
Overview
open-domain QA model(질의응답 모델) 프로젝트를 진행하며 모델의 성능을 높이는 과정에서, reader model의 성능을 높이기 위한 방법을 고려중이였다. 삼성 SDS에서 제안한 KorQuAD 성능 개선 방안에서 모델의 구조를 직접 수정하여 성능을 높이는 방법론을 찾게 되어 실제로 구현해보았다.
기본적으로 BERT 모델로 question answering 수행시, generation이 아닌 extraction 방법으로 수행한다. Extraction QA는 말 그대로 정답을 생성하는 것이 아니라, context 내에서 정답을 찾아내는 방법이다.
context 내에서 각 token들이 모두 start logit 과 end logit을 가지고 있다. context 내 정답이 존재할때, start logit이 제일 큰 token부터 end logit이 제일 큰 token까지가 정답에 해당함을 의미한다.
보통 BERT 계열 모델은 output으로 각 token마다 hidden state vector가 나온다. 이는 768 차원의 vector로 token들을 컴퓨터가 이해할 수 있게 숫자화 했다고 생각하면 편하다.
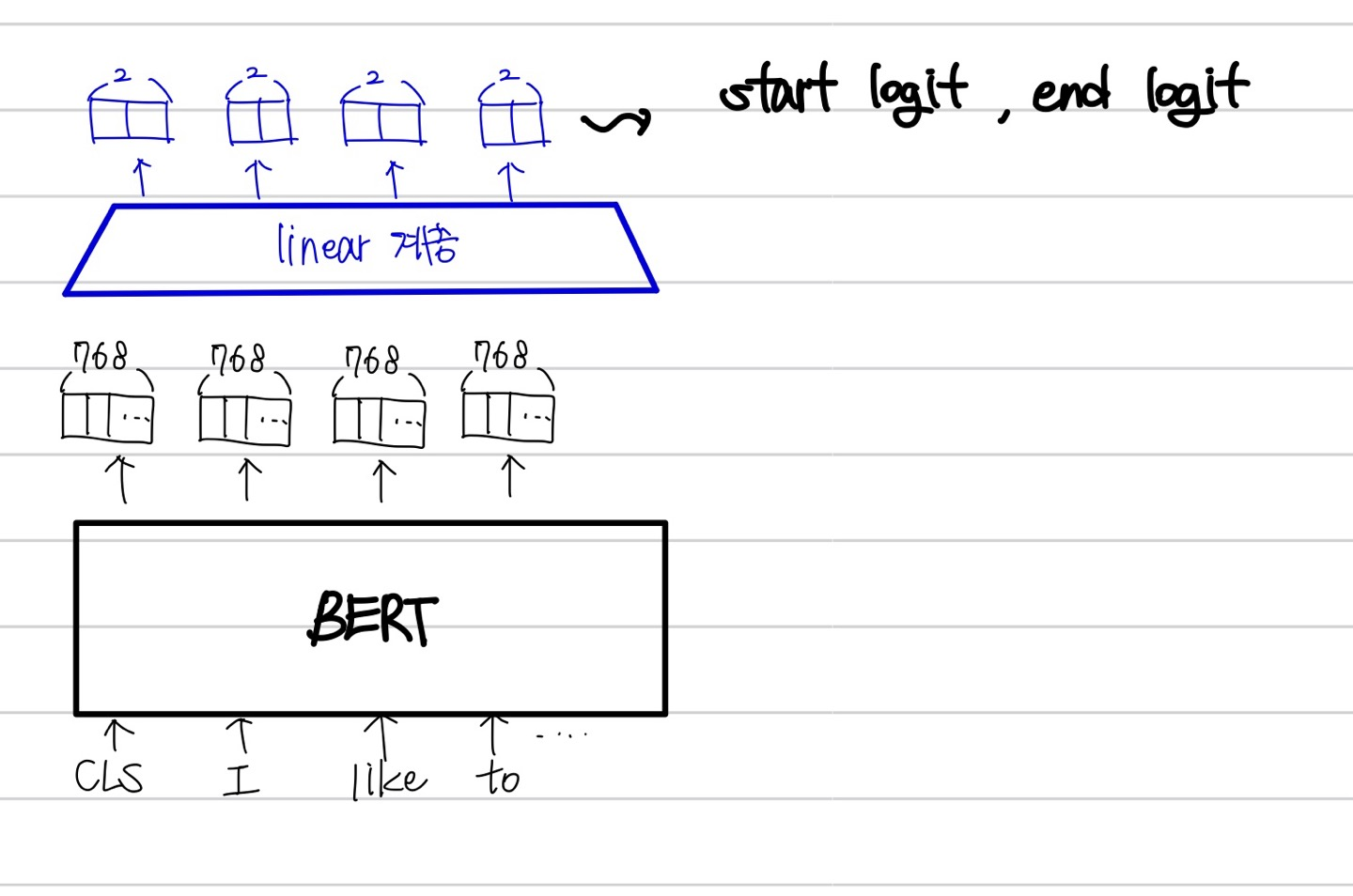
문장 내에 있는 각 token들이 768차원의 vector로 나오게 되고, 마지막에 linear layer 를 추가해 768 차원의 vector를 선형변환하여 2개의 값 (start logit,end logit)으로 변환하는 것이다.
