지난 포스팅까지 우리는 R-CNN 계열(2-Stage Detector)이 어떻게 발전해 왔는지 살펴보았다.
Faster R-CNN에 이르러 RPN을 도입하며 속도를 비약적으로 끌어올렸지만, 여전히 '후보 영역 추출'과 '분류'라는 두 단계를 거쳐야 한다는 구조적 한계가 있었다.
오늘 소개할 YOLO(You Only Look Once)는 이름 그대로 "이미지를 단 한 번만 보고" 객체를 탐지해내는, 1-Stage Detector 모델이다.
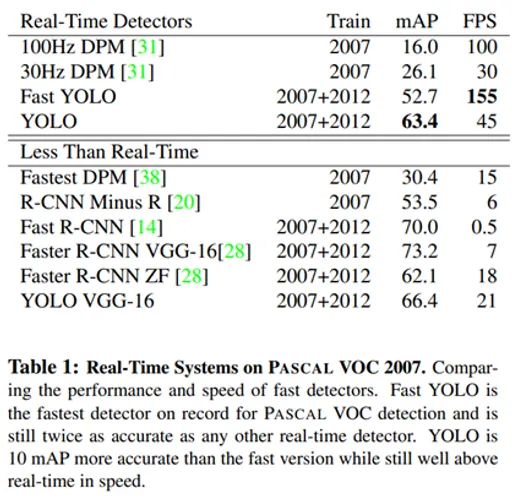
객체 탐지 성능을 평가하는 두가지 지표가 있다.
mAP로 측정하는 정확도와 FPS로 측정하는 수행시간(inference time)이다.
YOLO v1이 처음 나왔을 당시에 정확도는 Faster R-CNN보다 부족했지만 속도에서는 매우 큰 발전을 보였다.
YOLO 구조를 살펴보자
📌 YOLO 네트워크 구조
YOLO v1의 아키텍처는 24+2 구조를 가지고 있다.
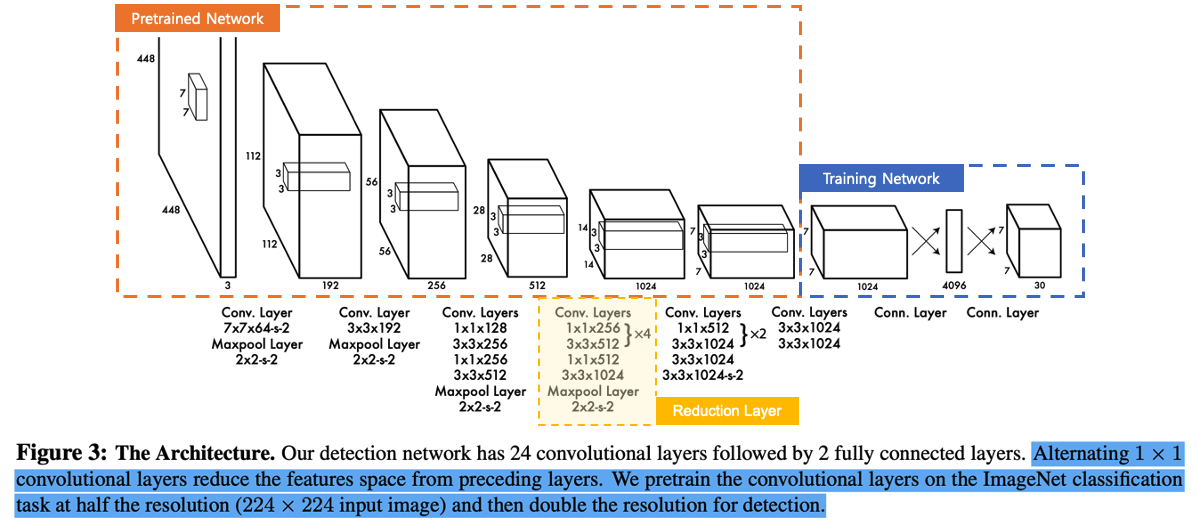
- 두 가지 네트워크 그룹: Pretrained & Training
- Pretrained Network (앞의 20개의 Conv layers)
ImageNet 데이터셋으로 분류 작업에 대해 사전 학습시킨다
이때 연산 효율을 위해 해상도로 학습하며, 사물의 핵심적인 특징(Feature)을 추출하는 방법을 학습한다. - Training Network (뒤의 4개의 Conv + 2개의 FC layers)
사전 학습된 층 뒤에 객체 탐지(Detection) 전용 층을 추가한다. 정밀한 위치 추적을 위해 입력 해상도를 로 2배 높여서 학습을 진행한다.
