Fast R-CNN
이전 포스팅에서 다룬 R-CNN은 딥러닝 객체 탐지의 서막을 열었지만, 극복해야할 명확한 한계점들을 가지고 있었다.
❗ R-CNN의 치명적인 문제
-
성능 손실: AlexNet에 넣기 위해 이미지를 227x227 으로 강제로 Warping 시켜 형태 왜곡 발생
-
느린 속도: Selective Search로 뽑은 2,000개의 Region Proposal을 일일이 CNN에 통과시켜 학습/추론 시간이 너무 오래 걸림
-
GPU 비효율: Selective Search나 SVM은 CPU 기반 알고리즘이라 병렬 처리 불가
-
Not End-to-End: CNN, SVM, Bounding Box Regression(BBR) 모델이 서로 연산을 공유하지 않고 따로 학습됨
💡 Fast R-CNN의 핵심 혁신
Fast R-CNN이 R-CNN의 단점을 극복한 핵심 무기는 크게 두 가지이다.
-
RoI Pooling 도입: 2,000번의 CNN 연산을 1번으로 줄임.
-
Multi-task Loss 적용: CNN 특징 추출부터 Classification, BBR까지 하나의 모델에서 한 번에 학습(End-to-End)이 가능해졌다.
SPP (Spatial Pyramid Pooling) 와 RoI Pooling
R-CNN에서는 이미지를 CNN에 넣으려면 크기가 똑같아야 한다고 알고있었다. 하지만 실제로는 "합성곱 층(CNN)은 입력 크기에 상관없고, 그 뒤에 붙는 완전 연결 층(FC Layer)만 입력 크기가 고정되어야 한다"는 사실이 밝혀졌다.
따라서 CNN에는 입력 이미지 크기, 비율 관계없이 input으로 들어갈 수 있고 FC layer의 input으로 들어갈때만 size를 맞춰주기만 하면 된다.
여기서 Spatial Pyramid Pooling이 제안된다.
-
SPP (Spatial Pyramid Pooling): 제각각인 크기의 Feature Map을 4x4, 2x2, 1x1 등 여러 크기의 피라미드 그리드로 나눈 뒤 Max Pooling을 적용하여, 결국엔 고정된 1차원 Vector로 쭉 이어 붙여주는 획기적인 기법이다.
💡 피라미드 그리드란?
창문을 여러 개로 쪼개서 보는 것과 같다. 이미지 전체를 통유리(1x1)로 한 번 보고, 십자가로 쪼개서(2x2) 보고, 더 잘게 쪼개서(4x4) 본 뒤, 각 칸에서 가장 특징적인 값(Max)만 뽑아내는 방식이다. 어떤 크기의 이미지가 들어와도 항상 똑같은 개수의 칸으로 쪼개기 때문에 고정된 길이의 결과를 얻을 수 있다. -
RoI Pooling: Fast R-CNN은 이 SPP에서 아이디어를 얻어, 여러 피라미드 층을 쓰지 않고 오직 하나의 피라미드(7x7 단일 사이즈 그리드)만 적용하는 방식으로 단순화한 RoI Pooling 기법을 고안해 냈습니다.