여기서 마지막에 위치하는 linear layer를 CNN layer로 바꿔 성능을 개선해보았다.
Method
class BertForQuestionAnswering(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.bert = BertModel(config, add_pooling_layer=False)
self.qa_outputs = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(BERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_QA,
output_type=QuestionAnsweringModelOutput,
config_class=_CONFIG_FOR_DOC,
qa_target_start_index=_QA_TARGET_START_INDEX,
qa_target_end_index=_QA_TARGET_END_INDEX,
expected_output=_QA_EXPECTED_OUTPUT,
expected_loss=_QA_EXPECTED_LOSS,
)위는 huggingface에서 제공하는 BertForQuestoinAnswering의 소스코드다.
먼저, 클래스의 초기화 부분에서, 일반 BertModel을 상속받고, qa_outputs라고 정의된 linear layer를 추가한 구조임을 확인할 수 있다.
class BertForQuestionAnswering(BertPreTrainedModel):
def forward(
...
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
logits = self.qa_outputs(sequence_output)
start_logits, end_logits = logits.split(1, dim=-1)
start_logits = start_logits.squeeze(-1).contiguous()
end_logits = end_logits.squeeze(-1).contiguous()또한, forward 함수를 보면, BERT 모델의 output을 qa_outputs layer(linear layer)를 통과 시킨 후, start_logits 과 end_logits로 split하는 것을 확인할 수 있다. 이제, 이 마지막 layer를 CNN layer로 수정해보자.
1D Convolution을 추가하면 Kernel Size에 해당하는 인접 토큰들의 임베딩 벡터 간의 연관성을 학습하여 보다 풍부한 문맥 정보를 얻을 수 있다.
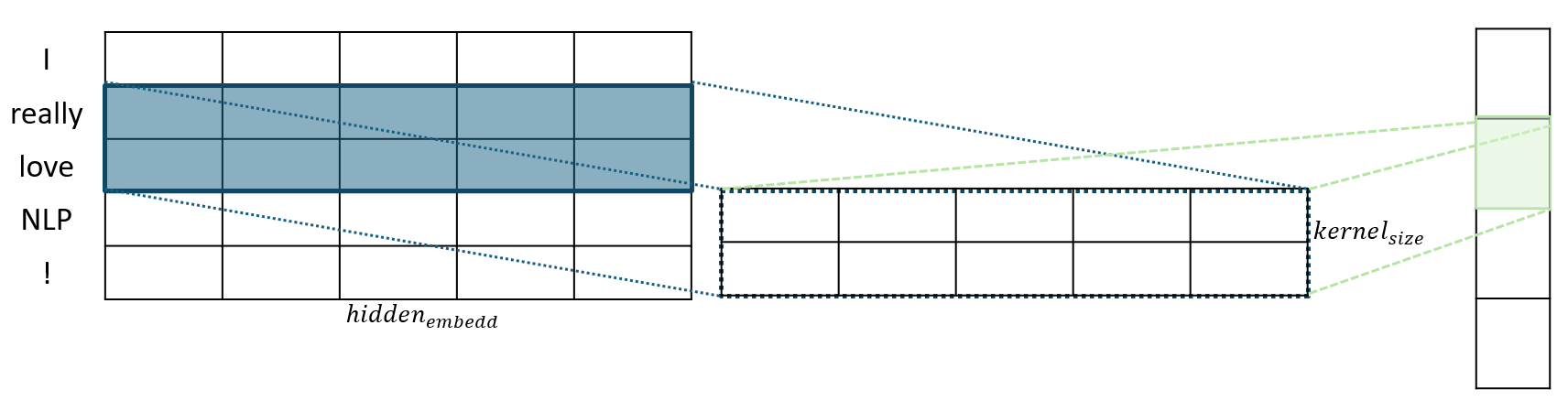
1D Convolution은 2D Convolution 와 달리 커널의 높이가 임베딩 차원과 같고(여기서는 768차원에 해당한다) , 너비만 kernel size로 설정한다. 위의 간단한 예시를 보면, 5차원의 임베딩차원과 2의 kernel size를 가지는 것을 확인할 수 있다.
