
Word Embedding
우리가 사용하는 언어를 이해할 수 있지만, 컴퓨터의 입장에서는 단어를 단어 그대로로 받아들일 수 없다. 따라서, 단어나 토큰을 컴퓨터가 이해할 수 있는 벡터로 표현하는 방법을 적용해야한다. 이를 word embedding이라고 한다. 대표적인 방법인 Word2Vec에 대해서 알아보자.
One-Hot Encoding
먼저, vocabulary에 저장된 token들을 각각 하나의 category로 판단하여 인코딩하는 방법에 대해서 알아보자.
one hot encoding 기법에서는 vocabulary에 존재하는 token의 수만큼의 차원을 생성한 후, 각 차원이 하나의 token을 표현하도록 하는 기법이다.
쉽게, 혈액형에 대한 예시를 살펴보자. 혈액형은 A형,B형,AB형,O형으로 존재한다. 4개를 one hot encoding하면,
위와 같이 각 차원별로 한개의 혈액형을 표현하게끔 할 수 있다.
문제점
one hot encoding을 실제 문장을 토큰화한 결과에 적용을 하게되면, 문제점이 존재한다. 바로 단어간의 의미를 표현하기 힘들다는 것이다.
먼저, 서로 다른 단어간의 유사도를 계산하는 방법으로, L2 distance와 Dot-product similarity를 생각해보자. 각각 단어들간의 거리와 내적 유사도를 의미한다.
다음과 같은 vocabulary가 존재한다고 가정해보자
['나' '는' '밥' '을' '먹' '었다']이 vocabulary에 one hot encoding을 적용하게 되면,
- 나=
- 는=
- 밥=
- 을=
- 먹=
- 었다=
이렇게 표현 가능하다. "먹-"과 "-었다" 는 서로 실질 형태소와 의존 형태소에 해당하므로, 둘의 관계는 "먹-"과 "는" 보다는 더 밀접하다는 것을 우리는 알고있다.
두 비교군의 내적 유사도와 유클리드 거리를 계산해보자
- "먹","었다" 내적 유사도/ 유클리드 거리
- "먹","는" 내적 유사도/ 유클리드 거리
one hot encoding으로 표현하게 되면, 서로 다른 단어 사이의 관계에 대한 정보를 표현하는 데 한계가 존재한다. 참고로, one hot encoding의 결과 서로 다른 단어들의 내적 유사도는 항상 0이고, 유클리드 거리는 항상 이다.
Sparse representation
one hot encoding을 하게 되면, 각 단어의 차원에 해당하는 값은 1이지만 나머지는 모두 0이라는 것은 자명하다.
컴퓨터에 이러한 encoding 결과를 입력하게 되면, 1을 제외한 나머지 0 값은 사실상 낭비되기 마련이다. 따라서, one hot vector를 그대로 저장하는 것이 아니라, sparse representation을 통해서 data를 어느정도 압축 시킨 후에 저장한다.
이는, one hot encoding이 아닌 다른 encoding 방법에도 적용이 가능한 사례이다. 아래와 같은 encoding 결과가 있다고 가정하자
apple=
현재, 2번째 차원과 6번째 차원에만 0이 아닌 값이 저장된 것을 확인할 수 있다. 이를 그대로 저장하는 것이 아닌 sparse representation으로 표현하면
- sparse representation
apple=
로 표현이 가능하다. 이는, 0이 아닌 값이 존재하는 차원의 index 값과, 실제 해당 값으로 표현하는 것으로, 6개의 수를 저장하는 방법과 다르게, 4개의 수만으로 같은 표현을 저장할 수 있게 해준다.
Distributed Vector 표현
이전 one hot encoding과 다르게, 단어간의 유사도와 거리를 계산할 수 있기 위해서, 단어를 여러 차원에 걸쳐 0이 아닌 값인 형태로 표현하는 것을 의미한다. 그리고 이를 Word embedding이라고 한다.
