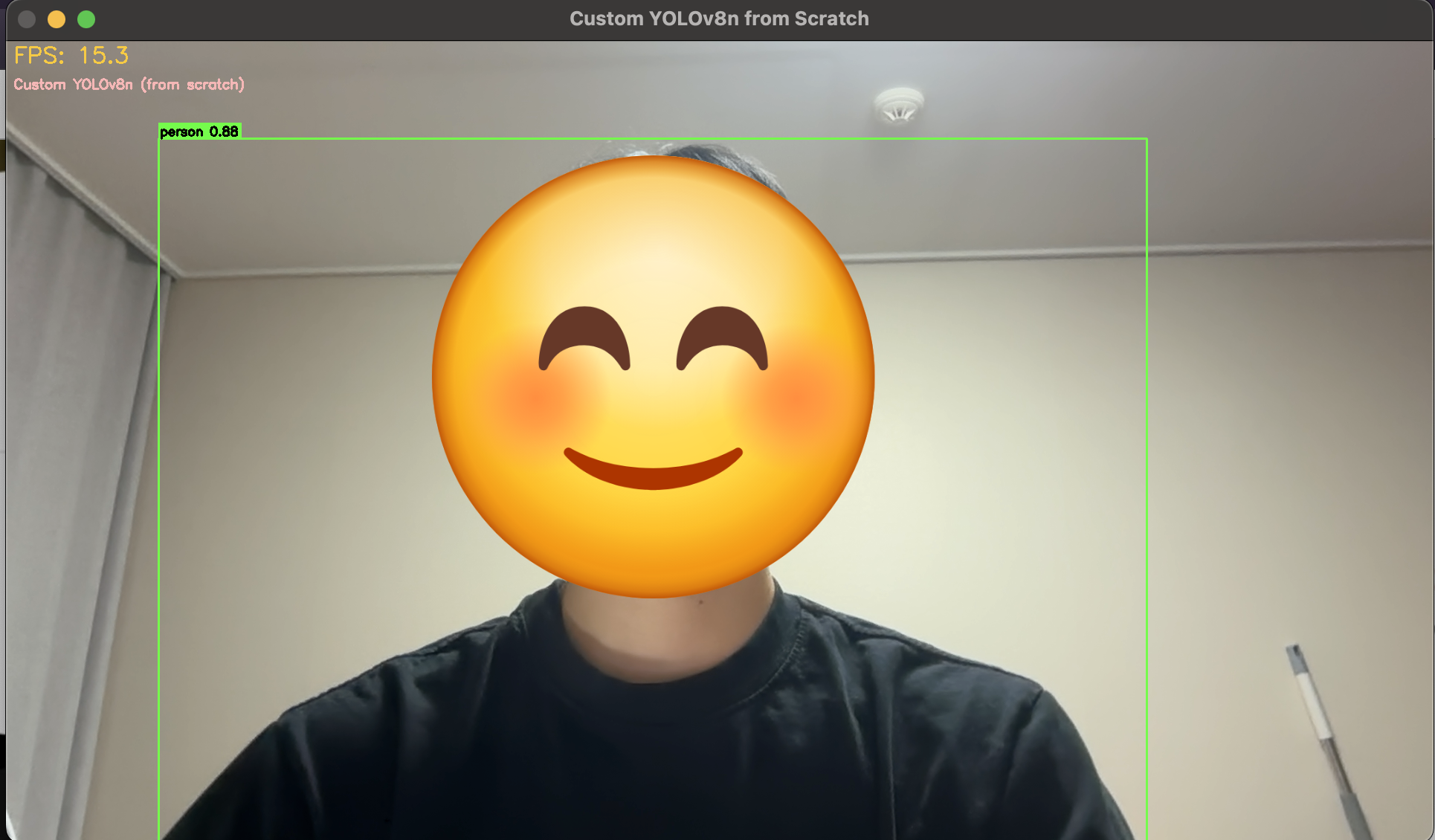
YOLO란?
YOLO는 컴퓨터 비전 분야에서 객체의 위치와 객체가 무엇인지를 빠르고 정확하게 찾아내는 인공지능 모델이다.
기존에는 객체가 있을 만한 위치를 먼저 찾고, 이후에 그 물체가 무엇인지 분류하는 두 단계를 거치는 2-Stage 방식이 주를 이루었다. 하지만 YOLO는 이미지 전체를 격자 단위로 단 한 번만 분석하여 객체의 위치와 클래스를 동시에 예측하는 1-Stage 방식을 채택함으로써, 실시간 비디오 분석이 가능할 정도로 처리 속도를 비약적으로 향상시킨 혁신적인 아키텍처이다.
YOLOv8
YOLO는 첫 등장 이후 전 세계 수많은 연구자들에 의해 발전해 왔다. 그 수많은 YOLO 버전 중에서도 2023년에 Ultralytics에서 발표한 YOLOv8은 속도와 정확도, 그리고 사용 편의성 면에서 현재 가장 완성도 높은 모델로 평가받고 있다.
