
다익스트라 알고리즘은 시작 노드에서 graph에 존재하는 다른 모든 노드까지 걸리는 최단경로를 찾는 알고리즘이다. 노드를 연결하는 간선의 가중치가 모두 양수일때를 전제로한다.
우선순위 큐와 for문을 사용해서 구현 가능하다. 먼저 기본적인 알고리즘의 동작 원리를 살펴보고 파이썬 코드로 구현해보자.
동작원리
- 출발노드를 설정한다.
- 모든 노드에 대한 가중치 배열을 선언하여 로 초기화한다.
- 출발노드를 기준으로 모든 노드의 최소 가중치를 저장한다. (출발노드의 가중치 : 0)
- 방문하지 않은 노드 중에서 가중치가 가장 작은 노드를 선택해 방문한다.
- 4번에서 방문한 노드를 거쳐서 가는 경로를 고려해 가중치 배열을 최소 가중치로 갱신한다.
- 4,5번을 모든 노드를 방문할 때까지 반복한다. → 최종 가중치 배열이 결과값
위의 동작 원리를 이해하기 쉽게 그림으로 그려보자.
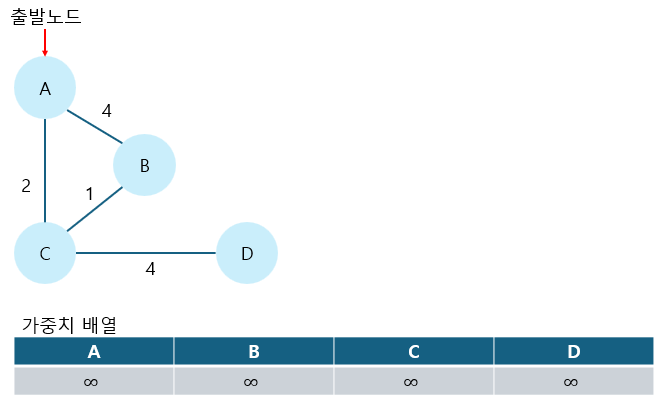
1. 출발노드를 설정한다.
2. 모든 노드에 대한 가중치 배열을 선언하여 로 초기화한다.
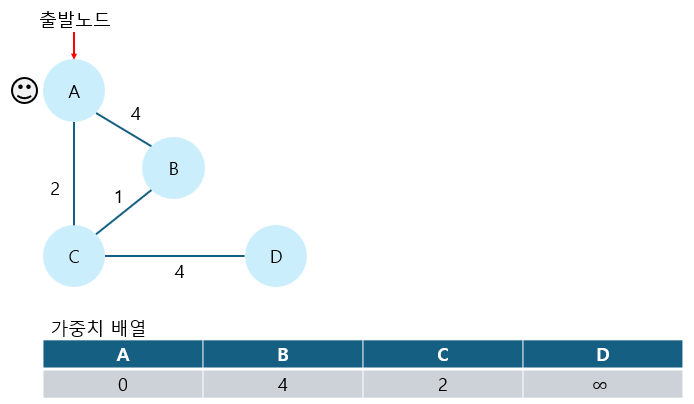
3. 출발노드를 기준으로 모든 노드의 최소 가중치를 저장한다.(출발노드의 가중치 : 0)
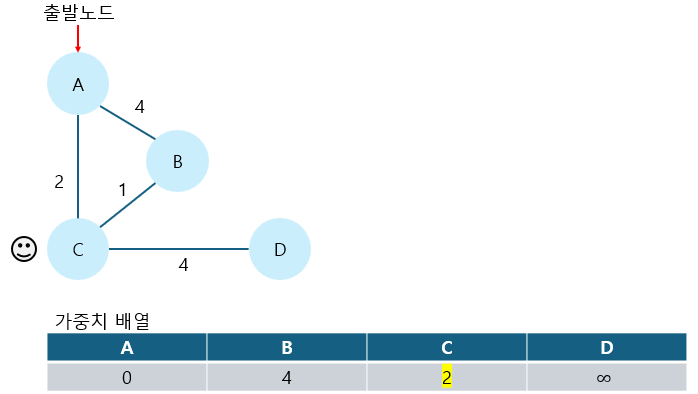
4. 방문하지 않은 노드 중에서 가중치가 가장 작은 노드를 선택해 방문한다.