Training network 까지 거치고 나면 최종적으로 7x7x30 크기의 tensor가 출력된다.아키텍처 이미지에 448x448 입력만 보이는 이유는 Figure3 구조도는 Pretrain이 아니라 'Detection용' 네트워크 구조이기 때문이라고 함
24개의 Conv layer와 2개의 FC layer를 거친 결과는 7x7x30 으로 나오게 된다. 그 이유를 알아보자.
Unified Detection
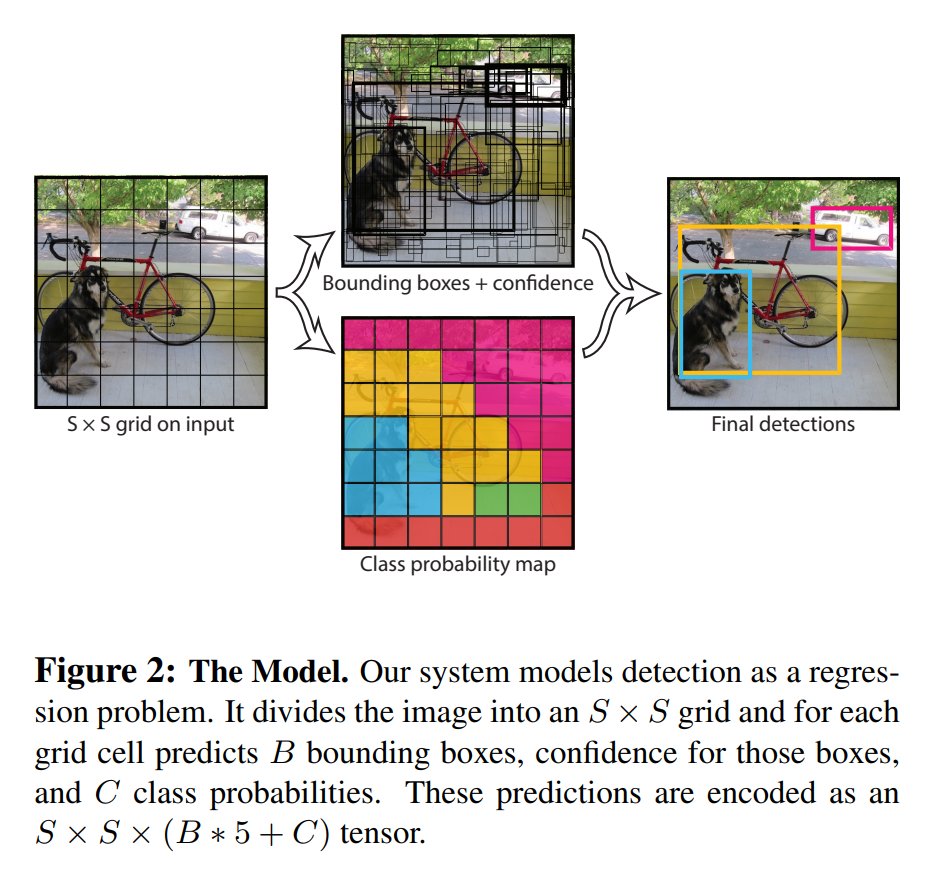
- Input image를 로 나눈다.
- 각각의 grid cell은 B개의 bounding box와 각 bounding box에 대한 confidence score를 갖는다.
- 각각의 grid cell은 C개의 conditional class probability를 갖는다.
- 각각의 bounding box는 x, y, w, h, confidence로 구성된다.
- (x,y): Bounding box의 중심점을 의미하며, grid cell의 범위에 대한 상대값이 입력된다.
- (w,h): 전체 이미지의 width, height에 대한 상대값이 입력된다.
논문에서는 PASCAL VOC를 사용하였으며, S,B,C에는 각각 7, 2, 20이 할당되었다.