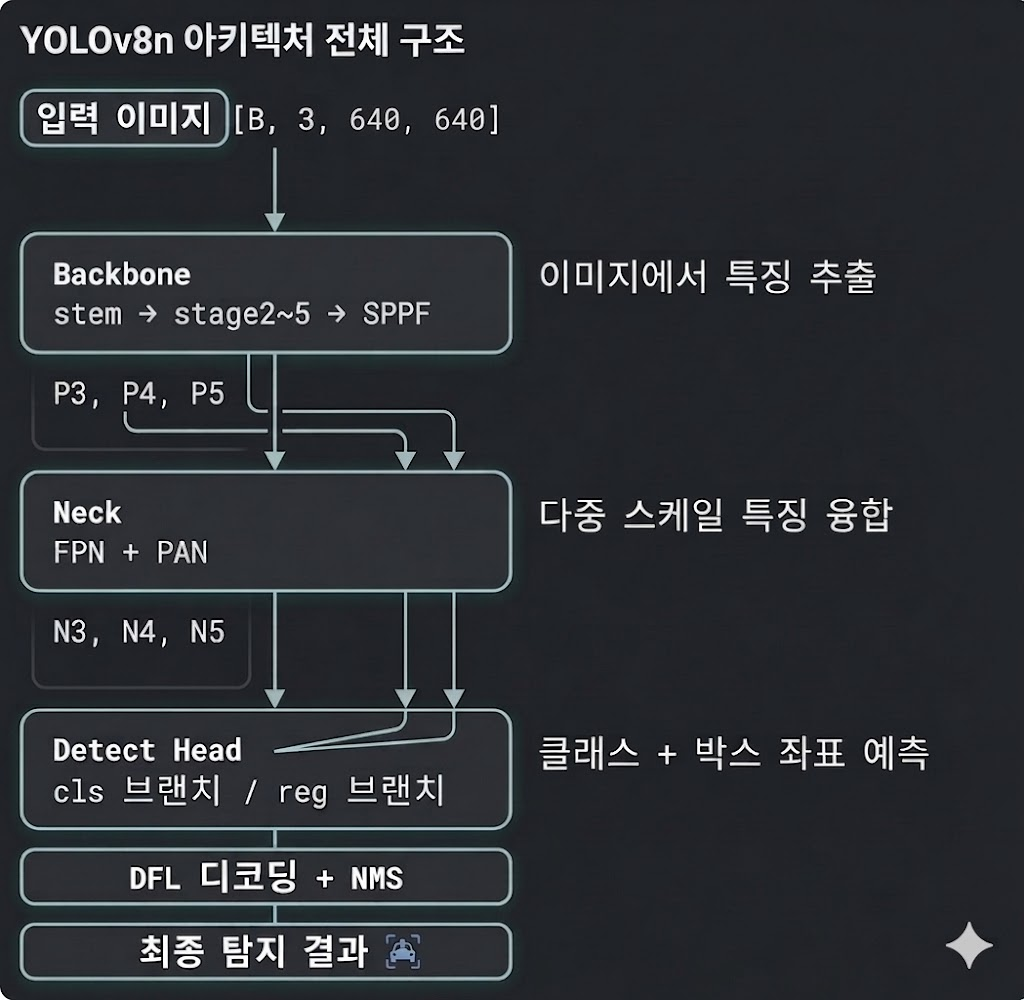
📌 YOLOv8 아키텍처 전체 구조
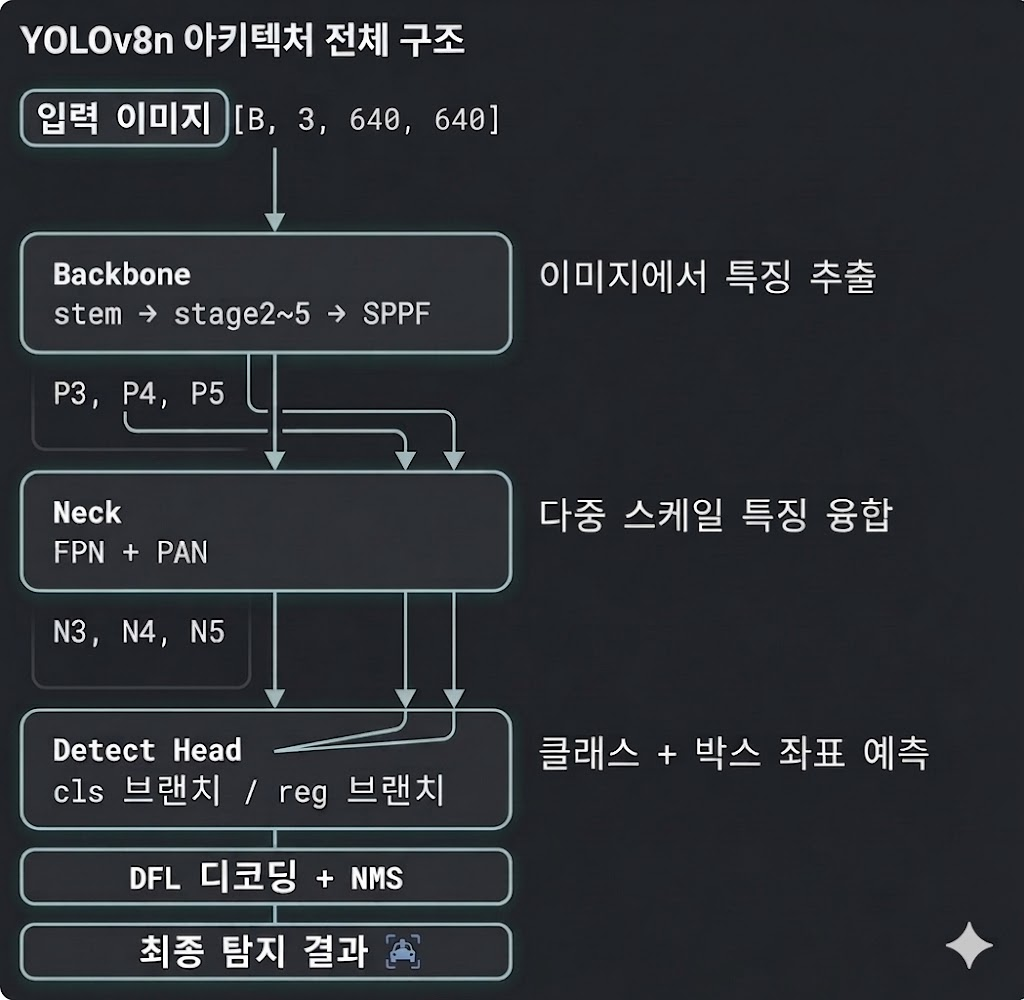
YOLO v8의 네트워크 구조는 Input image Backbone Neck Head 의 4단계 흐름을 거친다.