Dense vector라고도 불리며, 해당 기법은 sparse vector와 정반대되는 것을 알 수 있다. 모든 차원에 0이 아닌 값이 존재하기 때문에, 관계가 밀접한 단어면, L2거리가 작고, 유사도가 큰값. 관계가 무관한 단어면, L2거리가 크고, 유사도가 작은 값으로 계산 가능해진다.
대표적인 Dense vector로 표현하는 방법론에 Word2Vec이 존재하고 이는 주변 단어의 정보들을 이용해 단어 벡터를 표현하는 방법이다.
살면서, 누군가와 대화를 할때 대화의 일부를 놓치거나 하는 경우가 존재한다. 그럴때, 앞뒤 문맥을 통해서 상대가 어떤 말을 한 것인지 파악하는 것이 가능한데, 이를 수학적으로 표현한 것이다.
Word2Vec
Word2Vec의 핵심 아이디어는 내가 표현하려는 특정 단어의 주변에 나타나는 다른 단어의 확률분포를 모델링 하는 것이다. 즉, "주변에 어떤 단어가 나타나는지에 대한 확률분포가 이 단어의 뜻을 표현하는 것이다." 라는 아이디어이다.
이에 두가지 방법이 존재한다. 한 단어에 대해 vector로 표현할때,
1. 그 단어의 주변 단어로부터 해당 단어를 예측하는 방법 (Continuous Bag of Words)
2. 주어진 단어를 가지고, 주변에 어떤 단어가 나타나는지를 예측하는 방법 (Skip-gram)
이 있다. skip-gram이 많이 쓰이기 때문에 skip-gram에 대해서 정리해보았다.
Skip-gram
