
Self-supervised learning & Transfer learning
self-supervised learning이란, 데이터의 일부를 숨기고, 해당 부분을 예측하도록 학습하는 것을 의미한다. label이 지정되지 않은 샘플 데이터에서 학습을 진행하는 것이다. 이러한 self-supervised learning 기법을 이용하여 모델을 사전학습하게 된다.
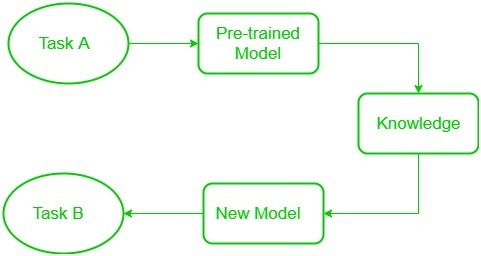
pre-training 과정을 거친 모델은 그 언어 자체에 대한 이해도가 높아지게 되는 것이다. 이후에 사전학습된 모델을 내가 원하는 목표 Task에 맞게끔 fine tuning하는 방법론을 transfer learning이라고 한다.
BERT
언어모델 중 BERT(Bidirectional Encoder Representations from Transformers)는, pre-training 과정을 거친 후, 다양한 Task에 맞게 fine tuning이 가능한 모델이다.
pre-training task
label이 지정되지 않은 대량의 데이터로 사전학습을 진행하며 두 가지 task로 진행된다.
Masked language modeling(MLM)
무작위로 입력된 Token의 15%에 해당하는 부분의 token을 감추고(Masking) 이를 예측한다.
- 15%의 Token 중 80%의 Token은 [MASK] token으로 대체한다.
- 15%의 Token 중 10%의 Token은 다른 Token으로 대체한다.
- 15%의 Token 중 10%의 Token은 원래 Token을 그대로 사용한다.
여기서, 원래의 Token을 굳이 쓰는 이유는 모델이 편향을 가질 수 있기 때문이다. 15%의 Token에서 MASK를 제외한 Token이 모두 대체된 Token이라면, 반대로, 15%에 해당하며, MASK Token이 아니라면 무조건 대체된 단어라는 것을 알게 된다.
대체된 단어는 예측 가능 범위에서 아예 제거해버리는 편향이 존재할 수 있다. 다른 이유 한가지 더 생각할 수 있다.
pretrain data에 MASK Token만 존재하게 되면, fine tuning할때의 data와 너무 차이나게되는 문제가 있다. 실제로 사용하는 data에는 MASK Token같은건 없기 때문이다.
Next-sentence prediction(NSP)
말 그대로 문장 A 뒤에 문장 B가 실제 이어지는 문장인지 예측하는 것을 의미한다.
- 문장 A : 그 남자는 가게 [MASK] 갔다.
- 문장 B : 그는 [MASK] 한 병을 샀다.
위의 두 문장에 대해서 IsNext 인지, NotNext인지 판단하는 것이다. 1개의 model로 MLM과 NSP를 수행하며 여러 문장들의 문맥을 파악하는 학습과정을 거치게 된다.
BERT model 구조
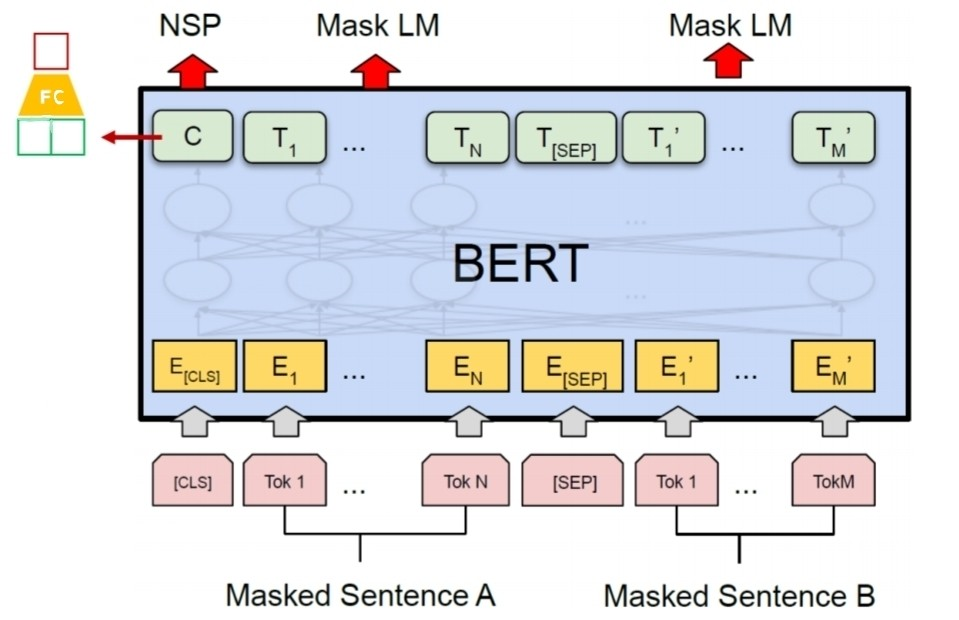
위의 그림은 간단한 BERT 모델 구조이다.