-
Input Image
모델이 처리할 입력 데이터의 형태이다.[B, 3, 640, 640]은 각각[배치 사이즈, 채널 수, 너비, 높이]를 의미한다. -
Backbone
이미지에서 시각적으로 의미 있는 특징을 추출한다.- 구조: stem 계층을 시작으로 여러 단계(Stage)를 거치며 특징 맵을 축소하고 차원을 압축한다. 마지막 단계에서는 SPPF 모듈을 통과하여 다양한 크기의 수용 영역(Receptive field) 정보를 빠르고 효율적으로 취합한다.
- 출력: 이 과정을 거쳐 다양한 해상도를 가진 특징 맵인 P3, P4, P5가 만들어지며, 이는 다음 단계인 넥(Neck)으로 전달된다.
-
넥 (Neck): 다중 스케일 특징 융합
-
역할: 백본에서 추출된 다양한 크기의 특징 맵들을 서로 융합하여, 크기가 아주 크거나 작은 객체들도 모두 잘 탐지할 수 있도록 정보의 품질을 높여준다.
-
기술: FPN과 PAN 구조를 결합해 사용한다. 이를 통해 상위 계층의 깊은 의미(Semantic) 정보와 하위 계층의 세밀한 위치(Spatial) 정보를 양방향으로 효과적으로 교환한다.
-
출력: 융합이 완료된 특징 맵인 N3, N4, N5가 최종 예측을 위해 헤드(Head)로 넘어간다.
-
-
헤드 (Detect Head): 클래스 및 박스 좌표 예측
-
역할: 넥에서 전달받은 융합 특징 맵을 바탕으로 최종적인 객체의 종류와 위치를 예측한다.
-
구조: YOLOv8은 분류 작업과 위치 추정 작업을 나누어 처리하는 Decoupled Head 방식을 채택했다.
-
cls 브랜치 (Classification): 해당 객체가 어떤 클래스인지(무엇인지) 예측한다.
-
reg 브랜치 (Regression): 객체가 정확히 어디에 있는지 바운딩 박스 좌표를 예측한다.
-
-
-
최종 후처리 (DFL 디코딩 + NMS)
-
헤드의 예측 결과들을 다듬어 깔끔한 최종 탐지 결과를 도출한다.
-
DFL(Distribution Focal Loss)을 통해 바운딩 박스의 경계값을 더 정밀하게 조정(디코딩)하고, NMS(Non-Maximum Suppression) 알고리즘을 적용하여 한 객체에 여러 개 겹쳐 있는 예측 박스들 중 가장 정확도 높은 하나만 남기고 중복을 제거한다.
-
구성
main.py # Ultralytics로 웹캠 실시간 탐지 (기준점)
yolov8_custom.py # YOLOv8n 아키텍처 직접 설계
convert_weights.py # Ultralytics 가중치 → 커스텀 모델 이식왜 직접 설계하는가
main.py의 핵심 코드는 단 2줄이다.
from ultralytics import YOLO
model = YOLO("yolov8n.pt")
results = model(frame)Ultralytics는 오픈소스이기 때문에 내부 코드를 열어볼 수 있다. 하지만 수십 개의 모델과 태스크를 지원하다 보니 추상화 레이어가 매우 많고, 특정 레이어 하나를 찾으려면 여러 파일을 타고 들어가야 한다.
라이브러리 구조 전체를 파악하지 않으면 다음 작업들이 어렵다.
- 채널 수 변경
- 레이어 수 조정
- 활성화 함수 교체
- 중간 레이어 출력 추출
- 클래스 수 변경 후 재학습
따라서 각 블록이들이 왜 존재하고 어떻게 연결되는지 이해하기 위해 아키텍처를 직접 설계해보았다.
