
tokenization 및 vocabulary 생성과정을 정규표현식과 함께 raw하게 직접 구현해보자.
Tokenizer 구현
정규표현식을 사용해서 tokenizer를 구현해보자. 아래의 규칙을 지켜서 token화를 진행해보자.
- 공백으로 구분한다.
- . , ! ? 문장부호도 별개의 토큰이다.
- '(작은 따옴표)는 아래와 같이 처리한다.
- not의 준말인 n't는 하나의 token이다. don't→do n't
- ' 뒤의 글자들을 붙여서 처리한다. 's 'm 're 등등
- 모든 토큰은 소문자로 변환되어야한다.
예시: 'I don't like Jenifer's work.'
→ [i, do, n't, like, jenifer, 's, work, .]
import re
text="I don't like Jenifer's work."
pattern_list=[r'\s',r'n\'t',r'\.',r',',r'\?',r'!',r'\'.']
pattern=re.compile("("+'|'.join(pattern_list)+")")
sentence=text.lower()
seperate_result=re.split(pattern,sentence)
seperate_result=' '.join([""if i==None else i for i in seperate_result]).split()
token_list=list(seperate_result)
print(token_list)

각 pattern_list 내에 있는 패턴들은 위와 같은 의미를 가진다. 특히, escape 문자를 잘 활용해야겠다.

최종적으로, compile되는 pattern은 각 서로 다른 조건중 하나라도 만족하면 해당부분을 split할 수 있게 소괄호와 |로 설정한다. 또한, ()로 묶어주면서 split 함수 사용시 구분자가 빈 문자열로 저장 될 수 있는데 이를 방지해준다.
Vocabulary
컴퓨터는 글자를 알아볼 수 없어 각 token을 유일한 id에 매핑해야한다. 앞서 만든 token화 알고리즘을 적용해서 token화한 결과가 있다고 가정하자. 여러 token화한 문장에서 token의 빈도수를 count하는 과정이 필요하다. 아래와 같은 방법으로 구현할 수 있다.
from collections import Counter
sentences=[['a','a','a','b'],['c','c','d','b']]
c=Counter()
for sentence in sentences:
c+=Counter(sentence)
for key,value in c.items():
print(key,value)
Counter 클래스를 활용해서, dictionary type으로 각 token에 대한 빈도수를 구할 수 있다. 위의 예시에서는 a가 3회 등장하고, b와 c가 2회, d가 1회 등장하는 것을 알 수 있다. 이때 자주 등장하지 않는 단어는 과적합을 일으킬 수 있기 때문에, UNK 토큰으로 처리하자.
from typing import List, Tuple, Dict
from collections import Counter
# [UNK] 토큰
unk_token = "[UNK]"
unk_token_id = 0 # [UNK] 토큰의 id는 0으로 처리합니다.
def build_vocab(sentences: List[List[str]], min_freq: int) -> Tuple[List[str], Dict[str, int]]:
c=Counter()
for sentence in sentences:
c+=Counter(sentence)
id2token: List[str] = [unk_token]
token2id: Dict[str, int] = {unk_token: unk_token_id}
id=1
for key,count in c.items():
if count<min_freq:
pass
else:
id2token.append(key)
token2id[key]=id
id+=1
assert id2token[unk_token_id] == unk_token and token2id[unk_token] == unk_token_id, \
"[UNK] 토큰을 적절히 삽입하세요"
assert len(id2token) == len(token2id), \
"id2word과 word2id의 크기는 같아야 합니다"
return id2token, token2idc라는 Counter 클래스 객체(dict type)에 token별 빈도수를 저장한다. 그 후, key(token), count(빈도) 를 loop를 돌며, 최소 빈도수보다 적은 경우 vocab에 넣지 않고 pass한다. 그리고, 최소 빈도수를 만족하는 경우 id2token list에 문자를 넣는다. 그리고, token2id dict type 변수에도 각 token에 해당하는 index를 넣게 된다. 정리하면 변수에 저장되는 값은 아래와 같다.
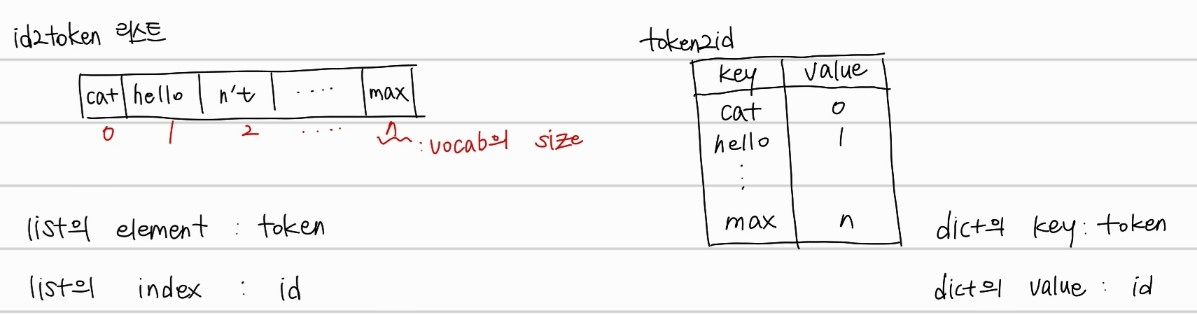
encoding
from typing import Callable
def encode(tokenize: Callable[[str], List[str]],sentence: str,token2id: Dict[str, int]) -> List[str]:
token_ids: List[int] = list()
tokens=tokenize(sentence=sentence)
for token in tokens:
if token not in token2id.keys():
id=token2id['[UNK]']
else:
id=token2id[token]
token_ids.append(id)
return token_ids
이제 token화한 text를 숫자표현으로 바꾸는 encoding을 진행해보자.
위에서, tokenize로 문장으로 tokens 리스트 형태로 변환한 후에 for문을 돌며 각 token이 이전에 만든 token2id에 존재하는지의 여부로 없다면 UNK key에 해당하는 0값을 id로 부여하고, 존재한다면 해당 token key의 value값을 반환하여 token_ids 리스트 형태로 반환하게끔 구현할 수 있다.
쉽게 이전에 생성한 token과 id 쌍으로 이루어진 dict data에서 매칭되는 token이 없다면 0으로 수치화하는 것이다.
decoding
def decode(token_ids: List[int],id2token: List[str]) -> str:
return ' '.join(id2token[token_id] for token_id in token_ids)decoding 함수는 이전에 수치화한 list값을 입력으로 받는다. 각 수는 이전의 id2token list에서 token의 index를 의미한다. 따라서 쉽게 token_id 즉, 인덱싱을 진행하면 주어진 문장을 다시 원상태로 복구하여 리스트로 저장이 가능하고 이를 ' '로 join함을 통해 원문장으로 복구 가능하다.

이렇게 인코딩과 디코딩을 문제없이 수행하는 것을 확인할 수 있었다.
Reference
