Intro.
지금은 코로나로 인해 그 좋아하는 찜질방을 가지 못하지만.. 찜질방을 가는 상상을 해 보자. 찜질방에 들어가서 (비유를 위해 이렇게 운영하는 찜질방이 있다고 하자) 카운터에 내 이름을 말한다. 그럼 직원이 신발장 열쇠를 건넨다. 나는 열쇠에 적힌 숫자에 해당하는 사물함에 내 신발을 넣어놓는다. 사우나도 하고, 소금 찜질도 하고, 맥반석 계란과 식혜도 야무지게 해치운 뒤에 집으로 돌아갈 채비를 한 나는 다시 열쇠를 가지고 사물함을 열어 내 신발을 꺼낸다.
내가 이해한 해시테이블은 이렇다. 비유가 적절한지는 모르겠지만.
해시테이블은 위와 같은 과정을 가진, 데이터를 저장하는 자료구조 중 하나이다. 해시테이블의 가장 강력한 점은 (잘 짜여 있다면!) 자료를 찾기 쉽다는 것이다. 만약 찜질방이 열쇠와 번호로 매겨진 사물함이 아니라 그냥 평범한 신발장을 갖추고 있었다면 나는 내 신발을 찾기 위해 신발장에 있는 모든 신발을 훑어봐야했을 것이다. 이것을 배열로 표현하면 다음과 같다.
const allShoes = [큐의신발, 폴의신발, 영의신발, 내신발, 은의신발]만약 내가 여기서 영의 신발을 찾아야 한다면 나는 모든 배열을 반복문으로 돌리면서 모든 요소를 확인해야 했을 것이다.
그러나 만약 열쇠 시스템이 도입된다면, 그리고 그 열쇠가 해당 배열의 인덱스를 가리킨다면! 즉 '영'의 인덱스가 2라면 나는 한 번에 바로 영의 신발을 찾을 수 있다.
let 영의신발 = allShoes[2] // 영의신발이렇게 key(영)와 value(영의 신발)를 저장하고 바로바로 꺼내쓸 수 있게 만든 것이 해시테이블이라는 자료구조다.
해시테이블이란?
1) 해시함수
그렇다면 key에 대한 인덱스는 어떻게 알 수 있을까? 해당 key를 index로 바꿔주는 것이 바로 해시함수hash function가 하는 역할이다. 이를 그림으로 표현하면 다음과 같다.
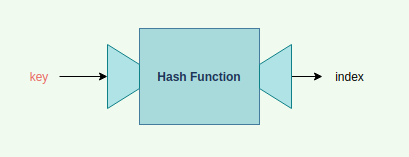
위의 비유에서 key는 나, 해시함수는 카운터의 직원이고, index는 열쇠라고 생각하면 쉬울 것 같다. '카운터 직원'(hash function)은 어떤 일련의 과정을 거쳐 '나'(key)를 숫자로 환원해 나에게 매칭하는 '열쇠'(index)를 건네준다.
어떤 과정을 거치는지는 어떤 해시함수를 쓰느냐에 따라 다르다. 각 문자에 숫자를 부여한 후 키의 문자를 모두 더하거나 곱하거나 찜쪄먹거나 암튼 이러저러한 계산을 해서 고유의 숫자값으로 만들기만 하면 된다. 이렇게 나온 index를 해시값(hash value)라고 부르며 이런 일련의 과정을 해싱hashing이라고 한다.
이제 해시함수의 사전적 정의를 보면 이해가 쉽지 않을까?
해시함수(hash function)란 데이터의 효율적 관리를 목적으로 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수입니다. 이 때 매핑 전 원래 데이터의 값을 키(key), 매핑 후 데이터의 값을 해시값(hash value), 매핑하는 과정 자체를 해싱(hashing)라고 합니다.
출처 : https://ratsgo.github.io/data%20structure&algorithm/2017/10/25/hash/
해시 함수가 되기 위해서는 여러 조건이 있지만 세 가지를 꼽자면 이렇다.
-
일관성이 있어야 한다.