1. Conv — 가장 기본 단위
필터(kernel)를 통해 이미지에 특정 패턴이 있는지 감지하는 연산
class Conv(nn.Module):
def __init__(self, in_c, out_c, k=1, s=1, p=None):
super().__init__()
p = k // 2 if p is None else p
self.conv = nn.Conv2d(in_c, out_c, k, s, p, bias=False)
self.bn = nn.BatchNorm2d(out_c)
self.act = nn.SiLU(inplace=True)
def forward(self, x):
return self.act(self.bn(self.conv(x)))3가지 연산을 순서대로 실행한다.
- Conv2d → 필터로 특징 추출 (학습되는 가중치)
- BatchNorm → 값 범위 정규화 (학습 안정화)
- SiLU → 비선형 활성화 (복잡한 패턴 학습)
파라미터 k(kernel size)에 따라 수용 영역이 달라진다.
- k=1 → 채널 수만 조절, 해상도 변화 없음
- k=3 → 3×3 범위의 특징 추출 (YOLOv8에서 가장 많이 사용)
2. C2f + Bottleneck — 다채로운 특징의 보존과 융합
단순한 Conv 레이어가 이미지에서 특징(Feature)을 뽑아내는 역할을 한다면, C2f 레이어는 추출한 특징을 다양한 깊이(Depth)와 시각으로 분석하여 정보의 손실 없이 보존하는 역할을 한다.
class Bottleneck(nn.Module):
"""
잔차 연결(Residual Connection)이 있는 병목 블록
3x3 Conv → 3x3 Conv, 입출력 채널이 같으면 입력을 더함
"""
def __init__(self, in_c, out_c, shortcut=True, e=0.5):
super().__init__()
hidden = int(out_c * e)
self.cv1 = Conv(in_c, hidden, 3, 1)
self.cv2 = Conv(hidden, out_c, 3, 1)
self.add = shortcut and (in_c == out_c)
def forward(self, x):
out = self.cv2(self.cv1(x))
return x + out if self.add else out
class C2f(nn.Module):
def __init__(self, in_c, out_c, n=1, shortcut=True, e=0.5):
super().__init__()
self.hidden = int(out_c * e)
self.cv1 = Conv(in_c, 2 * self.hidden, 1, 1)
self.cv2 = Conv((2 + n) * self.hidden, out_c, 1, 1)
self.bottlenecks = nn.ModuleList(
[Bottleneck(self.hidden, self.hidden, shortcut, e=1.0) for _ in range(n)]
)
def forward(self, x):
y = list(self.cv1(x).split(self.hidden, dim=1))
y.extend(m(y[-1]) for m in self.bottlenecks)
return self.cv2(torch.cat(y, dim=1))🤔 왜 단순 Conv가 아닌 C2f를 사용할까?
Conv만 사용하면 다운샘플링하며 소실되는 정보를 복구할 수 없기 때문에 C2f가 필요하다.
💡 다운샘플링 (Downsampling) : 이미지의 해상도(크기)를 줄이는 것
해상도가 줄어들면서 정보 손실이 발생할 수 있다.
반면 C2f를 사용하면 입력된 특징을 쪼개어 일부는 보존하고, 일부는 깊게 가공한 뒤 다시 합친다. 덕분에 얕은 수준의 특징과 깊은 수준의 특징이 동시에 다음 레이어로 전달된다.
만약 C2f 없이 모델을 구성한다면 큼직한 강아지는 잘 찾더라도, 멀리 있는 아주 작은 강아지는 세밀한 특징이 소실되어 탐지해 내지 못할 확률이 높다.
🔍 코드로 보는 C2f의 동작 흐름
강아지 이미지가 백본의 Stage 3을 통과한다고 가정해보자.
self.stage3 = nn.Sequential(
Conv(32, 64, 3, 2), # 다운샘플링 + 특징 추출
C2f(64, 64, n=2), # 추출한 특징을 다각도로 분석 및 융합
)C2f 내부에서는 입력된 텐서가 다음과 같은 흐름을 가진다.
- Split (분할): 입력을 두 갈래 A와 B로 나눈다.
- Bottleneck (심층 분석): 한쪽 갈래 B만 Bottleneck을 거치며 더 깊은 특징(C, D)을 추출한다.
- Concat (병합): 쪼개졌던 원본과 각 단계의 출력값을 모두 하나로 뭉친다.
Step 1. cv1 — 채널 확장 후 분기
입력 x [64ch]
↓ cv1 (1×1 Conv)
[128ch]
↓ split (절반으로 나누기)
A[64ch], B[64ch]
Step 2. Bottleneck 순차 통과
B[64ch] → Bottleneck1 → C[64ch]
C[64ch] → Bottleneck2 → D[64ch]
Step 3. 전체 concat → cv2
[A, B, C, D] → concat → [256ch]
↓ cv2 (1×1 Conv)
출력 [64ch]🛠 Bottleneck의 수용 영역(Receptive Field) 확장
Bottleneck 내부는 3x3 Conv 두 개로 구성되어 있다. 단순히 현재 픽셀 주변만 보는 것이 아니라, 층을 거칠수록 더 넓은 영역의 맥락을 파악하게 된다.
