
DQN에 들어가기 앞서, 강화학습에 대해서 간략하게 알아보자. 강화학습은 머신러닝의 분야 중 하나에 속한다. 먼저 머신러닝은 기계가 획득된 데이터로 스스로 학습해 인간과 유사한 사고를 하게 되는 것을 의미한다.
그 중에서 강화학습은, 기계가 스스로 어떠한 행동을 하고 그에 따라 받는 보상값을 바탕으로 다음 행동 선택에서, 더 좋은 선택을 할 수 있게끔 스스로 학습하는 것이다.
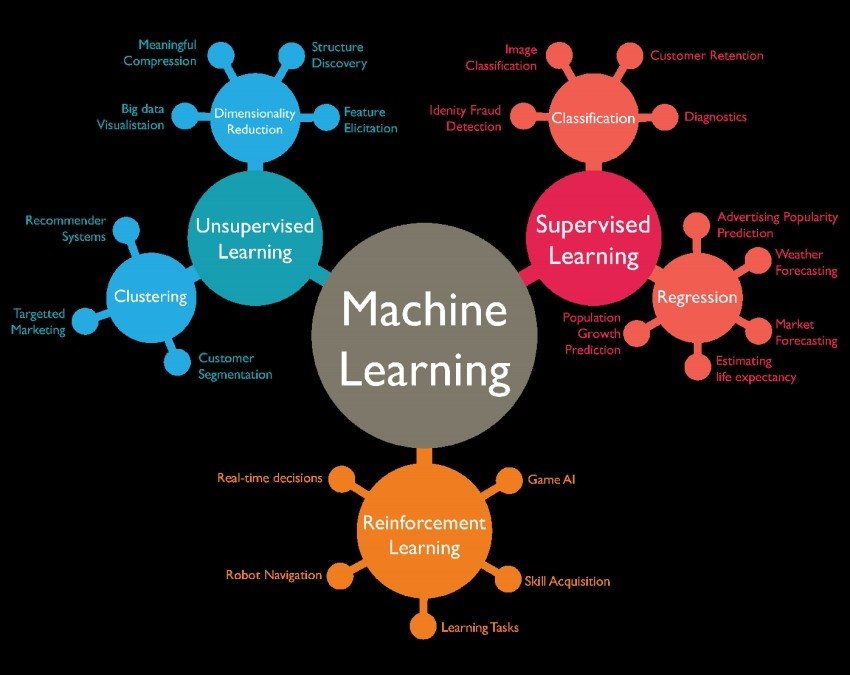
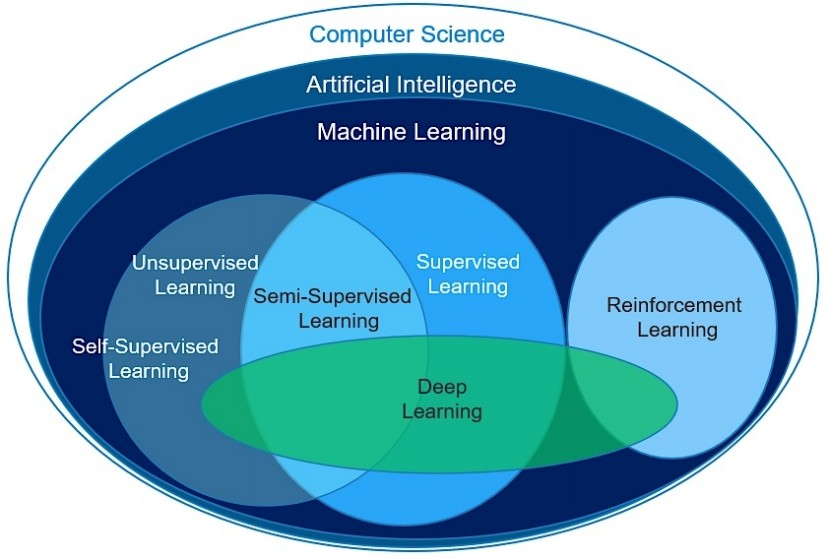
AI, 머신러닝, 딥러닝은 점점 세분화된 개념이라고 볼 수 있다.
AI: 컴퓨터 및 기계가 인간의 사고를 따라하는 것으로 인간의 지능과 관련된 학습,문제해결, 패턴인식과 같은 문제를 해결하는데 주력하는 컴퓨터 공학 분야이다.