만약 카운터 직원이 나에게 어제는 4번의 열쇠를 주고 오늘은 7번의 열쇠를 주면 안 된다. apple이라는 key를 넣었을 때 index가 5였다면, 이후 apple을 넣었을 때 똑같이 index값은 5여야 한다. -
서로 다른 단어에 대해 모두 다른 숫자가 나와야 한다
카운터 직원이 나에게 4번의 열쇠를 주고, 폴에게도 4번의 열쇠를 주었다면 그 사물함엔 누구의 신발이 담겨야 할까?아마 신발장을 쟁취하기 위한 피터지는 싸움이.. apple의 인덱스가 4였다면 banana의 인덱스는 4여서는 안 된다. (그러나 실제로 이 조건을 충족하는 해시함수를 만드는 것은 정말 어렵다고 한다. 이러한 상황을 해시 충돌이라고 하며 이에 대한 방안으로 여러 방법론이 나왔다.) -
해시함수는 배열이 얼마나 큰지 알고 있어야 하며, 유효한 인덱스만 반환하여야 한다
카운터 직원이 나에게 150번 열쇠를 주었는데 사물함의 번호가 100번까지밖에 없다면 나는 혼란과 혼돈에 빠질 것이다. 해시함수는 배열에 유효한 인덱스만 반환하도록 되어있다. 그래서 보통 해시함수는 요렇게 저렇게 계산한 특정 숫자를 배열의 크기만큼 나눈 나머지를 return한다. 그래야 배열의 크기에 유효한 인덱스가 나올 테니까.
2) 해시테이블
이렇게 나(key)는 해시함수를 거쳐서 열쇠(index)를 받았다. 이제는 내 신발(value)을 사물함에 넣을 차례다. 이 때 사물함을 해시테이블이라고 할 수 있다. 해시테이블은 실질적으로 데이터를 저장하는 공간이며, 인덱스가 가리키는 공간에 value를 저장한다. 이를 그림으로 표현하면 다음과 같다.
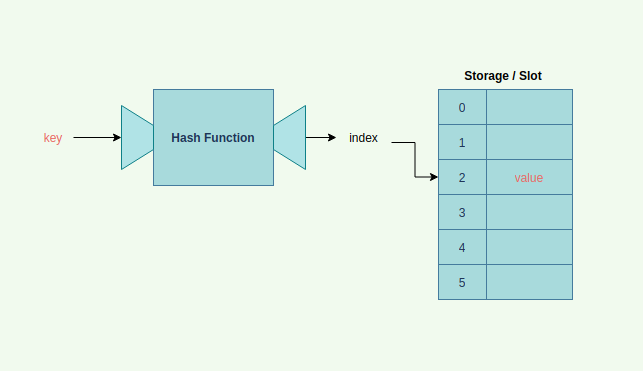
저렇게 저장하는 공간을 hash table, 혹은 storage, slot이라고도 부른다고 한다. 나는 내 신발을 2번 사물함에 얌전히 놓아두었다. 그러면 나중에 내가 다시 찜질방에 올 때 카운터 직원은 똑같이 나에게 2번키를 줄 것이고 나는 내 신발을 2번 신발장에서 꺼내갈 수 있다.
해시 충돌 collision
좋은 해시 함수를 만드는 건 어렵다. 모든 key마다 각각 다른 index를 부여해주면 좋겠지만 그렇지 못한 경우가 많다. 시스템의 한계로 카운터 직원이 나에게도 4번 열쇠를, 큐에게도 4번 열쇠를 주었다면 4번 사물함은 누가 사용해야 할까? 이러한 상황을 해시 충돌이라고 한다.
내가 4번 사물함에 내 신발을 넣어놓고 사우나에서 세월아 네월아 하는 동안 누군가가 4번 열쇠를 받아 내 신발을 휙 버려두고 거기에 자신의 신발을 놓는다면..? 나는 내 신발을 잃어버린거고 해시테이블은 데이터를 잃어버리게 되는 것이다.
이를 해결하기 위해 여러 방법들이 있지만 그 중 한 가지는 해시 충돌이 일어날 경우 해당 테이블 안에 배열이나 연결리스트와 같은 또 다른 자료구조를 사용하는 것이다. 사물함 비유라면 사물함 안에 선반이나 칸막이를 설치한다고 보면 되겠다. 같은 4번 사물함을 써도 내 신발과 큐의 신발이 공존할 수 있게 말이다. 이를 그림으로 표현하면 다음과 같다.