- Bottleneck 없음: 1×1 시야 (현재 픽셀만)
- Bottleneck 1개 통과: 5×5 영역의 맥락 파악
- Bottleneck 2개 통과: 9×9 영역의 맥락 파악
여기에 shortcut (잔차 연결)이 더해져, 넓은 영역을 분석한 결과물(out)에 원래 정보(x)를 더해줌으로써 기울기 소실(Gradient Vanishing)을 방지하고 학습을 안정적으로 만든다.
3. SPPF (Spatial Pyramid Pooling Fast)
SPPF는 Backbone의 가장 마지막 단계에 위치하여, 다양한 크기의 영역(Receptive Field)을 동시에 바라보고 정보를 취합하는 블록이다.
# Backbone stage5 마지막에 배치
self.stage5 = nn.Sequential(
Conv(128, 256, 3, 2),
C2f(256, 256, n=1),
SPPF(256, 256, k=5), # ← 핵심 모듈
)SPPF 내부 구조
class SPPF(nn.Module):
"""
동일한 크기(5x5)의 MaxPool을 직렬로 연결하여
연산량은 줄이면서 다양한 수용 영역(Receptive Field)을 확보하는 모듈
"""
def __init__(self, in_c, out_c, k=5):
super().__init__()
hidden = in_c // 2 # 예: 256 // 2 = 128
self.cv1 = Conv(in_c, hidden, 1, 1) # 256ch → 128ch (연산량 감소를 위해 채널 축소)
self.cv2 = Conv(hidden * 4, out_c, 1, 1) # 512ch → 256ch (Concat 후 다시 원본 채널로 복구)
self.pool = nn.MaxPool2d(k, stride=1, padding=k // 2) # 5×5 풀링
def forward(self, x):
x = self.cv1(x) # [B, 128, 13, 13]
# MaxPool을 꼬리에 꼬리를 물고 반복
p1 = self.pool(x) # MaxPool 1회 적용
p2 = self.pool(p1) # MaxPool 2회 누적
p3 = self.pool(p2) # MaxPool 3회 누적
# 원본과 모든 풀링 결과를 하나로 병합(Concat)
return self.cv2(torch.cat([x, p1, p2, p3], dim=1))
# ↑ ↑ ↑ ↑
# 수용 영역(시야): 1×1 5×5 9×9 13×13🤔 왜 MaxPool을 3번이나 반복할까?
가장 핵심적인 이유는 '하나의 풀링 레이어로 3가지 수용 영역 효과를 내기 위해서'이다.
앞서 Bottleneck에서 3x3 Conv를 겹쳐 시야를 넓혔던 것과 완벽히 동일한 원리이다.
같은 5×5 풀링(p=2, s=1)의 결과를 누적해서 적용하면 중심점은 유지된 채로 픽셀이 바라보는 영역만 넓어진다.
- x (원본): 1×1 수용 영역
- p1 = pool(x): 5×5 수용 영역
- p2 = pool(p1): 9×9 수용 영역
- p3 = pool(p2): 13×13 수용 영역
pooling을 누적하는 이유:
처음부터 5×5, 9×9, 13×13 풀링을 각각 따로 연산하는 것(기존 SPP 방식)보다, 5×5 풀링 하나를 직렬로 3번 거치는 것이 연산 속도가 훨씬 빠르기 때문이다.
결과적으로 Concat을 거치면, [B, 128, H, W] 크기의 특징 맵 4개가 합쳐져 [B, 512, H, W]가 되고, 마지막 1x1 Conv(cv2)를 통해 최종적으로 [B, 256, H, W] 크기로 깔끔하게 정리된다.
📍 왜 하필 Backbone의 가장 '끝'에 있을까?
네트워크가 깊어질수록 특징 맵의 해상도(가로세로 크기)는 줄어들고, 압축된 정보(채널)는 늘어난다.
Stem: [B, 3, 640, 640] (해상도 높음, 지엽적인 패턴)
Stage 3: [B, 64, 52, 52]
Stage 4: [B, 128, 26, 26]
Stage 5: [B, 256, 13, 13] (해상도 가장 낮음, 전역적 맥락 필요)
Backbone의 끝자락인 Stage 5는 이미지의 크기가 13x13으로 가장 작게 압축된 상태이다. 이 위치에서는 화면 전체를 아우르는 큰 객체의 전체적인 형태나 문맥(Context)을 파악해야 하므로 가장 넓은 수용 영역이 필요하다.
