
Tokenization
이전 포스트에서도 다룬 적 있는 개념이지만, 다시 설명하자면 tokenization은 딥러닝에 기반한 자연어 처리에 있어서 가장 첫번째로 수행하는 단계로 주어진 텍스트를 특정 단위로 쪼개는 과정을 의미한다.
특정 단위에 따라서 다양한 단위의 tokenization이 있다.
Text data
기본적으로 text data는 각 time step에서 주어지는 단어나 문자로 이루어진 sequence data이다. 이러한 data를 어떠한 단위로 쪼개 나가는 과정을 tokenization이라고 한다.
The devil is in the details
위와 같은 text 데이터가 있다고 하자, 이는 크게 3가지 방식으로 tokenization이 가능하다.
- Word level
띄어쓰기 단위로 token화를 진행한다.
"The" "devil" "is" "in" "the" "details"- Character level
글자 단위로 token화를 진행한다. 여기서 글자엔 띄어쓰기도 포함되어있다.
"T" "h" "e" "d" "e" "v" "i" "l" " " "i" "s" " " "i" "n" " " "t" "h" "e" " " "d" "e" "t" "a" "i" "l" "s"- Subword level
Word와 Character사이의 단계로 token화를 진행한다.
"The" " " "de" "vil" " " "is" " " "in" " " "the" " ' "de" "tail" "s"이렇게 tokenization을 거친 단위들을 token이라고 하고 trian set에 대한 token들은 vocabulary에 정의된다.
vocabulary는 일종의 token 집합이다. vocabulary 내 token들은 각각 하나의 category로 one hot vector로 표현이 가능하다.
Word level Tokenization
일반적으로 단어 단위 tokenization은 띄어쓰기 단위로 단어를 구분한다. 하지만, 특정언어(ex.한국어)에서는 띄어쓰기 단위 내에 서로다른 의미의 두 단어가 들어있는 경우도 존재한다. 예를 들어,
나는 밥을 먹었다.
의 경우, 밥과 을은 서로 다른 단어에 해당한다. 한국어에서는 아래와 같이 형태소(최소 의미단위)를 기준으로 단어를 구분하기도 한다.
'나' '는' '' '밥' '을' '' '먹' '었다'위의 token은 각 timestep에서의 입력이 되는 것이다. 마찬가지로 띄어쓰기에 해당하는 공백도 하나의 단어로 볼 수 있다.
이때, 학습단계에서 구축한 vocabulary에 존재하지 않은 새로운 단어가 추론단계에서 등장하게 된다면 문제가 생길 수 있다.
단어 단위의 tokenization의 경우 inference에서 생기는 모르는 단어에 대해서, 모두 일괄 Unknown 토큰으로 처리하게 된다.
마치 vocabulary에 있는 하나의 category처럼 처리하게 되는데, 서로 다른 의미를 가질 수도 있던 단어들을 사전에 없었단 이유로 모두 Unknown으로 처리하면 모델의 성능이 저하될 수 있다. 이러한 unkown token을 Out-of-vocabulary(OOV)라고도 부른다.
Character level tokenization
token을 철자 단위로 구분하는 것을 의미한다. 해당 tokenization은 서로 다른 언어라고 해도 겹치는 철자가 존재할 수 있는데 (라틴어,영어) 이때 token으로 처리가 가능하다는 장점이 있다. 또한, 한 언어의 모든 철자를 vocabulary에 포함시키기 때문에 단어단위의 tokenization에서 발생한 OOV 문제는 발생하지 않게된다.
반대로 단점도 존재한다. 언어모델에 입력되는 text들을 철자단위로 넣기 때문에, 단어 단위로 tokenization할때보다 입력 sequence의 길이가 너무 길어질 수 있다. 이는, GPU 리소스 등 다양한 이유로 모델이 긴 문장을 입력받을 수 없는 이유가 된다.
또한, token들은 각각 어느정도 유의미해야하는데, 철자단위로 tokenization을 진행해버리면 token 각각의 의미를 상실하게 된다.
Subword level tokenization
token을 철자와 단어사이의 단위로 구분하는 것이다. 기존 characater level tokenization 보다 모델에 입력되는 token의 평균 갯수가 매우 적고, subword tokenization을 통해 생성된 vocabulary에는 단어단위 뿐 아니라 철자도 포함되어 있어 OOV 문제가 없다는 것을 알 수 있다.