PASCAL VOC(Visual Object Classes) : 컴퓨터 비전 분야에서 객체 탐지(Object Detection), 분할(Segmentation), 분류(Classification) 알고리즘의 성능을 평가하는 대표적인 벤치마크 데이터셋으로, 20개의 클래스로 구성되어 있다.
추론 과정
Deep systems의 슬라이드를 인용하였다.
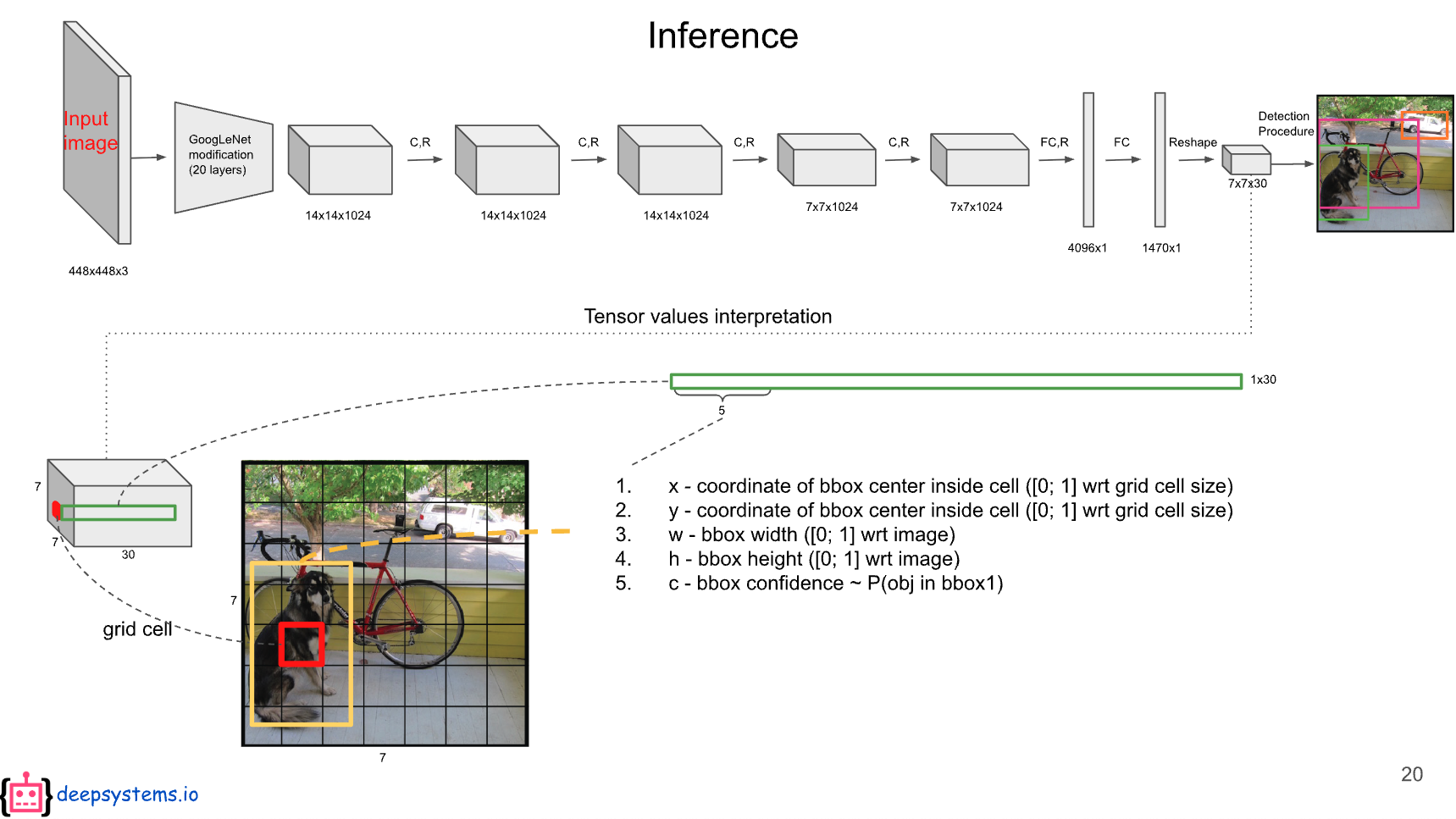
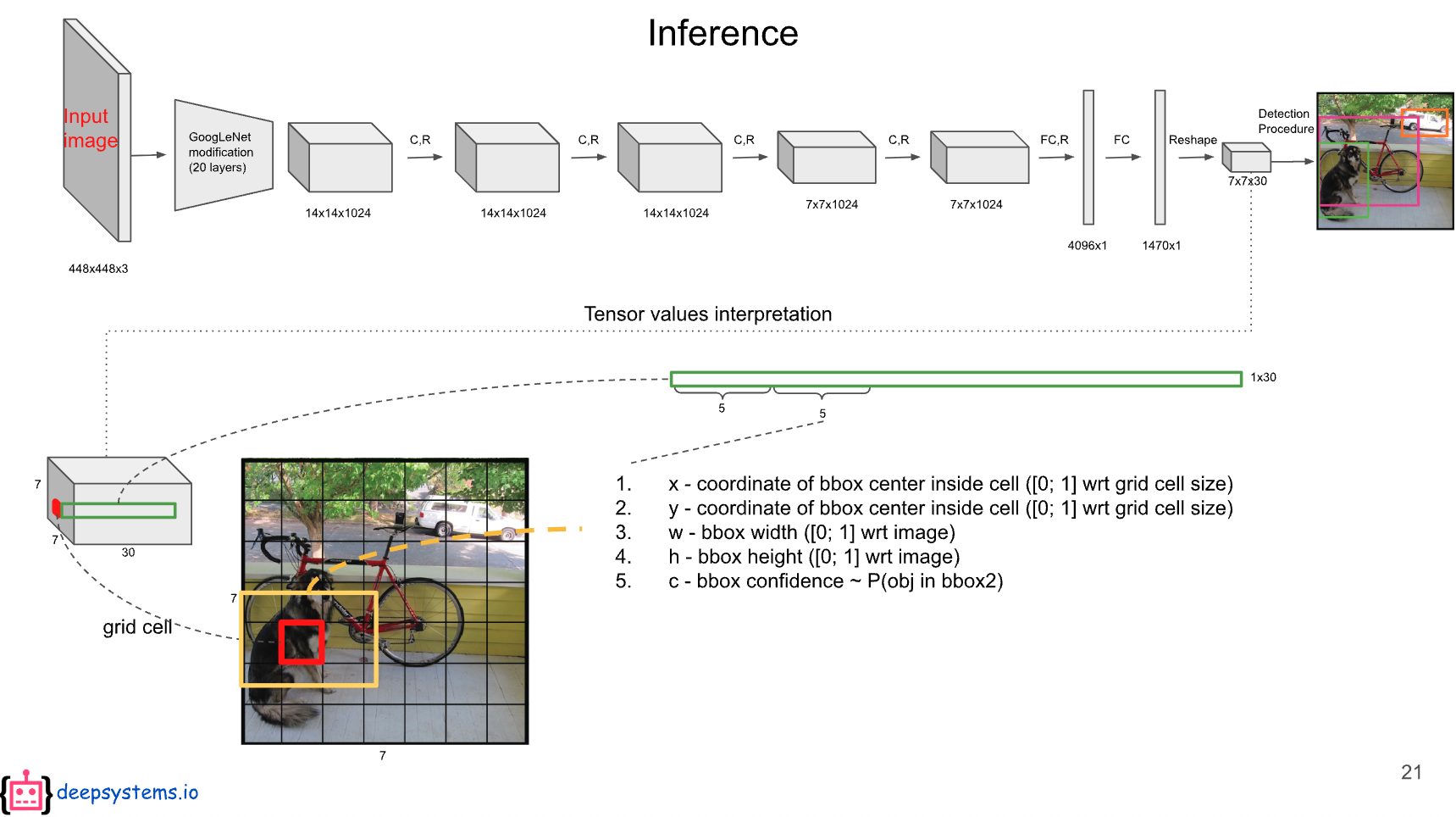
7x7은 49개의 Grid cell을 의미한다. 각 그리드 셀은 2개의 bounding box를 가지고 있는데, 각각 5차원씩 bounding box에 대한 값이 채워져 있다.