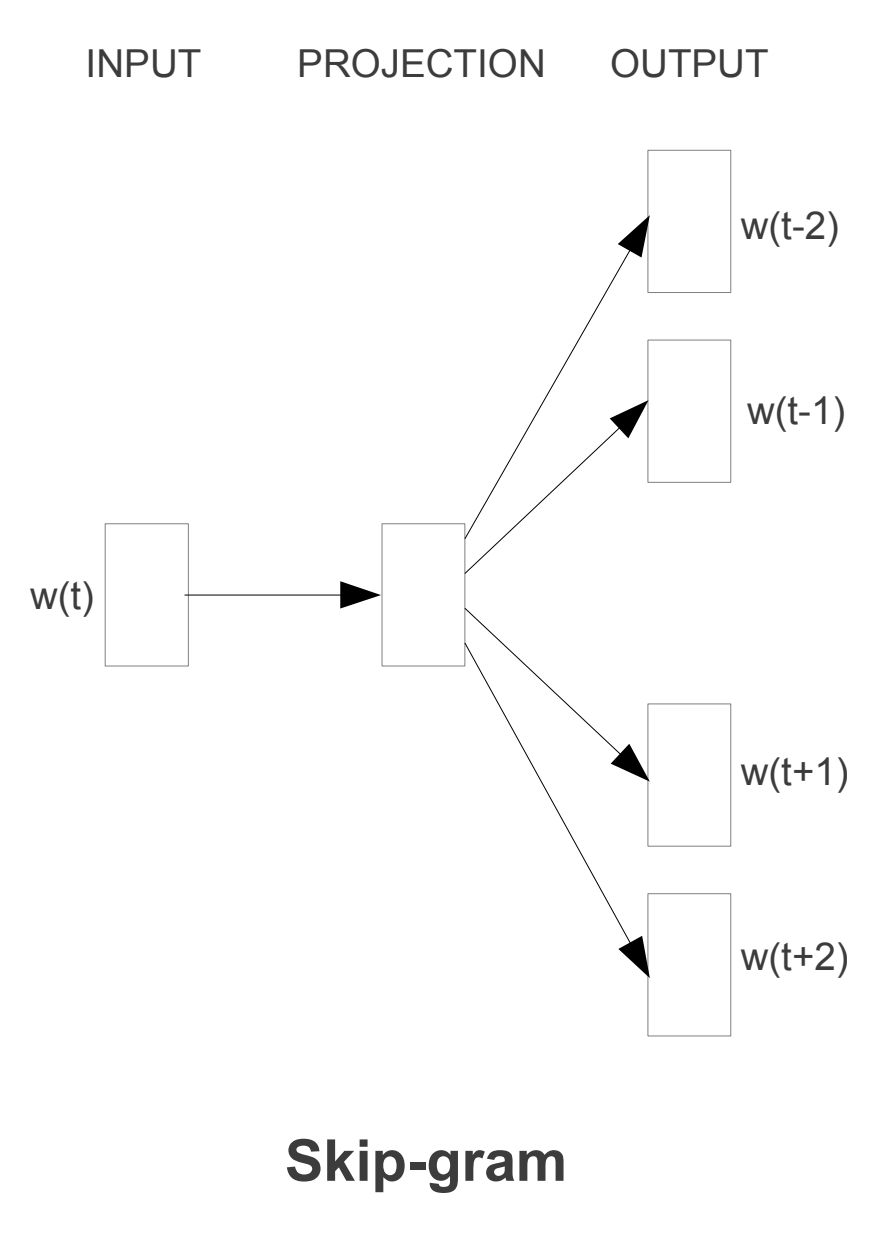 위의 그림과 같이 입력 단어에 대해서, output으로 주변 단어에 대해 예측을 진행하는 방법이다.
위의 그림과 같이 입력 단어에 대해서, output으로 주변 단어에 대해 예측을 진행하는 방법이다.
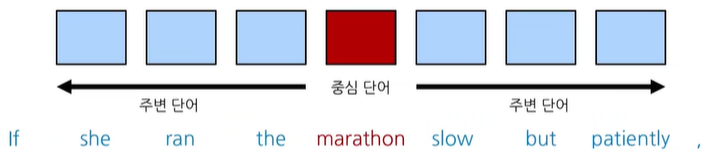
skip gram 방법에선, 중심단어를 기준으로 앞뒤로 몇개의 단어를 예측할 것인지를 정해야 하는데, 이 size를 window size라고 한다.
위의 그림은 window size가 3인 경우, 중심 단어와 주변 단어에 해당하는 단어들을 나타낸 그림이다. window size만큼 앞뒤로 범위를 포함하고 있는 것을 확인할 수 있다. 총 6개의 단어를 예측하는 것이다.
이제 Word2Vec이 이뤄지는 과정을 자세하게 다뤄보자
Word2Vec 학습과정
먼저, 간단한 문장과 해당 문장에 대한 tokenization 결과를 바탕으로 만든 vocabulary를 예시로 만들어보자
- 예시 문장
I study NLP
- Vocabulary
{"NLP", "study", "I"}
이제, skip-gram 방식으로, 중심단어와 주변단어 쌍을 정해보자. 여기서는 짧은 문장이기 때문에, window size를 1로 설정했다.
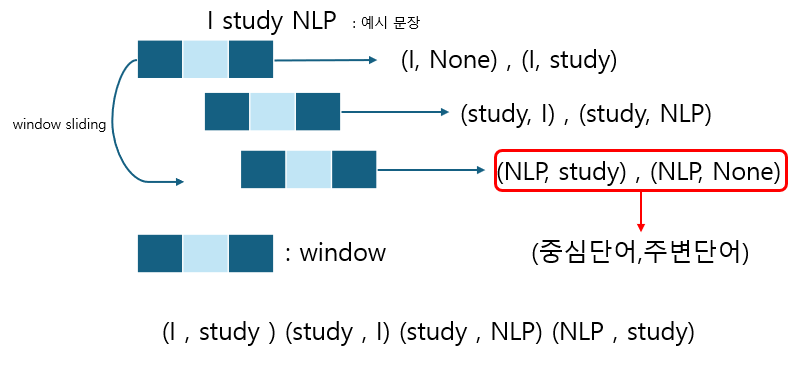
예시 문장에 window size가 1인 window를 sliding하며, 중심단어와 주변단어를 input과 output으로 설정하면 위와 같이, None인 값을 제외해 4개 쌍을 얻을 수 있다.