BERT의 input먼저 확인해보면, 다른 token은 알겠지만, [CLS] token과 [SEP] token이 존재하는 것을 알 수 있다. 이는 각각, NSP 이진분류에 대한 결과를 위한 token과 이어붙인 두문장을 구분하기 위한 token이다.
BERT의 output을 확인해보면, NSP와 MASK LM이 있다. NSP는 0~1의 값으로 두 연속된 문장이 얼마나 관련있는지 나타낸다. MASK LM은 masking 처리한 부분에 vocab 차원의 vector로 softmax를 취한 값을 가진다. 즉, vocab안에서 가능한 단어중 가장 확률이 높은 단어를 선택하게 된다.
기본적인 transformer와 살짝 다른 구조의 input을 가지는데 embedding은 어떻게 바뀌게 될까?
Input Embedding
BERT에서의 input embedding은 token에 대한 embedding과 문장 내 위치(position embedding) 그리고, segment(문장 구분) embedding이 있다.
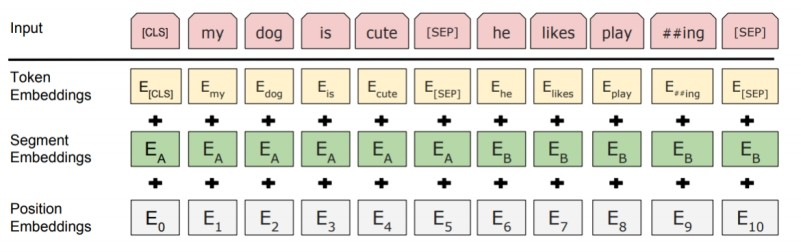
위의 예시를 보자.
먼저 각 token에 대해 (CLS,SEP 포함) token embedding을 수행한다. 또한, 각 embedding에 문장의 연결 여부를 나타내는 segment embedding 값을 더해준다 (보통 1,0으로 구분한다). 마지막으로, 학습가능한 position embedding으로 문장내 token들을 vector화 한다.
이제 pre-train에 대해서 간단하게 알아봤으니, fine tuning과정을 살펴보자.
fine-tuning task
pre-train 된 BERT 모델을 사용하여 fine tuning을 통해 downstream task 즉, 하위 업무를 지정해서 수행할 수 있다. 각 fine tuning마다 살짝 다른 network구조를 가지게 되는데 이를 위주로 한번 살펴보자.
Sentence Classification
주어진 한 문장에 대해 기준에 맞는 분류를 수행하는 Task이다. [CLS] token의 Encoder output vector를 이용해 classification을 진행한다.
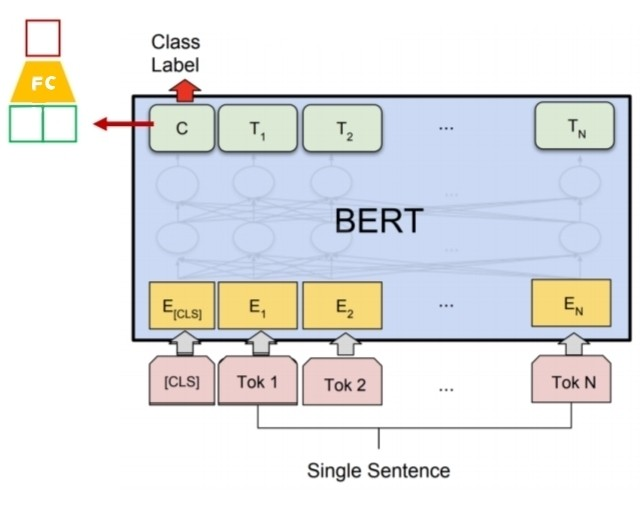
이전에 pre-train시 쓰던 문장 연결 여부에서의 FC layer를 떼서 버리고, 감정 분류와 같은 task를 넣게 된다. 입력도 한개의 문장에 대해서 classification을 진행하기 때문에, single sentence가 입력된다.