예) [x좌표,y좌표,너비,높이,객체가 bounding box에 있을 확률]
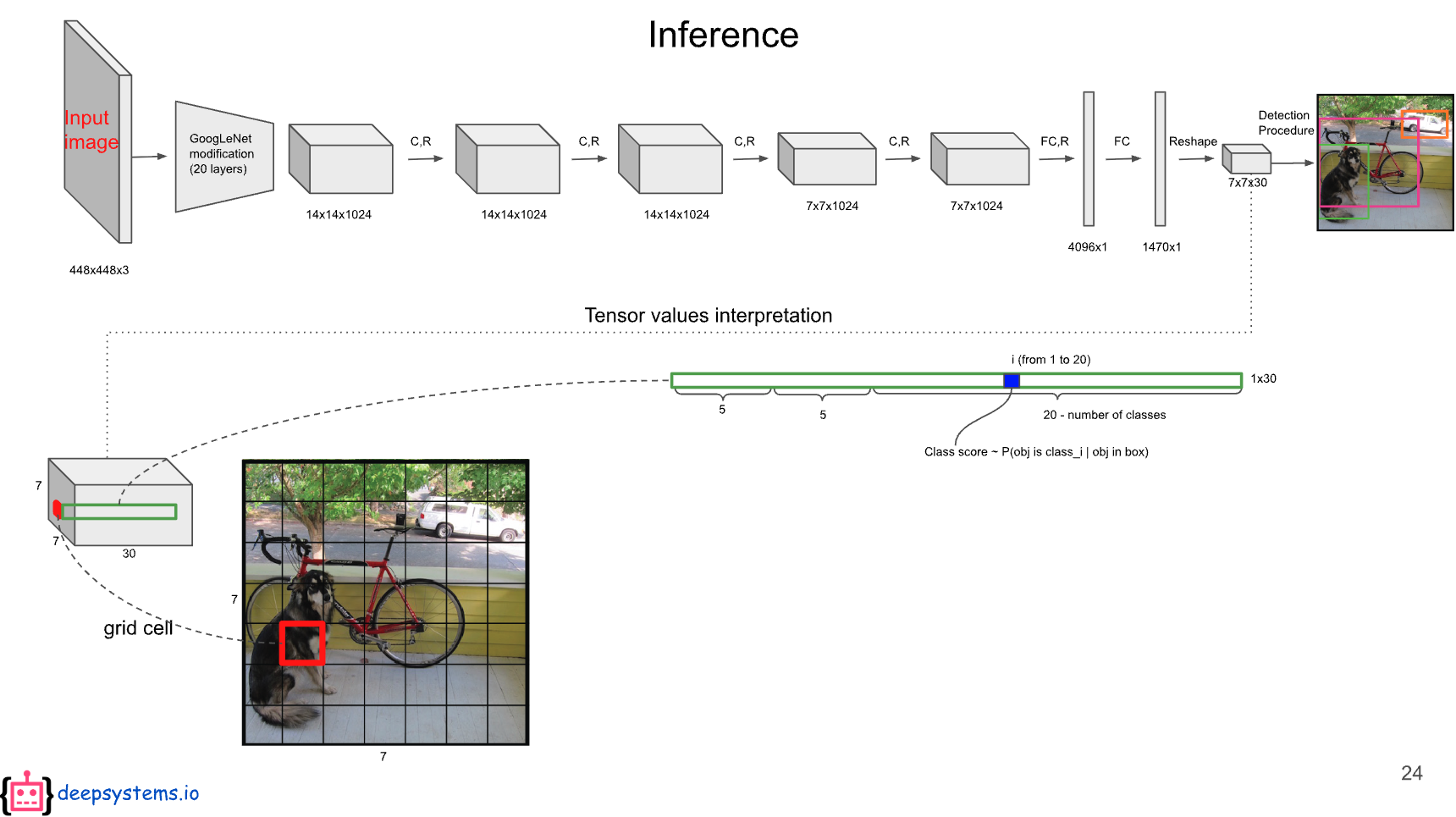
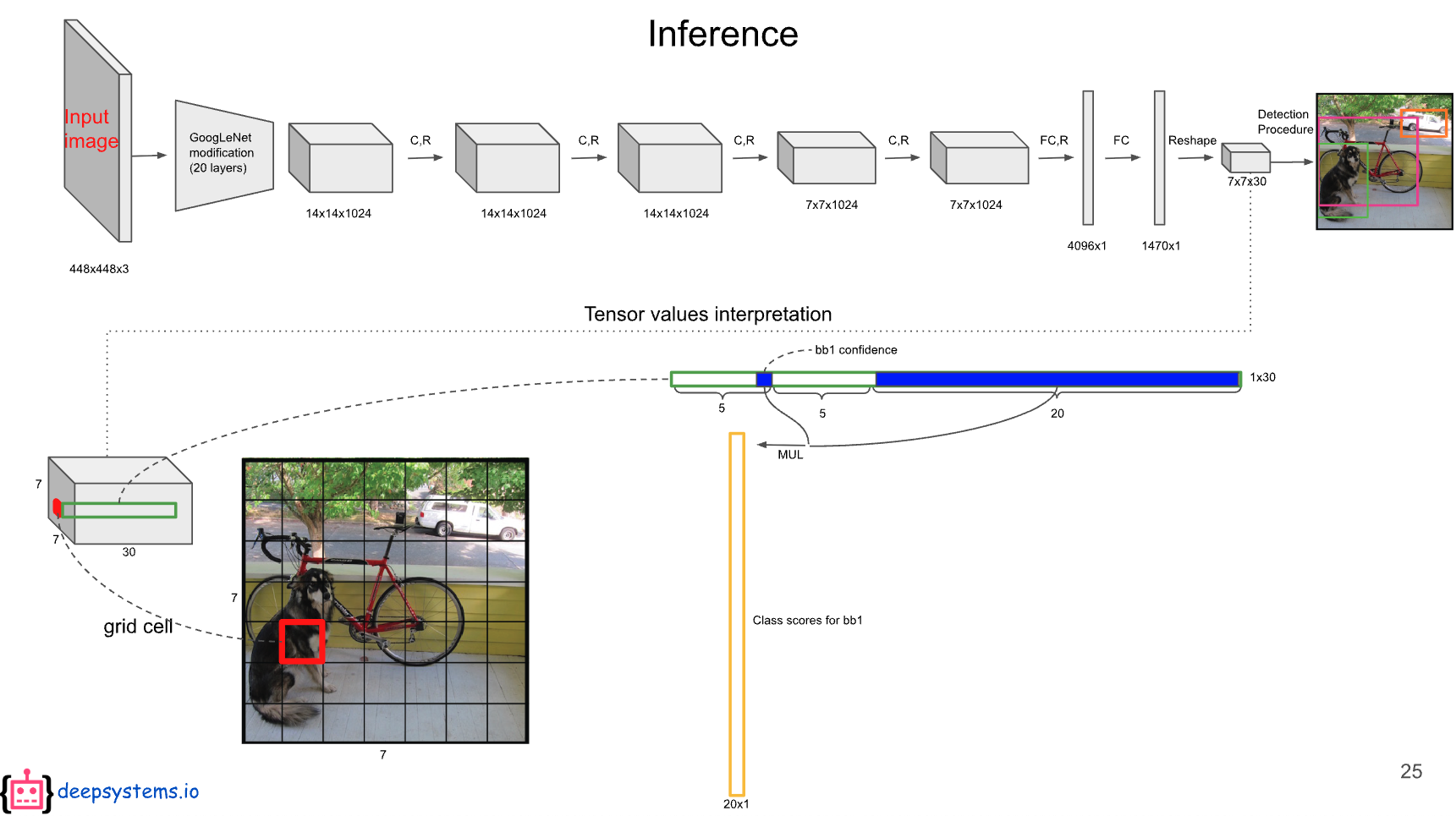
나머지 20개의 값은 20개의 class에 대한 conditional class probability에 해당한다.
첫 번째 bounding box의 confidence score와 각 conditional class probability를 곱하면 첫 번째 bounding box의 class specific confidence score가 나온다.
마찬가지로, 두 번째 bounding box의 confidence score와 각 conditional class probability를 곱하면 두 번째 bounding box의 class specific confidence score가 나온다.