Word2Vec 구조
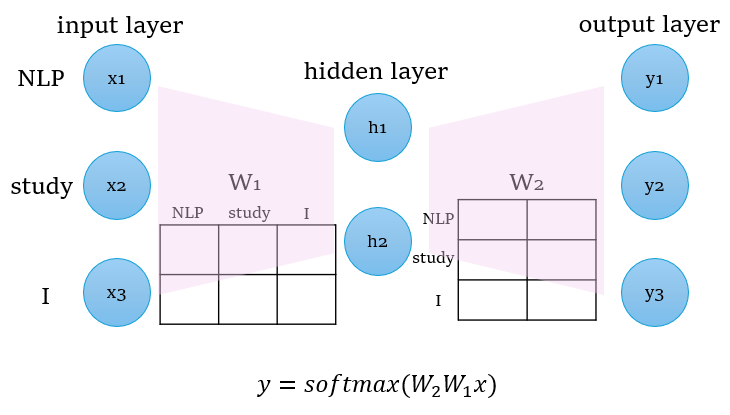
Word2Vec은 기본적으로, 한개의 hidden layer를 가지고 있는 구조이다. 그리고, hidden layer의 dimension은 실제 vocabulary에 존재하는 token의 수보다 작은 크기로 이는 token을 one hot encoding한 것보다 더 압축시킨 표현을 하겠다는 의미를 가진다.
자세히 구조를 살펴보면, hidden layer에 활성화함수를 넣지 않고 있는 것을 알 수 있다. 사실 활성화함수를 넣을 필요가 없는게, 원래 input으로 들어가는 단어들은 one hot encoding인 상태로 입력되게 된다. 이를 차원을 축소시키고 다시 확장 시키는 과정을 거치기 때문에 따로 활성화함수를 사용하지 않는다. 이제 Word2Vec 모델에 이전에 준비했던 입력값을 넣어보자.
model 동작과정
먼저, 이전에 구했던 4개의 쌍중에서, (study , NLP)의 in/output 쌍을 선택하였다. study라는 단어는 input x에서 one hot encoding 된 값으로 입력되게 된다. 따라서, []의 값이 으로 입력된다.
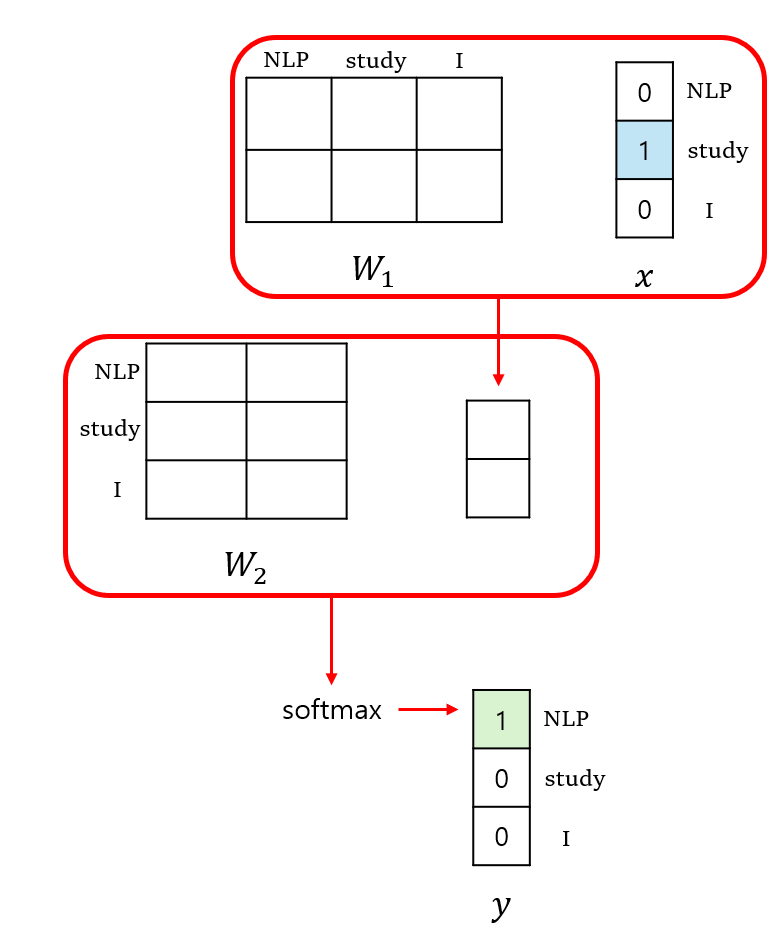
위와 같은 순서로 계산이 진행된다. one hot vector와 의 곱을 통한 선형변환이 이뤄지고 그 결과값을 로 한번 더 선형변환하여, 마지막으로 모든 출력값의 합이 1인 확률분포로 softmax함수를 통해 만들어낸다.