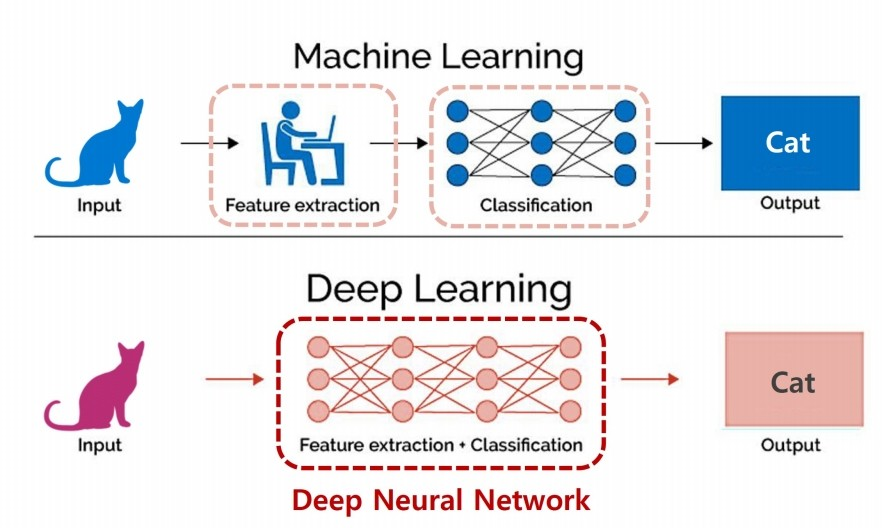
ML: 획득된 데이터를 가지고 기계가 스스로 학습하여 인간과 유사한 사고를 하게되는 것으로 인간이 정한 어떤 규칙을 따르는게 아닌, data로부터 스스로 학습한 것을 토대로 패턴인식과 같은 문제를 해결하는 것이다.
DL: ML을 기반으로, 인간의 뉴런구조를 모방해 network를 형성한다는 것이다. ML과의 차이점으로 특징점 추출에 대해서도 인간이 수행하는 것이 아닌 기계가 직접 수행할 수 있도록 하는 것으로, 거의 모델 학습의 모든 과정에서 기계가 스스로 학습하는 것이다.
Reinforcement learning은 agent가 동적인 환경과 상호작용한다. agent는 동적인 환경에서 어떠한 goal을 달성하기 위해 action을 수행하고, 목표에 도달할 때까지 agent는 학습해나가며 더 좋은 action을 선택해 나가는 것이다. Reinforcement learning의 대표적인 예시는 바로 Q-learning이다.
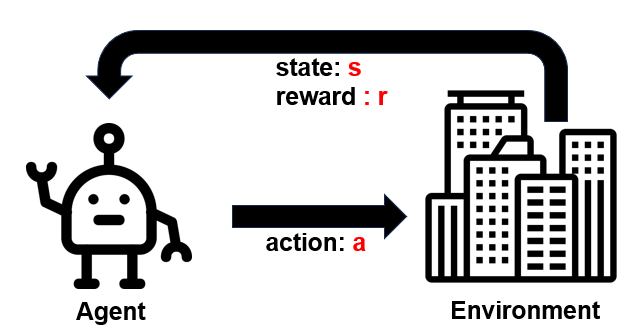
Agent : action하는 주체
Environment : agent가 놓인 환경
State : 환경 및 agent의 상태
Action : goal에 도달하기 위해 agent가 행함
Reward : action에 대한 평가
🚧주의🚧 Environment가 직접 agent에 reward를 주는 건 아님.
🚧주의🚧 Agent는 Environment가 어떤식으로 작동하는지 모름.
간단한 예시로 cartpole이 있다. 바퀴가 달린 cart에 막대기를 세워두고, 앞뒤로 움직이며균형을 맞추는 것을 강화학습으로 구현하는 것이다.
Environment : cart위에 pole(막대기)가 세워져 있는 상태
State : pole(막대기)이 수직으로 서있는 상태를 기준으로 쓰러진 각도
Action : cart를 좌우로 이동
Reward : pole의 기울어진 각도가 0에 가까우면 (거의 쓰러지지 않음) 좋은 보상을 줌
Goal : 최대한 긴 시간동안 pole을 세워두는 것
Cart의 이동은 환경과의 interaction(상호작용)이고 이로인해서, pole은 cart의 이동방향과 반대로 쓰러지려하거나, 세워지거나 할 것이다. (실제론 복잡한 환경) 이 때, environment가 직접 reward를 cart에 주진 않는다.
→ reward를 높게 받기 위해서 cart가 action을 취하면 오랜 시간 동안 pole을 균형있게 세우는 데에 성공할 것이다.이처럼 max expected reward를 받기 위해서 action을 수행한다.
이와 같이 agent가 환경과 상호작용하며, 최대의 reward를 받게끔 학습하는 것이 전체적인 강화학습의 메커니즘이다.