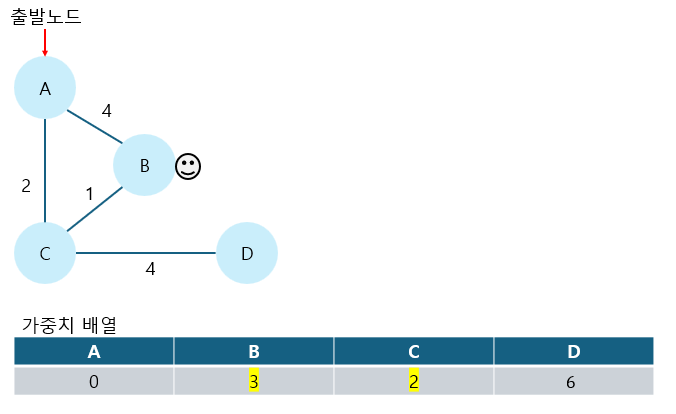
5. 4번에서 방문한 노드를 거쳐서 가는 경로를 고려해 가중치 배열을 최소 가중치로 갱신한다.
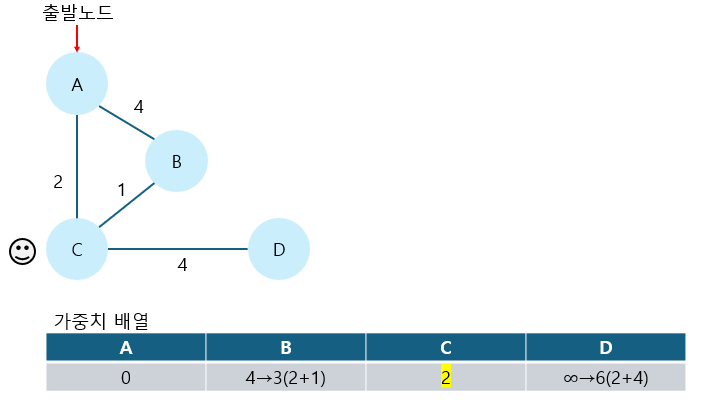
C를 거쳐서 B로 도착하는 경로가 더 작은 가중치를 가지기 때문에 가중치 update를 진행한다.
다시 4번 반복
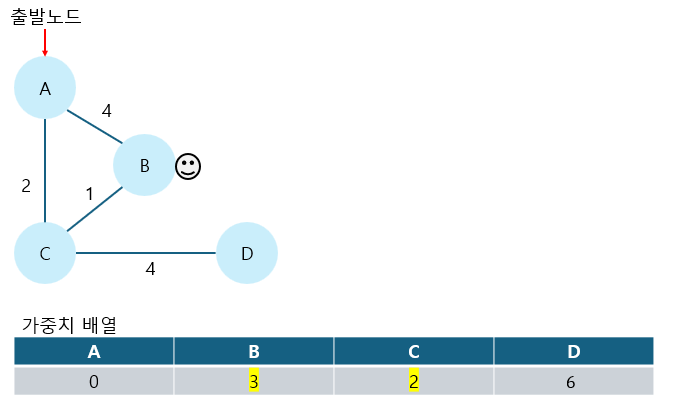
4. 방문하지 않은 노드 중에서 가중치가 가장 작은 노드를 선택해 방문한다.
**5. 4번에서 방문한 노드를 거쳐서 가는 경로를 고려해 가중치 배열을 최소 가중치로 갱신한다.
4. 방문하지 않은 노드 중에서 가중치가 가장 작은 노드를 선택해 방문한다.
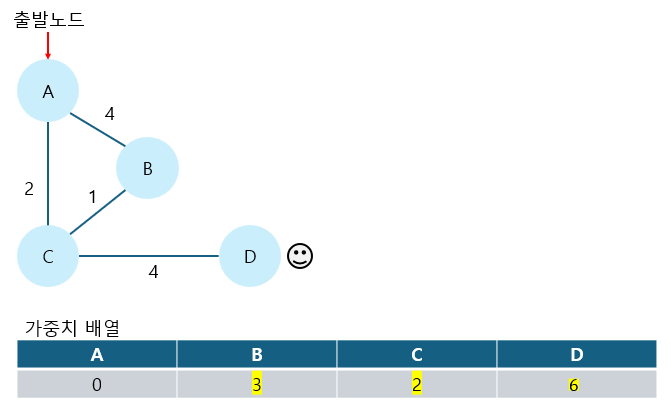
이렇게 해서 최종적으로 A를 출발노드로 설정했을 때, 모든 노드로의 최단거리를 얻을 수 있다.