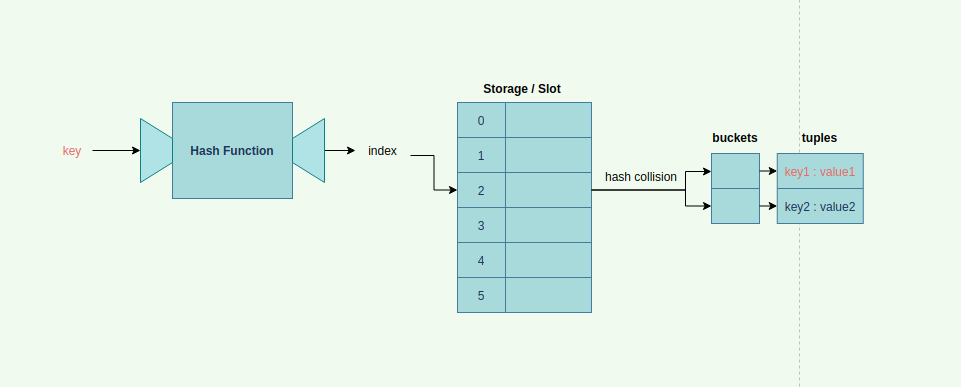
(이제부턴 내가 잘못 이해했을 수도 있다. 틀린 것이 있다면 지적 바란다.) 사물함 한 칸의 공간 자체를 bucket이라고 부른다. 그리고 이제 나는 bucket 안에 칸막이를 설치해서 내 이름표와 내 신발을 넣어둔다. 여기서 내 이름표와 신발을 넣는 칸막이 공간을 tuple이라고 부른다. 신발 뿐 아니라 이름표를 넣는 이유는, 4번 사물함이 더 이상 나만의 것이 아니기 때문이다. 나 혼자 4번 사물함을 차지할 때에는 내 이름을 써놓을 필요가 없었지만 이제는 내 이름표를 적어놓아야 내 신발을 찾을 수 있게 된다. 따라서 tuple에는 key와 value가 모두 저장되어야 한다.
bucket과 tuple을 표현하는 방법은 여러가지가 있겠지만 구분을 위해서 각각 배열과 객체로 표현해보면 다음과 같다.
const storage = {
0: [], // 0~5는 storage의 index이다.
1: [], // 0, 1, 3번 bucket은 비어있다.
2: [{key1: value2}, {key2: value2}], // 여기서 []은 bucket이고 {}는 tuple이다.
3: [],
4: [{key3: value3}], // tuple에는 key와 value가 모두 들어간다.
5: [{key4: value4}, {key5: value5}, {key6: value6}],
}
이제 나는 나의 신발을 찾을 때 카운터에서 4번 열쇠를 받은 후 4번 사물함에서 모든 칸막이를 확인해 내 이름표를 확인한 후 내 신발을 꺼낼 수 있다. 아래 시간복잡도에서 이어 말하겠지만 이렇게 해시 충돌이 일어날 때 해시테이블의 시간복잡도는 점점 커지게 된다.
해시테이블 리사이징 (resizing)
코로나가 종식되었다!(내 희망사항이다ㅎㅎ) 이제 너도나도 찜질방을 향해 달려간다. 찜질방은 유래없는 손님들로 북적이게 되고 신발을 넣을 수 있는 공간은 점점 사라지고 있다. 찜질방 운영자라면 이러한 상황에 대처하기 위해 신발장을 추가로 구비하게 될 것이다. 이러한 상황을 리사이징resizing이라고 한다. 일반적으로 해시테이블의 사용률이 75%를 넘는 순간 해시테이블은 더 큰 storage로 리사이징하게 된다.