4. Backbone — 특징 추출기
Backbone은 앞서 우리가 직접 설계한 Conv, C2f, SPPF 블록들을 레고처럼 조립하여 만든 네트워크의 뼈이다. 입력된 원본 이미지에서 "무엇이 어디에 있는지"를 파악하기 위한 시각적 특징(Feature)을 단계별로 추출하는 것이 주된 역할이다.
import torch.nn as nn
class Backbone(nn.Module):
def __init__(self):
super().__init__()
# Stem: 첫 번째 다운샘플링 (초기 특징 추출)
self.stem = Conv(3, 16, 3, 2)
# Stage 2 (P2)
self.stage2 = nn.Sequential(
Conv(16, 32, 3, 2),
C2f(32, 32, n=1, shortcut=True),
)
# Stage 3 (P3) - stride 8 출력
self.stage3 = nn.Sequential(
Conv(32, 64, 3, 2),
C2f(64, 64, n=2, shortcut=True),
)
# Stage 4 (P4) - stride 16 출력
self.stage4 = nn.Sequential(
Conv(64, 128, 3, 2),
C2f(128, 128, n=2, shortcut=True),
)
# Stage 5 (P5) - stride 32 출력
self.stage5 = nn.Sequential(
Conv(128, 256, 3, 2),
C2f(256, 256, n=1, shortcut=True),
SPPF(256, 256, k=5), # Backbone의 끝자락
)
def forward(self, x):
x = self.stem(x)
x = self.stage2(x) # P2는 반환하지 않고 다음 스테이지로 넘김
p3 = self.stage3(x)
p4 = self.stage4(p3)
p5 = self.stage5(p4)
return p3, p4, p5 # 최종적으로 3개의 특징 맵을 반환🔍 단계별 텐서(Tensor)의 변화: 해상도는 ↓ 채널은 ↑
입력 이미지(640×640)가 Backbone의 각 Stage를 통과할 때마다 텐서의 형태는 다음과 같이 변한다.
원본: [B, 3, 640, 640]
↓
Stem: [B, 16, 208, 208] (해상도 1/2 감소)
↓
P2 : [B, 32, 104, 104] (해상도 1/2 감소)
↓
P3 : [B, 64, 52, 52] (해상도 1/2 감소) → 📌 첫 번째 출력
↓
P4 : [B, 128, 26, 26] (해상도 1/2 감소) → 📌 두 번째 출력
↓
P5 : [B, 256, 13, 13] (해상도 1/2 감소) → 📌 세 번째 출력각 Stage의 첫 번째 Conv 레이어는 해상도를 절반으로 줄여 연산량을 감소시킨다. 해상도가 줄어들면 픽셀 하나가 바라보는 영역이 넓어지는데, 이때 넓은 영역을 압축해서 보게 되므로 더 복잡하고 전역적인 의미 정보를 담기 위해 채널을 2배로 늘려주는 것이다.
🤔 왜 굳이 P3, P4, P5 세 가지를 따로 출력할까?
forward() 함수의 마지막 줄을 보면, 생성된 특징 맵 중 Stage 2의 결과물은 버리고 P3, P4, P5 세 가지만 반환한다.
그 이유는 하나의 이미지 안에서도 객체들의 크기가 천차만별이기 때문이다. 각 출력물은 서로 다른 크기의 객체를 탐지하는 역할을 전담한다.
-
P3 : 해상도가 높고 시야가 좁아, 작은 객체를 탐지하는 성능이 좋다.
- 해상도가 높은 P3은 테두리나 윤곽선 같은 Spatial Info가 살아있다.
-
P4 : 해상도와 시야가 중간 정도이며 중간 사이즈의 객체를 탐지하는 성능이 좋다.
-
P5 : 해상도가 낮고 시야가 넓어, 큰 객체를 탐지하는 성능이 좋다.
- 해상도가 낮게 압축된 P5는 "이게 어떤 물체인가"를 유추할 수 있는 Semantic Info를 담고 있다.
5. Neck (FPN + PAN) — 특징 융합의 마법
Neck은 Backbone이 출력한 P3, P4, P5를 받아 서로 다른 스케일의 특징을 융합하는 역할을 한다. Backbone이 "특징을 추출"한다면, Neck은 "추출된 특징들을 서로 교환하여 품질을 높이는" 단계다.
import torch
import torch.nn as nn
class Neck(nn.Module):
def __init__(self):
super().__init__()
# 1. FPN: Top-down (위 → 아래로 의미 정보 전달)
self.up1 = nn.Upsample(scale_factor=2, mode="nearest")
self.c2f_up1 = C2f(256 + 128, 128, n=1, shortcut=False) # P5(↑) + P4
self.up2 = nn.Upsample(scale_factor=2, mode="nearest")
self.c2f_up2 = C2f(128 + 64, 64, n=1, shortcut=False) # up1(↑) + P3
# 2. PAN: Bottom-up (아래 → 위로 위치 정보 전달)
self.down1 = Conv(64, 64, 3, 2)
self.c2f_down1 = C2f(64 + 128, 128, n=1, shortcut=False) # down1(↓) + up1
self.down2 = Conv(128, 128, 3, 2)
self.c2f_down2 = C2f(128 + 256, 256, n=1, shortcut=False) # down2(↓) + P5
def forward(self, p3, p4, p5):
# FPN (위에서 아래로)
x = self.c2f_up1(torch.cat([self.up1(p5), p4], dim=1))
n3 = self.c2f_up2(torch.cat([self.up2(x), p3], dim=1))
# PAN (아래서 위로)
n4 = self.c2f_down1(torch.cat([self.down1(n3), x], dim=1))
n5 = self.c2f_down2(torch.cat([self.down2(n4), p5], dim=1))
return n3, n4, n5 # 최종 융합된 3개의 특징 맵🤔 왜 굳이 특징을 융합해야 할까?