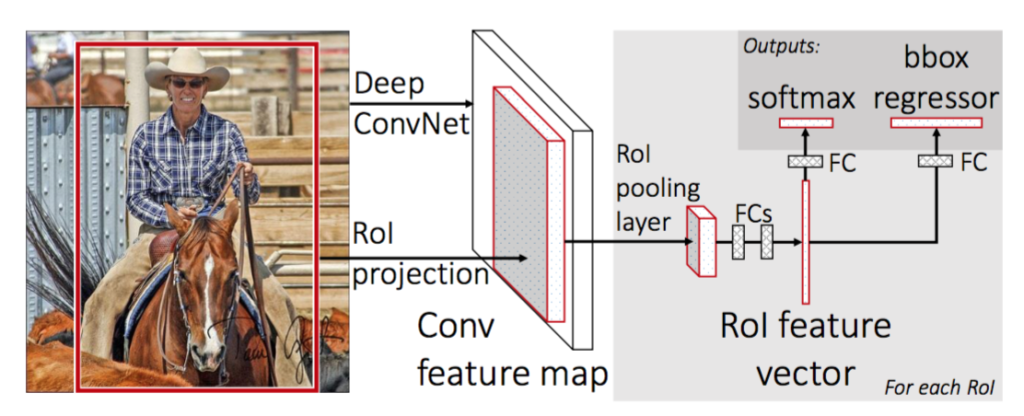
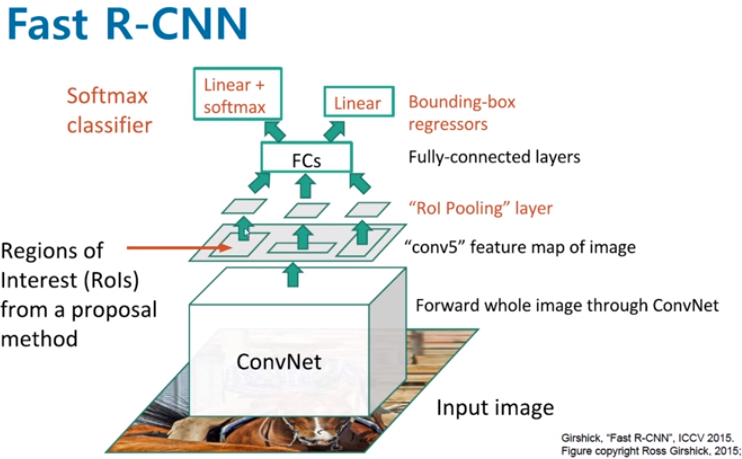
⚙️ Fast R-CNN 네트워크 구조와 수행 과정
논문에서 저자들이 제시한 VGG16 기반의 네트워크 구조를 구체적인 차원 숫자들과 함께 따라가 보겠다.
- CNN Feature Extraction & Region Proposal (동시 진행)
-
1-1 CNN : Input Image 전체를 VGG16 네트워크(Convolutional Layer 13번째 층까지만)에 단 한 번만 통과시킨다. 그 결과 14x14x512 크기의 하나의 거대한 Feature Map이 추출된다.
-
1-2 Region Proposal: Selective Search를 통해 RoI를 약 2,000개 찾는다.
-
Region Projection (영역 투영)
원본 이미지에서 찾은 2,000개의 RoI(Bounding Box) 위치 좌표를, 1-1 과정에서 CNN을 통과하며 쪼그라든 14x14 Feature Map의 비율에 맞춰 그대로 투영(Projection)한다. -
RoI Pooling
VGG16의 마지막 Max Pooling Layer를 RoI Pooling Layer로 대체한다.
- Input: 제각각의 크기로 투영된 2,000개의 RoI 영역 데이터
- Process: 각 RoI 영역을 7x7 크기의 Grid로 나눈 뒤, 각 칸마다 Max Pooling을 수행합니다.
- Output: 크기에 상관없이 모든 박스가 7x7x512 크기의 Feature Map으로 통일되어 출력됩니다. (총 2,000개)
- FC Layer 통과 (특징 벡터 추출)
RoI Pooling을 거친 7x7x512 데이터를 1차원으로 쭉 펼쳐서(Flatten) FC Layer에 입력하면, 박스 1개당 4096 크기의 고정된 Feature Vector를 얻게 된다. 이 4096 벡터는 두 갈래(Branch)로 나뉘어 최종 예측을 수행한다.
-
4-1. Image Classification: 4096 벡터가 FC Layer(Softmax)를 통과하여, K개의 객체 클래스 + 배경(1개)을 포함한 (K+1) 크기의 확률 벡터를 출력한다.