Sentence Pair Classification
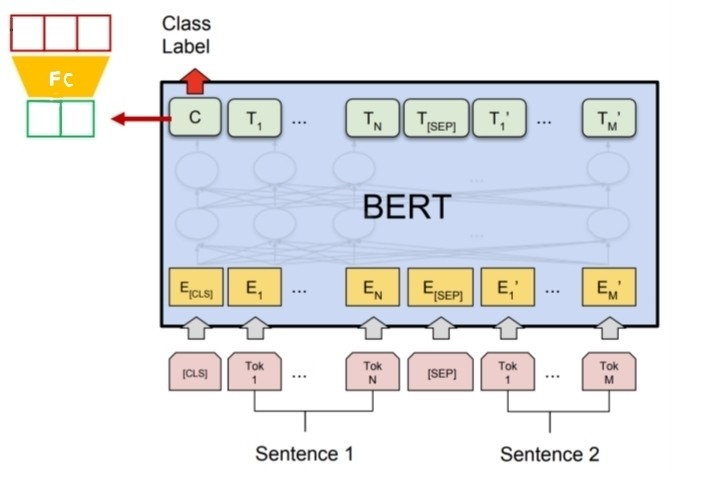
[CLS] token의 Encoder ouput vector를 이용해서 classification을 진행한다. 문장 간 구분은 segment embedding으로 input에서 진행한다. 최종 output으로 두 문장 간의 관계를 출력하게 된다. 위의 예시에선 두 문장이 서로 내포하는관계인지, 모순되는지, 무관한 관계인지 출력하게끔 만든 네트워크 구조이다.
Sentence Tagging
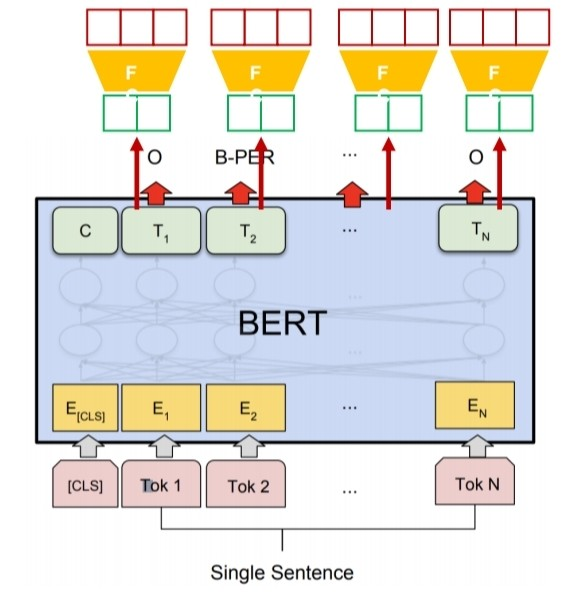
Token 단위로 특정 속성을 예측하는 Task이다. 위의 예시는 BIO tagging이다. BIO tagging의 규칙은 그렇게 어렵지않다.
한 뜻을 가진 용어가 여러개의 단어로 이루어질 수 있다. 예를들어 만약 token이 New와 York으로 있다면, 이를 place로 tagging하는 것이 가능하다. 이때, New를 tag의 시작 token으로 B-place로 tagging하고, 후에 이어지는 token을 I-place로 tagging한다. 그리고, 어떤 tag에도 속하지 않는다면, O tag를 부여한다.
문장 내 여러개의 token들이 각각 어떤 범주에 속하는지 판별하는 것이 가능하다.