최종적으로 output으로 나오는 vector가 현재 예시 기준으로, NLP 라는 단어가 나오게끔 loss function을 정의해 학습하는 과정이 이루어진다. 여기서, 행렬과 행렬의 연산과정을 좀 더 자세히 알아보자
과 의 행렬 곱
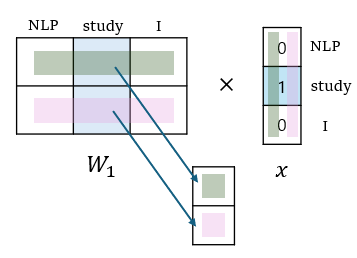
행렬과 input one hot vector의 곱을 진행하게 되면, one hot vector이기 때문에 위의 그림처럼, 행렬에서 각 row마다 실제 input 값에 해당하는 위치의 값이 결과로 저장되게 된다. 어차피 나머지는 행렬 곱 과정에서 0이 곱해져 없어지기 때문이다.
결론적으로, 과 의 곱은, input word에 해당하는 column을 에서 선택하는 것과 같아진다. 만약에, input one hot vector가 NLP를 가리키는 이었다면, 곱의 결과는 행렬의 첫번째 column 값이 될 것이다.
와 의 행렬 곱
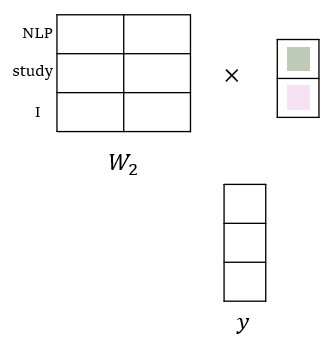
행렬과 이전에 얻은 column의 곱 결과는 vocabulary에 존재하는 token 갯수 만큼의 행을 가지는 vector가 나와야한다. 또한, 내의 각각의 row vector와 hidden layer output vector간의 내적이 계산 되어야 하기 때문에, 는 hidden layer의 차원 수 만큼의 열을 가져야 한다.
결론적으로, 행렬은, (vocabulary내 token의 수, hidden dimension) 의 크기를 가지는 행렬이어야 한다.
행렬곱의 직관적인 의미
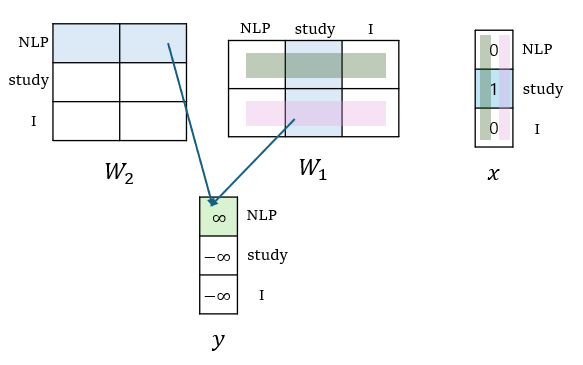
직관적으로 바라보면, 와 의 행렬 곱은 사실, input token에 해당하는 에서의 column값과 output token에 해당하는 에서의 row값의 내적 결과가 제일 커야 한다는 것을 알 수 있다. 이는, 중심단어(input)를 기준으로 해서 주변 단어(output)가 밀접한 연관성을 가져야한다(내적값이 커야한다) 라는 것을 표현하기도 한다.
