 않는다. 하나의 동일한 객체 주변에 여러 개의 Bounding Box가 겹쳐서 예측되는 경우가 많기 때문이다. 이를 해결하기 위해 NMS를 적용하여, 겹치는 박스들 중 가장 확률이 높은 박스 하나만 남기고 나머지는 제거한다. -
Bounding Box Regression(BBR)
Selective Search로 초기에 찾은 Bounding Box의 위치는 완벽하지 않고 다소 부정확하다. 따라서 박스의 위치와 크기를 더욱 정교하게 교정하여 모델의 최종 성능을 높이는 과정이 필요한데, 이를 Bounding Box Regression이라고 한다.
실제 정답(Ground Truth)을 , 초기에 예측한 Bounding Box를 라고 할 때, 위치는 중심점 좌표 와 박스의 크기 로 표현된다.BBR의 핵심 목표는 입력된 를 이동시키고 크기를 조절하여 정답 에 최대한 가깝게 예측()하는 것이다. 이를 위해 좌표에는 이동량()을 더하고, 너비와 높이에는 크기 조절 비율()을 곱해 예측치 를 만든다.여기서 우리가 학습시켜야 하는 것은 를 로 이동시키는 함수이다. 반면, 를 실제 정답 로 이동시키기 위해 필요한 '이상적인 이동량'은 함수로 정의한다.
최종적인 Loss Function(손실 함수)은 예측된 이동량( 함수)과 이상적인 이동량( 함수) 간의 차이(MSE)에, 과적합을 방지하기 위한 L2 정규화(Normalization) 항이 추가된 형태를 띤다.
⚠️ R-CNN의 단점
R-CNN은 Object Detection 분야에 딥러닝을 성공적으로 안착시킨 획기적인 모델이었지만, 초기 모델인 만큼 여러 가지 명확한 단점들이 존재하였다.
-
Warping으로 인한 성능 저하:
AlexNet의 입력 사이즈에 맞추기 위해 2,000개의 이미지를 강제로 찌그러뜨리는 Warping 과정에서 이미지의 기하학적 왜곡과 정보 손실이 발생하여 객체 인식 성능이 떨어진다. -
너무 느린 속도 (연산량 폭발):
Selective Search를 통해 뽑힌 2,000개의 Region Proposal 후보를 일일이 각각 CNN에 집어넣어 연산해야 하므로, 학습(Training)과 추론(Testing)에 엄청난 시간이 소요된다. -
GPU 비효율성:
핵심 과정인 Selective Search나 SVM은 CPU 기반 알고리즘으로, GPU 병렬 처리의 이점을 살리기에 적합한 구조가 아니다. -
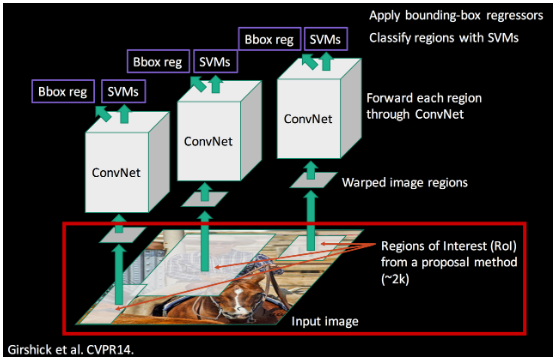
분리된 학습 구조 (Not End-to-End):
CNN, SVM, Bounding Box Regression이라는 세 가지 모델이 각각 따로 노는 구조이다. 연산이 공유되지 않을뿐더러, SVM이나 BBR을 학습시킨 결과가 CNN으로 역전파되지 않아 CNN의 가중치를 업데이트할 수 없다. 즉, 한 번에 통째로 학습시키는 End-to-End 훈련이 불가능하다.💡 쉽게 말해 이런 문제가 발생한다!
CNN에서 넘겨준 Feature 데이터의 품질이 떨어져서 Loss가 크게 발생하더라도 역전파 과정을 통해 가중치를 수정할 수 없다. 결국 모델 전체가 유기적으로 학습되지 못하고, 사용자가 'CNN 특징 추출 디스크에 수백 GB 단위로 따로 저장 SVM 따로 학습 BBR 따로 학습' 이라는 번거로운 과정을 단계별로 끊어서 진행해야 한다.
이러한 R-CNN의 속도 문제와 구조적 한계를 극복하기 위해, 다음 포스팅에서는 한층 진화한 Fast R-CNN에 대해 알아보겠다!
요약
🔹 개념
- CNN을 처음으로 Object Detection에 적용한 모델
- Region Proposal + CNN + SVM + BBR 구조
🔹 동작 과정
- Selective Search → 약 2000개 후보 영역 생성
- 각 영역을 227×227로 변형 (Warping)
- CNN으로 특징 추출
- SVM으로 분류
- BBR로 박스 보정
- NMS로 중복 제거
🔹 핵심 특징
- CNN + 전통 ML(SVM) 혼합 구조
- 단계별로 따로 학습 (비 end-to-end)
🔹 문제점 (핵심)
- ❌ 속도 매우 느림 (2000번 CNN 실행)
- ❌ Warping으로 정보 손실
- ❌ GPU 활용 어려움
- ❌ End-to-End 학습 불가