Backbone에서 넘어온 P3, P4, P5는 각자 잘하는 것이 명확히 다르다.
P5 [13×13]: 해상도가 낮게 압축되어 "여기에 버스가 있다"는 전역적인 의미(Semantic) 정보가 풍부하다. 하지만 압축이 심해 정확한 위치나 테두리는 뭉개져 있다.
P3 [52×52]: 해상도가 높아 "테두리가 정확히 여기 있다"는 세밀한 위치(Spatial) 정보가 강하다. 하지만 시야가 좁아 그게 버스인지, 트럭인지 확신하기 어렵다.
만약 이 둘을 분리된 채로 사용한다면, 모델은 "뭔지는 아는데 어디 있는지 모르는" 상태(P5)와 "어디 있는지는 아는데 뭔지 모르는" 상태(P3)에 빠지게 된다. 따라서 모든 층이 의미 정보와 위치 정보를 동시에 갖도록 섞어주는 작업이 필수적이다.
🌊 FPN (Top-down) — 깊은 의미 정보를 아래로 전파
FPN(Feature Pyramid Network)은 가장 깊은 층인 P5의 강력한 의미 정보를 해상도가 높은 P3 방향으로 흘려보내는 역할을 한다.
P5 [B, 256, 13, 13]
│
└─▶ (Upsample ×2) ─▶ [B, 256, 26, 26]
+ P4 [B, 128, 26, 26] ─▶ (Concat & C2f) ─▶ x [B, 128, 26, 26]
│
┌──────────────────────────────────────────────────────┘
└─▶ (Upsample ×2) ─▶ [B, 128, 52, 52]
+ P3 [B, 64, 52, 52] ─▶ (Concat & C2f) ─▶ 📌 n3-
Upsample을 통해 텐서의 해상도(가로세로)를 2배로 강제로 키운 뒤, 같은 크기를 가진 아래층의 특징 맵과 cat으로 이어 붙인다.
-
이 과정을 거치면 하위 계층(P3, P4)도 "아, 내가 보고 있는 선명한 윤곽선이 버스였구나!" 하고 의미를 깨닫게 된다.
🔥 PAN (Bottom-up) — 세밀한 위치 정보를 위로 전파
FPN만 사용하면 P3은 똑똑해지지만, 정작 P5는 여전히 정확한 위치 정보를 모른다. 이를 해결하기 위해 PAN(Path Aggregation Network)을 도입하여, 만들어진 n3의 정밀한 위치 정보를 다시 위쪽으로 올려보낸다.
📌 n3 [B, 64, 52, 52]
│
└─▶ (Conv stride=2) ─▶ [B, 64, 26, 26]
+ x [B, 128, 26, 26] ─▶ (Concat & C2f) ─▶ 📌 n4 [B, 128, 26, 26]
│
┌──────────────────────────────────────────────────────┘
└─▶ (Conv stride=2) ─▶ [B, 128, 13, 13]
+ P5 [B, 256, 13, 13] ─▶ (Concat & C2f) ─▶ 📌 n5-
Conv(stride=2)를 사용하여 해상도를 절반으로 깎아내리며(다운샘플링) 윗층과 cat으로 이어 붙인다.
-
이로써 상위 계층(P5)도 잃어버렸던 세밀한 위치 감각을 다시 되찾게 된다.
6. DetectHead — 최종 예측
DetectHead는 Neck이 융합해 준 다중 스케일 특징 맵(N3, N4, N5)을 받아, 최종적으로 "무엇이(cls) 어디에(reg) 있는지"를 예측하는 네트워크의 마지막 단계다.
YOLOv5까지는 클래스(종류)와 박스 좌표(위치)를 하나의 헤드에서 동시에 예측했지만, YOLOv8부터는 두 작업을 완전히 분리한 Decoupled Head(분리형 헤드) 방식을 채택하여 성능을 대폭 끌어올렸다.
import torch
import torch.nn as nn
class DetectHead(nn.Module):
REG_MAX = 16 # DFL에서 사용할 최대 픽셀 범위
def __init__(self, num_classes=80, in_channels=(64, 128, 256)):
super().__init__()
self.num_classes = num_classes
self.dfl = DFL(self.REG_MAX)
# 브랜치별 채널 수 설정
c2 = max(16, in_channels[0] // 4, self.REG_MAX * 4) # reg(좌표) 브랜치 채널 = 64
c3 = max(in_channels[0], min(num_classes, 100)) # cls(클래스) 브랜치 채널 = 80
self.cls_convs = nn.ModuleList() # 클래스 분류를 위한 Conv 계층
self.reg_convs = nn.ModuleList() # 박스 좌표를 위한 Conv 계층
self.cls_preds = nn.ModuleList() # 클래스 최종 예측 (1x1 Conv)
self.reg_preds = nn.ModuleList() # 박스 최종 예측 (1x1 Conv)
# N3(64), N4(128), N5(256) 각 스케일마다 독립적인 헤드 생성
for in_c in in_channels:
self.cls_convs.append(nn.Sequential(
Conv(in_c, c3, 3, 1),
Conv(c3, c3, 3, 1),
))
self.reg_convs.append(nn.Sequential(
Conv(in_c, c2, 3, 1),
Conv(c2, c2, 3, 1),
))
self.cls_preds.append(nn.Conv2d(c3, num_classes, 1)) # 80개 클래스 확률
self.reg_preds.append(nn.Conv2d(c2, 4 * self.REG_MAX, 1)) # 4개 방향 * 16개 분포🤔 왜 cls(분류)와 reg(회귀)를 분리할까?