같은 입력단어임에도 다른 출력단어인 쌍의 경우
현재 study라는 입력단어는 NLP 뿐 아니라 1이라는 출력단어도 쌍으로 가지고 있다. 이미지 분류로 생각해보면, 같은 이미지를 강아지라고도 분류하려고 학습하고, 또 어떤 경우에는 고양이로 분류하려고 학습하는 모순적인 상황처럼 느껴질 수 있다. 하지만 결론적으로는, 하나의 input,output 쌍에 대해서 gradient descent 알고리즘을 적용해 일정량 만큼 학습한다고 볼 수 있다.
특정한 입출력 쌍이 전체 학습 데이터에서 빈번하게 등장했을때, 두개의 단어에 대해서 빈도수를 기반으로 하여 내적값이 더 커지게 된다.
다른 입력단어가 같은 출력단어를 가지는 경우
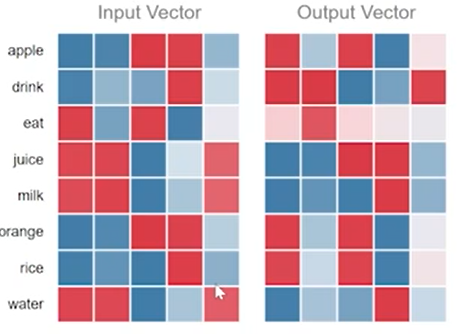
반대로 서로 다른 단어가 같은 출력단어를 가지게 되는 경우에 대해서 생각해보자. input,output의 쌍으로
milk|drink , water|drink , juice|drink가 있는 상황에 Word2Vec의 학습 결과 각 과 matrix의 가중치값은 위와같이 나타났다. 이는 같은 output vector() drink에 대해서 juice,milk,water가 유사한 embedding값을 가지며 이들은 모두 내적값을 최대화 하기 위해서 계산된 값임을 알 수 있다.
결론적으로, 서로 다른 중심단어가 비슷한 주변 단어를 가지게 되는경우 둘이 비슷한 embedding 값을 가지게 된다는 것을 의미한다.
matrix, word embedding을 도와주다
또한, 에서 주어지는 word embedding 결과 벡터를 사용하는 경우에서는 transfer learning 관점에서도 이해할 수 있다. word embedding의 결과물을 입력으로 사용하여 주어진 문장에 대한 sentiment analysis를 수행하는 경우를 생각해보자.
사실 실제로 모델 입력을 진행할때, token에 대한 one hot encoding 값을 넣어주게 된다. 하지만, 감정분석모델의 input 직전 앞단에서 layer를 추가해 token들을 embedding한 값을 입력하게 되는 것이다.
즉, Word2Vec model을 사전에 학습 시켜두고, 뒤쪽 layer를 내가 수행하고 싶은 taks에 맞는 모델로 붙여서 생각할 수 있다.
Embedding 결과는..?
앞서 말한것 처럼 matrix만 사용하는 경우도 있고 각각의 matrix간의 평균을 낸 값으로 word embedding vector를 사용하기도 하고, 보다 더 많이 사용되는 경우는 만 사용하는 것이라고 한다.