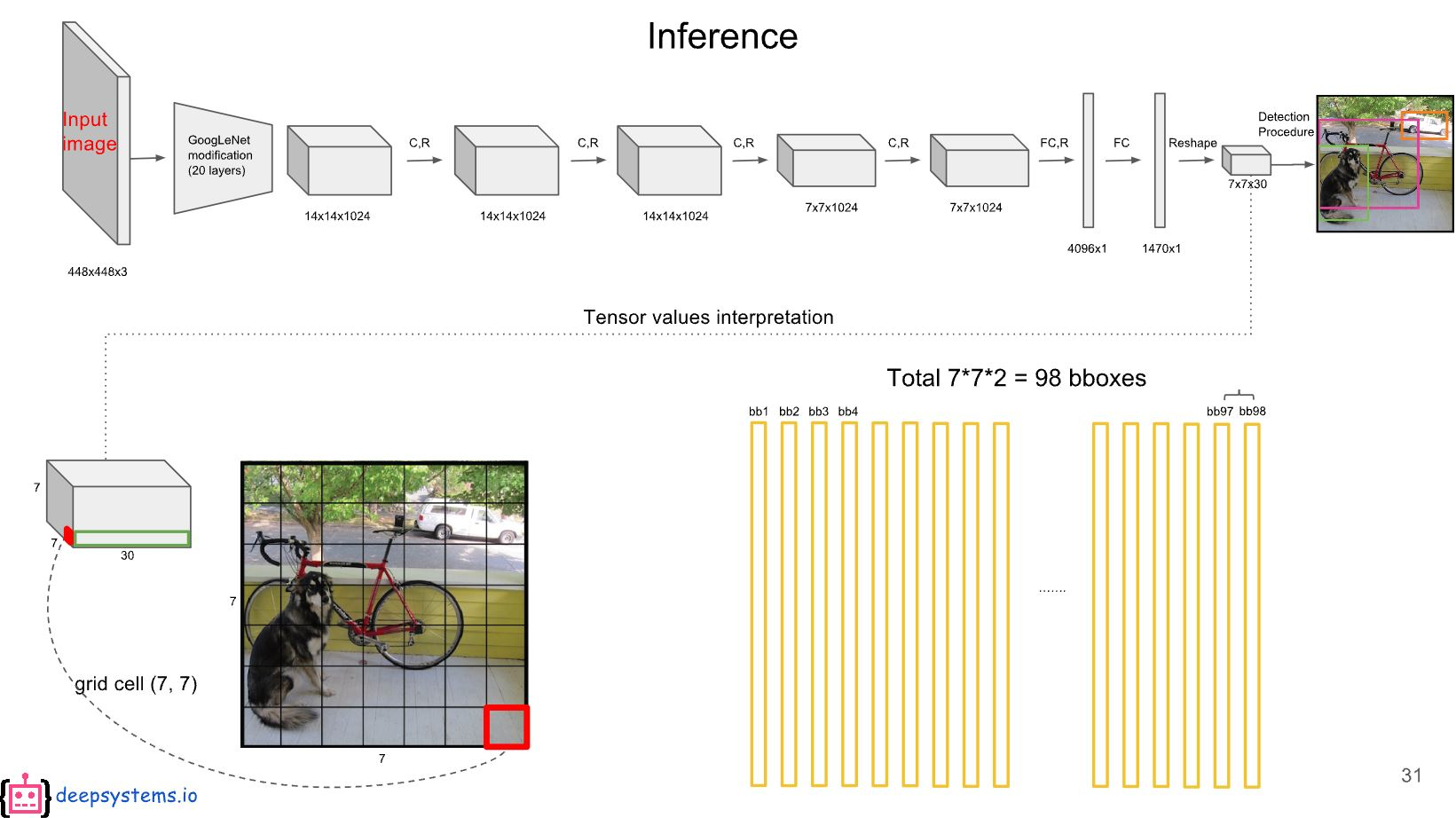
이 계산을 각 bounding box에 대해 하게되면 총 98개의 class specific confidence score를 얻을 수 있다.
이 98개의 class specific confidence score에 대해 각 20개의 클래스를 기준으로 non-maximum suppression 연산을 진행하여 탐지된 객체의 prediction 결과만을 얻어낸다.