두 작업이 바라보는 정보의 성격이 근본적으로 다르기 때문이다.
- cls 브랜치 (분류): "이게 강아지인가, 자동차인가?" 객체의 생김새, 질감 등 전반적인 의미적(Semantic) 특징에 집중해야 한다.
- reg 브랜치 (회귀): "박스의 왼쪽 경계가 정확히 몇 픽셀인가?" 외곽선, 모서리 등 타겟의 정밀한 위치(Spatial) 정보에 민감하게 반응해야 한다.
이처럼 지향점이 다른 두 작업을 하나의 헤드에서 처리하면 서로 간섭이 발생해 학습 효율이 떨어진다. 브랜치를 분리하면 각 네트워크가 자신의 역할에만 온전히 집중할 수 있어 탐지 정확도가 향상된다.
🔍 forward — 스케일별 독립적인 예측
각각의 스케일(N3, N4, N5)은 분리된 두 브랜치를 거친 후, 마지막에 다시 하나로 합쳐져(Concat) 출력된다.
7. DFL
DFL은 DetectHead의 reg 브랜치가 출력한 박스 좌표 분포를 실제 거리값으로 변환하는 디코더이다.
class DFL(nn.Module):
"""
Distribution Focal Loss 디코더
YOLOv8은 박스 좌표를 하나의 숫자 대신 '분포(distribution)'로 예측함
reg_max=16이면 각 좌표(l,t,r,b)에 대해 0~15 사이 분포를 softmax 후
가중 평균(expected value)으로 변환 → 더 정밀한 박스 예측 가능
수식: coord = sum(i * softmax(pred)[i]) for i in 0..reg_max-1
1x1 Conv 가중치를 [0,1,2,...,15]로 고정하여 기대값 계산
"""
def __init__(self, reg_max=16):
super().__init__()
self.reg_max = reg_max
self.conv = nn.Conv2d(reg_max, 1, 1, bias=False)
# 고정 가중치: [0, 1, 2, ..., reg_max-1]
self.conv.weight.data[:] = torch.arange(
reg_max, dtype=torch.float
).reshape(1, reg_max, 1, 1)
for p in self.conv.parameters():
p.requires_grad = False # 학습하지 않는 고정 파라미터
def forward(self, x):
# x: [B, 4*reg_max, num_anchors]
b, _, a = x.shape
# [B, 4, reg_max, A] → transpose → softmax → conv → [B, 4, A]
return self.conv(
x.view(b, 4, self.reg_max, a)
.transpose(2, 1) # [B, reg_max, 4, A]
.softmax(1) # reg_max 방향으로 확률 분포
).view(b, 4, a)8. NMS
def nms(preds, conf_thres=0.4, iou_thres=0.45):
"""
NMS: 같은 물체에 대한 중복 박스 제거
동작 원리:
1. 확신도 임계값 미만 제거
2. 확신도 높은 순으로 정렬
3. 가장 높은 박스와 IoU가 iou_thres 초과인 박스 제거
4. 남은 박스 중 다음으로 높은 것 선택 → 반복
"""
results = []
for pred in preds:
scores, cls_ids = pred[:, 4:].max(dim=-1)
mask = scores > conf_thres
boxes, scores, cls_ids = pred[:, :4][mask], scores[mask], cls_ids[mask]
if boxes.numel() == 0:
results.append(torch.zeros((0, 6), device=pred.device))
continue
# 클래스별로 NMS 분리 (같은 클래스끼리만 중복 제거)
offset = cls_ids.float().unsqueeze(1) * 10000
shifted = boxes + offset
keep = _nms_loop(shifted, scores, iou_thres)
results.append(torch.cat([
boxes[keep],
scores[keep].unsqueeze(1),
cls_ids[keep].float().unsqueeze(1),
], dim=1))
return results
def _nms_loop(boxes, scores, iou_thres):
"""IoU 기반 NMS 루프 (torchvision 의존성 없이 순수 구현)"""
x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
areas = (x2 - x1).clamp(0) * (y2 - y1).clamp(0)
order = scores.argsort(descending=True)
keep = []
while order.numel() > 0:
i = order[0].item()
keep.append(i)
if order.numel() == 1:
break
rest = order[1:]
# 교집합 영역 계산
ix1 = x1[rest].clamp(min=x1[i].item())
iy1 = y1[rest].clamp(min=y1[i].item())
ix2 = x2[rest].clamp(max=x2[i].item())
iy2 = y2[rest].clamp(max=y2[i].item())
inter = (ix2 - ix1).clamp(0) * (iy2 - iy1).clamp(0)
iou = inter / (areas[i] + areas[rest] - inter + 1e-7)
order = rest[iou <= iou_thres]
return keep