Word2Vec의 속성
단어 벡터는 단어들 간의 관계를 나타내게 된다. 간단한 예시로 아래 상황을 생각해보자
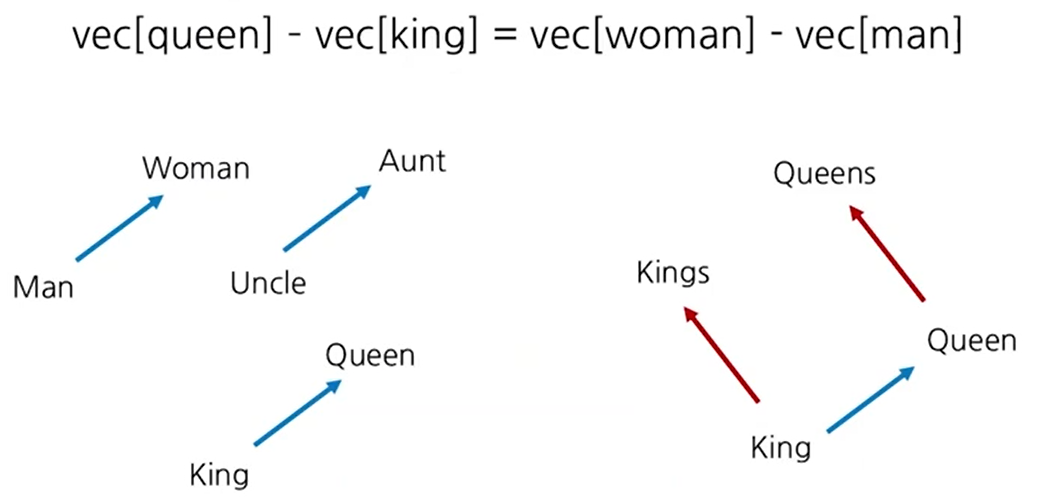
단지 성별만 다른 위의 경우를 생각해볼 수 있다. 모두다 왕,왕비 또는 여성,남성으로 성별만 다른 경우인 예시이다. 좌변의 결과는 King에서부터 Queen을 가리키는 vector를 나타내게 된다. 좌측에 있는 세가지 vector모두, 각각 남성→여성을 가리키는 vector 관계를 표현하는 것으로 알 수 있다.
여기서 우변에 존재하는 man을 의미하는 vector를 이항하게 되면, woman을 나타내는 vector 표현이 되는 것이다. vec[queen]-vec[king]은 king으로부터 queen으로 향하는 vector가 되고 이는 남성에서 동일한 의미를 가지는 여성을 나타내는 단어로 변환되는 관계라는 것을 알 수 있고, 실제로 vec[man]을 더하게 되면, vec[woman]을 가리키는 것을 알 수 있다.
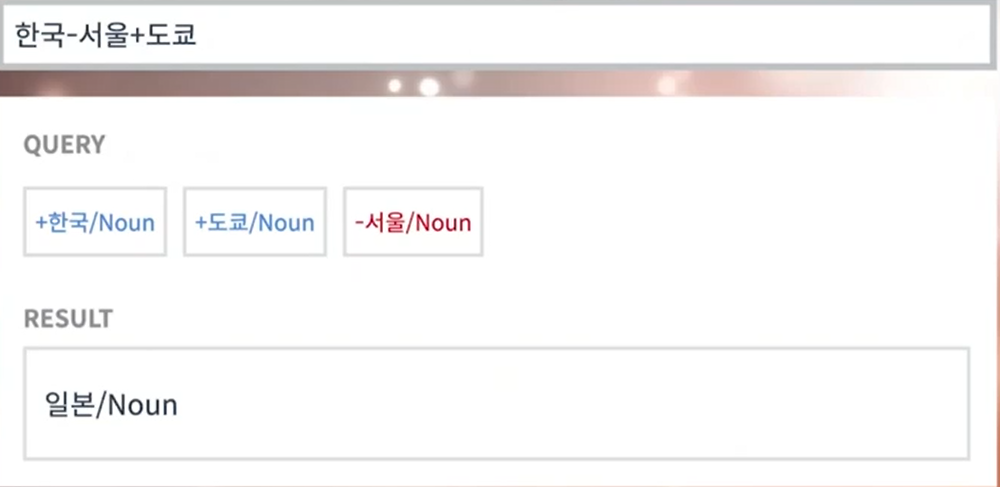
마지막으로, 실제 한글에 대해 Word2Vec을 적용하게 되면, 한국-서울 vector는 즉 "어떤 나라의 수도→나라" 의 관계를 나타내고 여기에 일본의 수도인 도쿄를 더해주면 결과값으로 일본에 해당하는 word embedding vector가 나온것을 알 수 있다.
Reference