코드구현
현재 예시에서 노드를 문자로 설정한 상태이다. 따라서, "노드의 갯수+1" 크기로 배열을 선언한 후, 해당 배열의 인덱스를 노드 번호로 치환하여 생각하고 구현하는 것이 불가하여, graph를 dictionary 형태로 구현하였다. 두 코드에서
graph[start_node].append((end_node,dist))
graph[end_node].append((start_node,dist)) 부분은 서로 방향성이 없이 연결되어있는 노드임을 의미한다. 한쪽으로만 이동 가능한 것이 아닌, 모두 이동가능하다는 것을 의미한다.
For문
- 시간 복잡도 : V:노드의 수
from collections import defaultdict
import sys
INF=sys.maxsize # 초기화 ♾️ 가중치
n,m=map(int,input().split()) # n개의 node와 m개의 간선
start=input() # 출발 node
graph=defaultdict(list) # grpah에 node의 연결상태 및 간선의 가중치 저장
visited={} # 방문 여부 저장
distance={} # 출발 node에서 각 node로의 가중치 배열
# node 정보 입력
for _ in range(m):
start_node,end_node,dist=input().split()
dist=int(dist)
graph[start_node].append((end_node,dist))
graph[end_node].append((start_node,dist))
# start node와 end node 연결됨을 의미하기 위해서 start,end key에 모두 같은 가중치로 append
# node의 방문 여부와 가중치 모두 False와 ♾️로 초기화
for node in graph.keys():
visited[node]=False
distance[node]=INF
def get_smallest_node(graph):
min_value=INF
next_node=''
for start in graph.keys():
if distance[start]<min_value and visited[start]==False:
# graph의 node를 순회하며 가중치가 가장 작은 다음 node선택
min_value=distance[start]
next_node=start
return next_node # 현재의 node와 연결된 node 중 가장 가중치가 작은 node 선택
def dijsktra(start):
distance[start]=0 #출발 node 0으로 가중치 초기화
visited[start]=True #출발 node 방문 처리
for j in graph[start]: #출발 node와 연결된 다음 node들
distance[j[0]]=j[1] #graph에서 (다음node,가중치) 순으로 넣었음
#j=[(2,2), (3,5), (4,1)] 이면, j[0]=2,3,4 다음으로 갈 수 있는 node이고, j[1]=2,5,1 다음으로 갈 수 있는 node의 가중치이다.
for _ in range(n-1): # 시작node를 제외한 나머지 node 다 방문할 횟수만큼만 실행(n-1회 반복)
now=get_smallest_node(graph) # 다음으로 방문 가능한 node중 가장 가중치 작은 node선택
visited[now]=True # node 방문처리
for j in graph[now]:
cost=distance[now]+j[1]
if cost<distance[j[0]]: # 기존의 가중치보다 현재 node 거쳐가는 가중치가 더 작으면 가중치 update
distance[j[0]]=cost
dijsktra(start)
# 출력
print(graph)
for node in graph.keys():
if distance[node]==INF:
print(node,visited[node],"infinite")
else:
print(node,visited[node],distance[node],end=" ")
번에 걸쳐서 최단 거리가 가장 짧은 노드를 매번 선형 탐색해야 하고, 현재 노드와 연결된 노드를 매번 get_smallest_node 를 통해서 노드를 모두 순회하며 일일이 확인하기 때문에, 의 시간이 걸린다.