여기서 궁금한점이 생길 수 있다. 과연... 철자와 단어사이의 단위가...뭘까? 그렇다 subword tokenization은 사실 방법론에 따라서 그 단위를 다양하게 결정할 수 있다. 대표적인 방법론인 Byte-pair-Encoding(BPE)에 대해서 알아보자
BPE
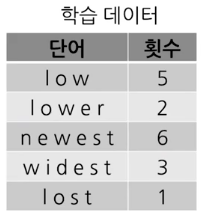
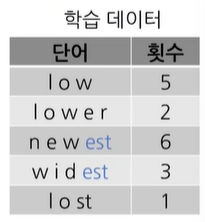
주어진 학습데이터에서의 단어 빈도가 위와 같다고 가정해보자.
1. BPE의 첫 단계는 바로 철자 단위의 vocabulary를 만드는 것이다.
이 예시의 경우 철자 단위 단어목록은 아래와 같다.
l,o,w,e,r,n,w,s,t,i,d2. 가장 빈도수가 높은 단어 pair를 token으로 추가한다
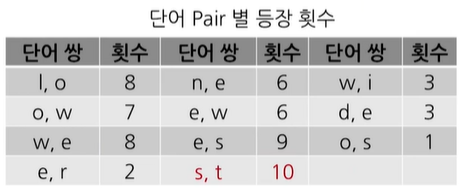
학습 데이터에서 우선 두글자를 한 pair로 묶어 단어쌍으로 보며 빈도수를 비교해본다. 예를 들어, (l,o)라는 단어쌍은 low라는 단어가 5번, lower이라는 단어가 2번, lost라는 단어가 1번 등장했기 때문에 총 8번의 등장 횟수가 있음을 알 수 있다.
가장 빈도수가 높은 단어 Pair는 (s,t)인 것을 알 수 있다. 이러한 단어쌍을 vocabulary에 subword로 추가하게 된다. 가장 높은 빈도수를 가지는 pair를 추가하는 이유는, 자주 train set에서 등장한만큼 어느정도 의미를 가질 것이라고 판단할 수 있기 때문이다.
단어목록은 아래와 같아진다.
l,o,w,e,r,n,w,s,t,i,d,stst가 추가 되었다. 또한, 학습 데이터에서 높은 빈도수를 가지는 pair를 결합하면 아래와 같아진다.
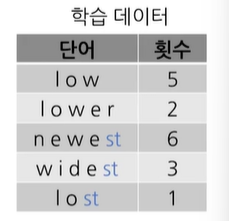
이제 2번의 과정을 다시 반복하게 된다.
2(loop). 가장 빈도수가 높은 단어 pair를 token으로 추가한다
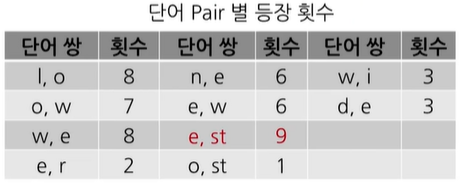
이제 st를 하나의 단어로 보고 마찬가지로 빈도수가 높은 pair를 고르게 되면, (e,st) pair를 고를 수 있다. 이를 vocabulary에 추가해보면
l,o,w,e,r,n,w,s,t,i,d,st,est와 같아진다. 그리고, 학습데이터도
위와 같이 볼 수 있어진다.
이제, 같은 방법으로 빈도수가 가장 높은 pair를 미리 설정한 vocabulary의 size에 도달할 때까지 반복해서 vocabulary를 구축하는 것이 BPE 알고리즘이다.
- 입력 텍스트에 대한 사전 정의 후 토큰화
우리는 글자 한개의 token보다, 여러개로 조합된 token이 더 유의미할 것이라는 가정하에 BPE 알고리즘을 진행했다.
따라서, 사전을 정의한 이후, 단어를 tokenization할 때, 입력 된 string을 왼쪽에서부터 차례로 vocab에 정의된 가장 긴 문자열을 token으로 매칭하게 된다. 예를 들어, 사전내 등록된 단어의 목록이 아래와 같을때,
l,o,w,e,r,n,w,s,t,i,d,st,est,lo,low입력 예시 newest를 token화 한다면,
n,e,w,est로 하게 되는 것이다.
조금 더 자세히 내부 동작과정을 살펴보면, newest라는 단어가 입력되었을때, vocab에 존재하는 가장 큰 단위의 subword부터 확인을 하게된다.
현재는 3이 가장 큰 subword이기 때문에, new라는 token이 vocab에 존재하는지 확인한다.
없는 것을 확인하고, 2의 크기인 ne를 vocab에서 찾는다. 마찬가지로 없는것을 확인하고, n으로 token화를 진행하는 것이다.