최종 결과에 해당하는 우측의 vector는, 차례대로, (I,really) , (really,love) , (love,NLP) , (NLP,!) 쌍의 정보를 가지는 임베딩 값임을 알 수 있다.
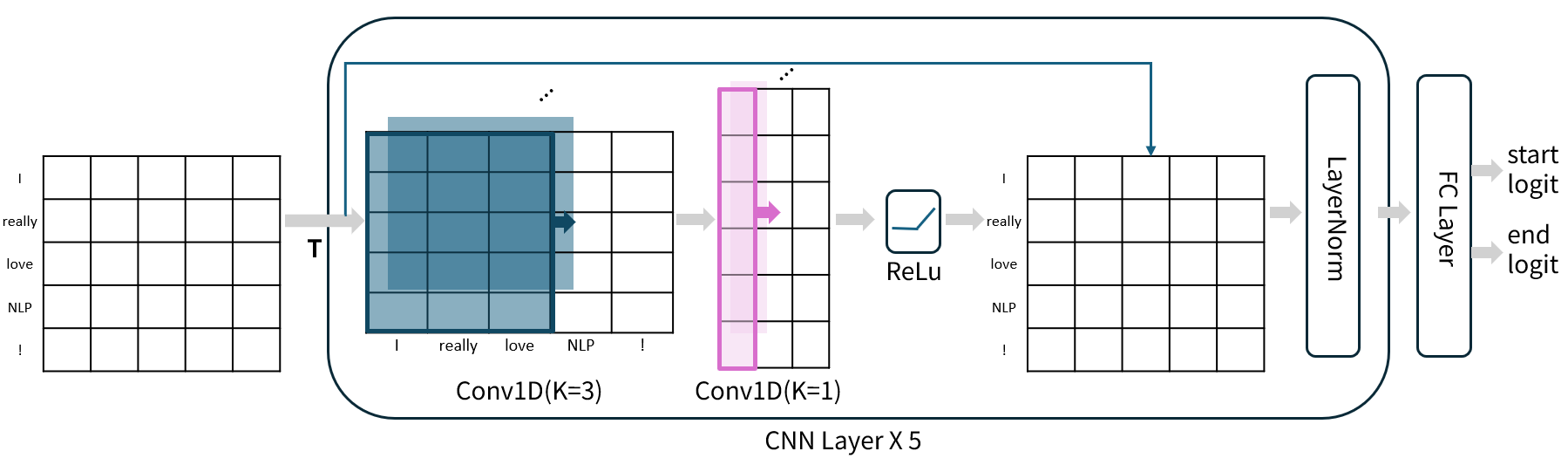
삼성 SDS에서 제안한 것과 최대한 동일하게 구현하기 위해 먼저 구조를 작성해봤다. kernel size가 3인 cnn layer를 통과하고, 다시 kernel size가 1인 cnn layer를 통과한후, 첫번째 cnn layer를 통과하기 전의 값과 residual connection을 적용했다.
여기서 residual connection을 적용한 이유는, 기존의 BertForQuestionAnswering 보다 cnn layer를 5번 반복하여 더 깊은 model architecture가 되기 때문에, gradient vanishing 문제가 발생할 수 있어 포함하였다.