그런데 이렇게 리사이징할 때 발생하는 문제는 이것이다. 신발장을 추가로 구매하는 것이 아니라 더 큰 신발장으로 교체하는 게 더 정확한 비유일 것이다. 기존에 있던 신발장 안에 있는 신발장을 새 신발장 안에 재배치해야하는 번거로움이 생긴다. 특히 배열의 크기가 달라짐에 따라 해시함수의 계산 결과도 달라지게 되고, 이것은 모든 key에 부여된 기존의 index 역시 달라진다는 것을 뜻한다. 내 기존 신발장의 번호가 4번이었다면, 신발장 리모델링 이후 새로운 숫자 178번을 받을 수도 있다는 뜻이다. 그렇게 모든 기존의 신발이 새로운 신발장에 제자리를 찾아가는 번거로운 과정을 거쳐야한다.
해시테이블의 Big O (시간복잡도)
배열, 혹은 연결리스트와 비교했을 때 해시테이블이 가진 강력한 장점은 이것이다.
인덱스를 매개로 했기 때문에 데이터의 추가, 삭제, 탐색이 모두 O(1)이다. 엄청 빠르다!
그러나 해시충돌이 있다면 최악의 경우 bucket의 모든 tuple을 탐색해야 하기 때문에 시간복잡도는 O(n)까지 늘어난다.
또 리사이즈를 하는 순간에도 모든 데이터를 재배치하기 때문에 O(n)이 걸린다.
- 데이터의 삽입, 삭제 : 평균적으로 O(1), 최악의 경우 O(n)
- 데이터의 탐색 : 평균적으로 O(1), 최악의 경우 O(n)
- 리사이징 : O(n)
해시테이블 구현을 위한 의사코드
임의의 해시함수 hashFunction()과, 크기를 제한한 배열 limitedArray가 이미 구현되어 있다고 가정한다.
class HashTable {
constructor() {
this._size = 0;
this._limit = 8;
this._storage = LimitedArray(this._limit); // limit만큼 크기를 제한한 배열을 만드는 함수
}
// 주어진 키와 값을 저장하는 메소드
insert(key, value) {
// key를 index로 바꿔주는 해시함수
const index = hashFunction(key, this._limit);
// 빈 bucket과 빈 tuple을 선언한다.
// 만약
// this._storage의 index 안에 들어있는 값이 있다면 버켓은 기존의 버켓을 불러온다.
// 1. key와 value를 tuple에 넣고 tuple을 bucket 안에 넣는다.
// 2. bucket을 this._storage의 index 값에 넣는다.
// 3. this._size에 1을 추가한다.
// 만약
// 해시테이블의 사용률이 75% 이상이면 해시테이블의 크기를 2배로 리사이징한다.
}
// 주어진 키에 해당하는 값을 반환하고 없다면 undefined를 반환하는 메소드
retrieve(key) {
const index = hashFunction(key, this._limit);
// 만약
// this._storage의 index 안에 들어있는 값이 없다면 undefined를 리턴한다.
// 아니면
// this._storage의 index 안에 들어있는 bucket 중
// 해당 key가 들어있는 tuple을 찾아 value를 리턴한다.
}
// 주어진 키에 해당하는 값을 삭제하고 값을 반환하며, 없다면 undefined를 반환하는 메소드
remove(key) {
const index = hashFunction(key, this._limit);
// 만약
// this._storage의 index 안에 들어있는 값이 없다면 undefined를 리턴한다.
// 아니면
// 1. this._storage의 index 안에 들어있는 bucket 중
// 해당 key가 들어있는 tuple을 찾아 value를 변수에 담아 저장한다.
// 2. 해당 tuple을 삭제한다.
// 3. tuple을 삭제한 bucket을 this._storage의 index 값에 넣는다.
// 4. this._size에서 1을 뺀다.
// 만약
// 해시테이블의 사용률이 25% 이하라면 해시테이블의 크기를 1/2배로 리사이징한다.
// 저장한 value를 리턴한다.
}
// 해시 테이블의 스토리지 배열을 newLimit으로 리사이징하는 함수
_resize(newLimit) {
// 1. this._size를 0으로 초기화한다.
// 2. this._limit을 newLimit으로 재할당한다.
// 3. this._storage를 변수에 담아 복사한다.
// 4. this._storage에 newLimit만큼 제한된 배열을 생성하여 재할당한다.
// 5. 원 storage에 반복문을 걸어 해당 index안의 bucket안의 tuple을 돌면서
// 각 key와 value를 추출해 다시 insert() 메소드에 넣는다.
}
}
미리 성지순례하고 갑니다 ^^