Machine Reading Comprehension
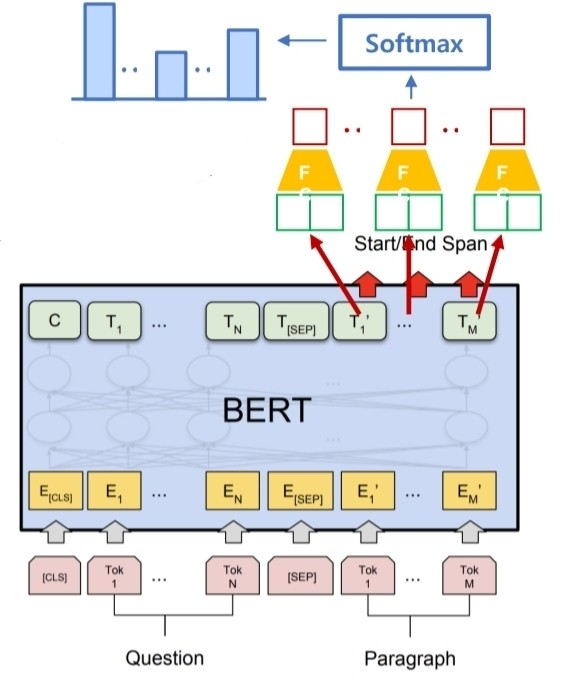
질문과 단락이 입력으로 주어진다. 이때, 단락에 대해서 질문에 대한 답에 해당하는 부분을 단락 안의 Token을 encoder output vector로 나타내 classification을 진행한다.
입력으로 주어진 단락내에서 어떤 위치에 있는지 시작과 끝을 예측하는 classifier를 사용해서 단락내에서 정답을 찾게된다. 이과정에서 지문내 존재하는 모든 단어에 대한 logit이 생기고 이를 확률로 변환하게 된다.
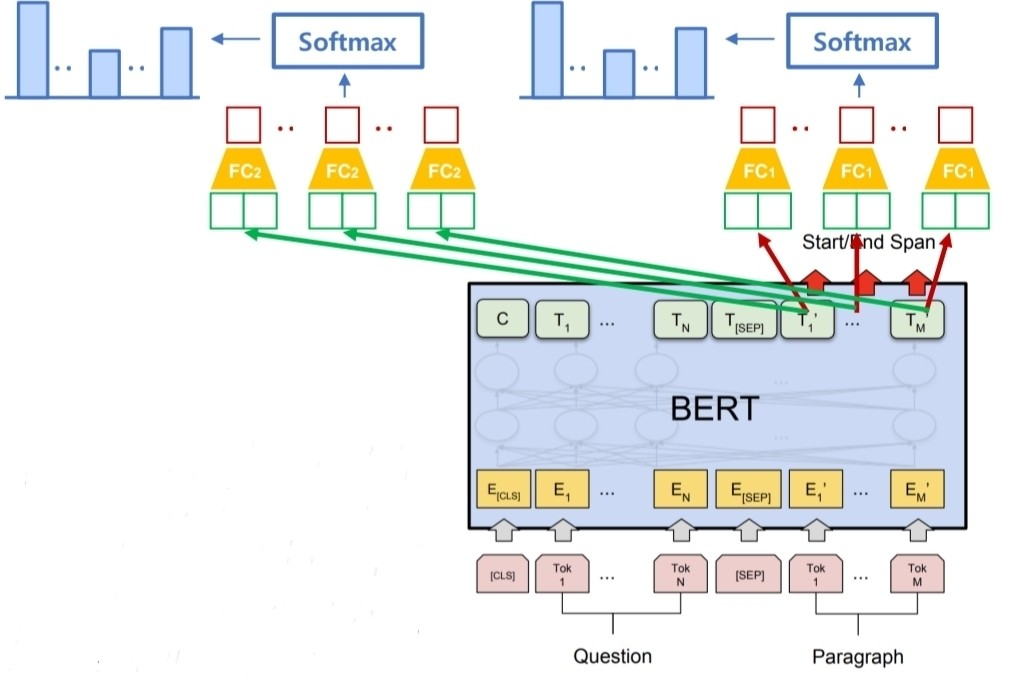
answer span에서 첫 단어로 예측한 단어보다 뒤에 있는 단어중 확률이 제일 높은 위치로 마지막 단어의 위치를 예측하게 된다.
이렇게 BERT 모델의 pre-training과정과 fine tuning downstream task들에 대해 간단하게 복습해봤다.
Reference
https://www.geeksforgeeks.org/ml-introduction-to-transfer-learning/