Code
from transformers import BertPreTrainedModel
from transformers import BertModel나만의 QA 클래스를 만들어야하기 때문에, 기본적으로 huggingface의 source code를 베이스라인으로 잡고 이를 수정하는 방향으로 진행했다. 제일 먼저, hidden state vector를 output으로 가질 수 있게끔, 기본적인 BertModel을 import하였다.
from torch import nn
from torch.nn import CrossEntropyLoss
import torch
from typing import Optional, Tuple, Union또한, 아키텍쳐 수정을 위해 필요한 라이브러리를 import하였다.
class Bert_CNN_Answering(BertPreTrainedModel):
def __init__(self, config, model_path):
super().__init__(config)
self.num_labels = config.num_labels
self.bert = BertModel.from_pretrained(model_path, config=config, add_pooling_layer=False)
# for name,param in self.bert.named_parameters():
# print(f"Parameter {name}: requires_grad={param.requires_grad}")
for param in self.bert.parameters(): # 모델의 파라미터를 학습 가능 상태로 설정
param.requires_grad=True
self.conv1 = nn.Conv1d(config.hidden_size, 128, kernel_size=3, stride=1, padding=1) # Conv1d : (in_channels, out_channels, kernel_size) 500은 임의로 정함
self.conv2 = nn.Conv1d(128, config.hidden_size, kernel_size=1, stride=1) # Conv1d : (in_channels, out_channels, kernel_size)
self.relu = nn.ReLU()
# LayerNorm은 (batch_size, seq_len, hidden_size) 형식으로 입력을 받아야 하므로 Conv1d 이후 permute를 고려
self.layer_norm = nn.LayerNorm(config.hidden_size)
# start와 end 위치를 예측하는 Linear 레이어 정의
self.qa_outputs = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.init_weights()사전학습된 Bert모델을 불러오고 해당 모델의 모든 파라미터를 학습 가능한 상태로 설정해준다. conv1과 conv2는 각각 kernel size가 3, 1인 1d cnn layer이다. 활성화함수 relu와 layer_norm도 작성하여 클래스 초기화 부분에 작성해두었다.
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
token_type_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
start_positions: Optional[torch.Tensor] = None,
end_positions: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor], QuestionAnsweringModelOutput]:
r"""
start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the start of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
are not taken into account for computing the loss.
end_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the end of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
are not taken into account for computing the loss.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
# print(f"input_ids: {input_ids.size() if input_ids is not None else 'None'}")
# print(f"attention_mask: {attention_mask.size() if attention_mask is not None else 'None'}")
# print(f"token_type_ids: {token_type_ids.size() if token_type_ids is not None else 'None'}")
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids, # Roberta 모델 사용시 사용안함
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
# Conv1d는 (batch_size, hidden_size, seq_len)
conv_input = sequence_output.permute(0, 2, 1)
# CNN 레이어를 5번 반복해서 통과시킴
for _ in range(5):
residual = conv_input
conv1_output = self.conv1(conv_input)
conv2_output = self.conv2(conv1_output)
relu_output = self.relu(conv2_output)
residual_output = relu_output + residual
# LayerNorm#
# 다시 (batch_size, seq_len, hidden_size)로 permute
conv_output = residual_output.permute(0, 2, 1)
conv_input = self.layer_norm(conv_output)
# layernorm #
conv_input = conv_input.permute(0, 2, 1)
# (batch_size, seq_len, hidden_size)
norm_output = conv_input.permute(0, 2, 1)
# QA 태스크를 위한 start, end logits 계산
logits = self.qa_outputs(norm_output)
start_logits, end_logits = logits.split(1, dim=-1)
start_logits = start_logits.squeeze(-1).contiguous()
end_logits = end_logits.squeeze(-1).contiguous()
total_loss = None
if start_positions is not None and end_positions is not None:
# If we are on multi-GPU, split add a dimension
if len(start_positions.size()) > 1:
start_positions = start_positions.squeeze(-1)
if len(end_positions.size()) > 1:
end_positions = end_positions.squeeze(-1)
# sometimes the start/end positions are outside our model inputs, we ignore these terms
ignored_index = start_logits.size(1)
start_positions = start_positions.clamp(0, ignored_index)
end_positions = end_positions.clamp(0, ignored_index)
loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
# print('start_logits',start_logits)
# print('start_positions',start_positions)
start_loss = loss_fct(start_logits, start_positions)
end_loss = loss_fct(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2
print('start_loss',start_loss)
print('end_loss',end_loss)
print('total_loss',total_loss)
if not return_dict:
output = (start_logits, end_logits) + outputs[2:]
return ((total_loss,) + output) if total_loss is not None else output
return QuestionAnsweringModelOutput(
loss=total_loss,
start_logits=start_logits,
end_logits=end_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)기존의 huggingface open source에서 outputs 는 Bert모델의 출력을 의미한다. 따라서, 이를 그대로 활용하여 cnn layer를 통과할 수 있도록, shape을 조정해준다. 또한, residual connection을 위해서 cnn layer에 입력하기 전conv_input 값을 미리 저장해둔다.