-
4-2. Bounding Box Prediction: 동시에, 각 클래스별로 박스의 좌표(x, y, w, h)를 정밀하게 예측하기 위해 (K+1) x 4 크기의 벡터를 출력한다.
- Multi-task Loss & Training (End-to-End)
분리되어 있던 R-CNN과 달리, Fast R-CNN은 두 갈래에서 나온 예측 결과를 바탕으로 Classification Loss와 BBR Loss를 하나로 묶은 Multi-task Loss를 계산한다. 그리고 이 통합된 Loss를 사용해 Backpropagation을 수행함으로써 전체 네트워크를 한 번에 학습시킨다. (마지막엔 NMS를 거쳐 중복 박스를 제거한다.)
(참고: 논문 저자들은 VGG16의 Conv layer 3까지의 가중치는 고정하고, 이후 Layer만 학습되도록 설정했을 때 성능이 가장 좋았다고 밝혀졌다.)
⚖️ Fast R-CNN 요약: 장점과 남은 단점
👍 장점
-
압도적인 연산량 감소: R-CNN에서 2,000번씩 하던 무거운 CNN 연산을 단 1번으로 줄여 속도를 비약적으로 향상시켰다.
-
성능 손실 방지: RoI Pooling을 통해 이미지 Warping 작업을 제거함으로써, 기하학적 왜곡으로 인한 성능 손실을 막아냈다. (Pascal VOC 2007 데이터 셋 기준 mAP 66% 기록)
-
End-to-End 학습: CNN 특징 추출부터 Classification, BBR을 모두 하나의 네트워크에서 묶어서 학습시키는 구조를 완성했다.
👎 단점 (한계점)
-
Fast R-CNN은 이전 모델에 비해 혁신적으로 빨라졌지만, 실시간(Real-time) 탐지에 쓰기에는 여전히 느리다.
-
가장 큰 원인은 바로 Region Proposal 단계에 있다. 딥러닝 네트워크 내부 연산은 엄청나게 빨라졌지만, 정작 후보 영역을 찾아주는 Selective Search 알고리즘 자체가 CPU에서 돌아가다 보니 심각한 병목(Bottleneck) 현상이 발생한다.
🚀 마무리하며
이번 포스팅에서는 RoI Pooling을 무기로 CNN 연산을 하나로 통합하여 속도와 정확도를 동시에 끌어올린 Fast R-CNN에 대해 알아보았다.
하지만 모델 외부(CPU)에서 연산되는 Selective Search 알고리즘의 병목 현상 때문에 완벽한 속도 혁신은 이루지 못했다. 따라서 이 Region Proposal 작업마저 딥러닝 네트워크(GPU) 내부로 끌고 들어와, 더욱 빠르고 정확하게 RoI를 생성해 내는 Faster R-CNN이 등장하게 된다.
요약
🔹 등장 배경
👉 R-CNN의 “속도 + 구조 문제” 해결
🔹 핵심 아이디어
- CNN 연산 1번만 수행
- RoI Pooling으로 크기 통일
- Multi-task Loss → End-to-End 학습
🔹 동작 과정
- 이미지 전체를 CNN에 한 번 통과 → Feature Map 생성
- Selective Search로 RoI 추출
- RoI를 Feature Map에 투영
- RoI Pooling → 7×7 고정 크기
- FC Layer → Feature Vector 생성
- 두 갈래 출력
- Softmax → 분류
- BBR → 박스 위치 보정
- NMS로 최종 결과 생성
🔹 핵심 기술
- RoI Pooling
- 다양한 크기의 영역 → 동일 크기 변환
- SPP 아이디어 활용
- Multi-task Loss
- Classification + BBR 동시에 학습
🔹 장점
- ✅ CNN 연산 2000 → 1번 (속도 대폭 향상)
- ✅ Warping 제거 → 성능 유지
- ✅ End-to-End 학습 가능
- ✅ 정확도 증가
🔹 한계
- ❌ Selective Search 여전히 느림 (CPU 병목)
→ 완전한 실시간 처리 불가