우선순위 큐
- 시간 복잡도 : E:간선의 수, V:노드의 수
from collections import defaultdict
import sys
import heapq
INF=sys.maxsize # 초기화 ♾️ 가중치
n,m=map(int,input().split()) # n개의 node와 m개의 간선
start=input() # 출발 node
graph=defaultdict(list) # grpah에 node의 연결상태 및 간선의 가중치 저장
distance={} # 출발 node에서 각 node로의 가중치 배열
# node 정보 입력
for _ in range(m):
start_node,end_node,dist=input().split()
dist=int(dist)
graph[start_node].append((end_node,dist))
graph[end_node].append((start_node,dist))
# start node와 end node 연결됨을 의미하기 위해서 start,end key에 모두 같은 가중치로 append
# node의 방문 여부와 가중치 모두 False와 ♾️로 초기화
for node in graph.keys():
distance[node]=INF
def dijkstra(start):
priority_queue=[]
heapq.heappush(priority_queue,(0,start))
distance[start]=0
while priority_queue:
dist,current_node=heapq.heappop(priority_queue) # 가중치가 가장 작은 node 방문
if distance[current_node]<dist:
continue
for next_node, next_dist in graph[current_node]:
cost=dist+next_dist
if cost<distance[next_node]:
distance[next_node]=cost
heapq.heappush(priority_queue,(cost,next_node))
dijkstra(start)
# 출력
print(graph)
for node in graph.keys():
if distance[node]==INF:
print(node,"infinite")
else:
print(node,distance[node],end=" ")

heap 정렬을 통해서, heappop을 수행했을때 가중치가 가장 작은 노드를 뽑아낼 수 있다. 그 후, 뽑아낸 노드의 이전 방문 여부를 확인하고 방문처리를 한다음, graph에서 노드의 다음 노드들을 순회하며 합한 가중치가 기존의 가중치 값보다 작은 경우 수정을 한 후에 heappush를 통해 노드를 추가하는 과정으로 구현했다.
또한, 반복문과 달리 최단거리를 뽑은 노드가 현재 distance 리스트에 들어있는 노드의 값보다 더 크면 반복문을 실행하지 않는 것으로, 이미 방문한 노드를 처리하는 과정을 visited 변수없이 실행하였다.
while priority_queue:우선순위 큐에서 뽑은 노드가 이미 방문한 노드라면, 어떤 연산도 수행하지 않기 때문에, 노드를 하나씩 꺼내서 검사하는 반복문은 노드의 개수 V 이상의 횟수로는 반복되지 않는다.
for next_node, next_dist in graph[current_node]:또한, 반복될 때마다 뽑아져 나온 노드는 자신과 연결된 간선들을 모두 확인한다. "현재 우선순위 큐에서 꺼낸 노드와 연결된 다른 노드들을 확인" 하는 횟수는 총 최대 간선의 개수 만큼 연산이 수행될 수 있다.
E개의 원소를 우선순위 큐에 넣었다가 빼는 연산과 유사하다. 최대 E개의 간선 데이터를 heap에 넣고 다시 빼는 것의 시간복잡도는 이다.
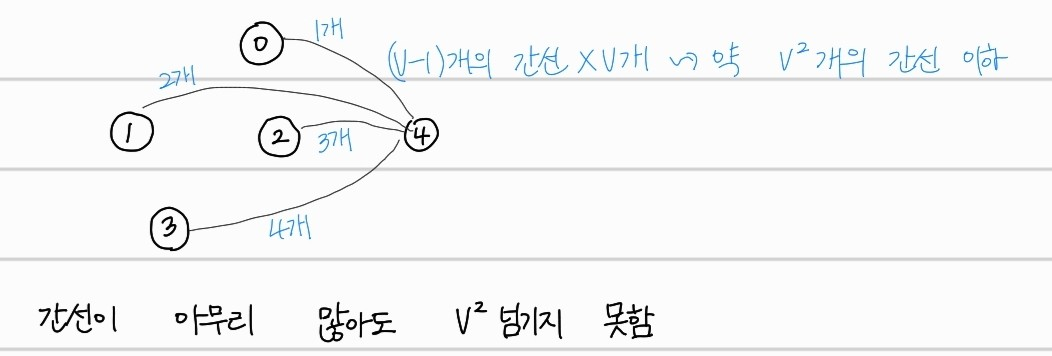
이때, 중복간선을 포함하지 않는다면, 모든 노드끼리 서로 다 연결되어 있다고 했을때 간선의 개수를 으로 볼 수 있고, (간선의 갯수)는 항상 보다 작거나 같다고 할 수 있다. 따라서, 는 으로 표현 가능하고, 임을 알 수 있다. 따라서, heap 자료구조를 사용한 우선순위 큐로 다익스트라 알고리즘을 구현하면, 의 시간 복잡도가 계산되는 것이다.
Reference
https://m.blog.naver.com/ndb796/221234424646
https://youtu.be/611B-9zk2o4