for loop을 돌면서 conv_input값이 다시 들어가야 하기때문에 주석에 작성한 것처럼 shape을 조절해준다. (batch_size, seq_len, hidden_size) 로 입력된 문장의 token들(seq_len)에 맞는 각각의 embedding vector(hidden_size)로 shape을 맞춰주어 마지막에는 이전과 동일한 linear layer를 거쳐서 start_logit과 end_logit을 계산하게끔 해주었다.
생각보다, 오픈 소스 코드에서 많은 부분을 고치지는 않았고, conv layer를 선언하는 부분이나, forward에서 linear layer에 입력되기 전까지의 과정만 추가하면 되어서 구현하는데 큰 어려움은 없었던것 같다.
결과
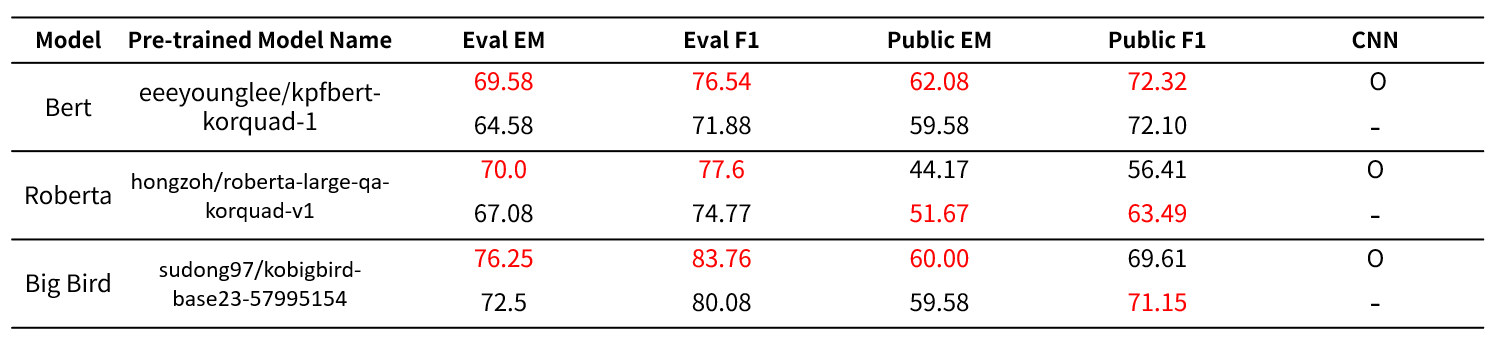
실제 결과 는 위와 같았다. Bert모델에서는 리더보드에서의 public score나 train set에서의 eval score모두 상승하는 것을 확인할 수 있었지만, 오히려 Roberta계열은 오버피팅 되는 것을 확인할 수 있었다. 그리고, Big Bird 계열 모델 역시 학습하는 과정에서의 평가 결과는 성능이 올랐지만, 대회 public data에서 근소하게 성능이 오르거나(public EM), 아예 떨어지는 것을(public F1) 확인할 수 있었다.
https://github.com/dongspam0209/ODQA/
Reference
https://huggingface.co/docs/transformers/tasks/question_answering
https://huggingface.co/docs/transformers/model_doc/bert#transformers.BertForQuestionAnswering
https://www.samsungsds.com/kr/event/techtonic2020.html
