
Sparse Embedding의 한계
먼저, passage embedding은 우리가 흔히 아는 글, 구절을 벡터로 표현하는 것을 의미한다. 여기서, 두가지 대표적인 방법으로 표현이 가능한데, sparse embedding과 dense embedding이 있다. sparse와 dense의 뜻은 각각 드문드문한 밀집한의 뜻을 가지고 있다.
여기서, sparse embedding이 무엇인지, 한계점이 무엇인지 간단하게 짚어보자.
이전 포스트에서 다룬 TF-IDF와 BM25는 모두 sparse embedding이다.
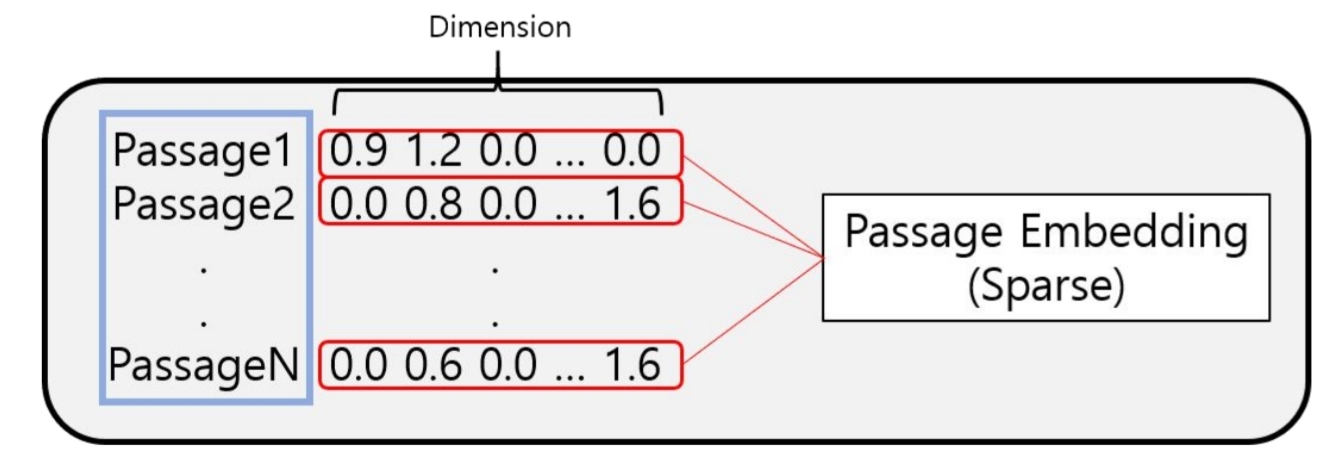
위 사진에서, Dimension은 모든 vocab내 단어를 의미한다. 각 단어에 TF-IDF값을 곱하기 때문에, Passage 1에서 없는 단어에 대해서는 0.0 값이 저장되어 있는 것을 확인할 수 있다. 문서내에 존재하는 단어에 대해서만 값을 가지고 있기 때문에, Sparse Embedding (드문드문한 임베딩) 인 것이다. 어떤 한계가 있을까?
- 차원의 수
일단, 차원의 수가 너무 크다. 모든 passage를 커버하기 위해서는 vocab이 점점 사이즈가 커질 수 밖에없다. 하지만, 이는 compressed format으로 어느정도 극복이 가능하다.
compressed format은 non zero 부분의 위치와 값만 저장하는 것이다. 따라서, 0.0으로 저장되어있는 부분을 모두 저장할 필요는 없다.
- 문장 내 단어의 유사성 반영
사실 sparse embedding은 어떻게 보면, 원 핫 인코딩과도 유사하다고 볼 수 있다. 유사한 단어에 대한 반영이 힘들다. 각 단어가 출현한 빈도에 의해 산정된 값들이기 때문에, 문장의 문맥을 전혀 포함하지 못한다. 따라서, 같은 의미를 가진 단어에 대해서도 불확실한 score가 나올 수 있는 것이다.
Dense Embedding이란?

sparse embedding을 보완하기 위한 방법이다. 마찬가지로, 글을 벡터화하는 방법이다. 더 작은 차원의 고밀도인 벡터로 문단을 표현하는 것이다. 대부분의 요소가 0이 아닌 값이다. 따라서, 각 차원이 하나의 단어를 가리키는 것이 아닌 복합적인 의미를 가지고 있다.
무조건 sparse embedding이 나쁘다는 것은 아니다. 각각의 임베딩 방식은 장점과 단점이 존재한다.
| Sparse Embedding | Dense Embedding |
|---|---|
| 장점 | 장점 |
| - 중요한 term들이 정확히 일치해야 하는 경우 성능이 좋음 | - 단어의 유사성이나 문맥을 파악해야 하는 경우 성능이 좋음 |
| - 임베딩이 구축되고 나서 추가적인 학습이 필요 없음 | - 학습을 통해 임베딩을 만들고 추가 학습이 가능함 |
| - 0이 많은 sparse 벡터 형식으로 저장하여 일부 저장 공간 절약 가능 | - 상대적으로 낮은 차원에서 정보를 압축하여 표현하므로 계산 효율이 좋음 |
| 단점 | 단점 |
| - 차원이 매우 커서 메모리 사용량이 많음 | - 학습에 많은 데이터와 시간이 필요하며, 초기 학습 과정이 복잡함 |
| - 의미적으로 다른 단어 간의 유사도를 반영하기 어려움 | - 고유한 용어나 드문 단어에 대해 일반화된 표현을 제공하여 정보 손실 가능성 있음 |
| - 특정 도메인이나 용어 집합이 고정된 경우에만 적합함 | - 특정 문맥에 강하게 의존하여 다양한 도메인에서 성능 저하 가능성 있음 |
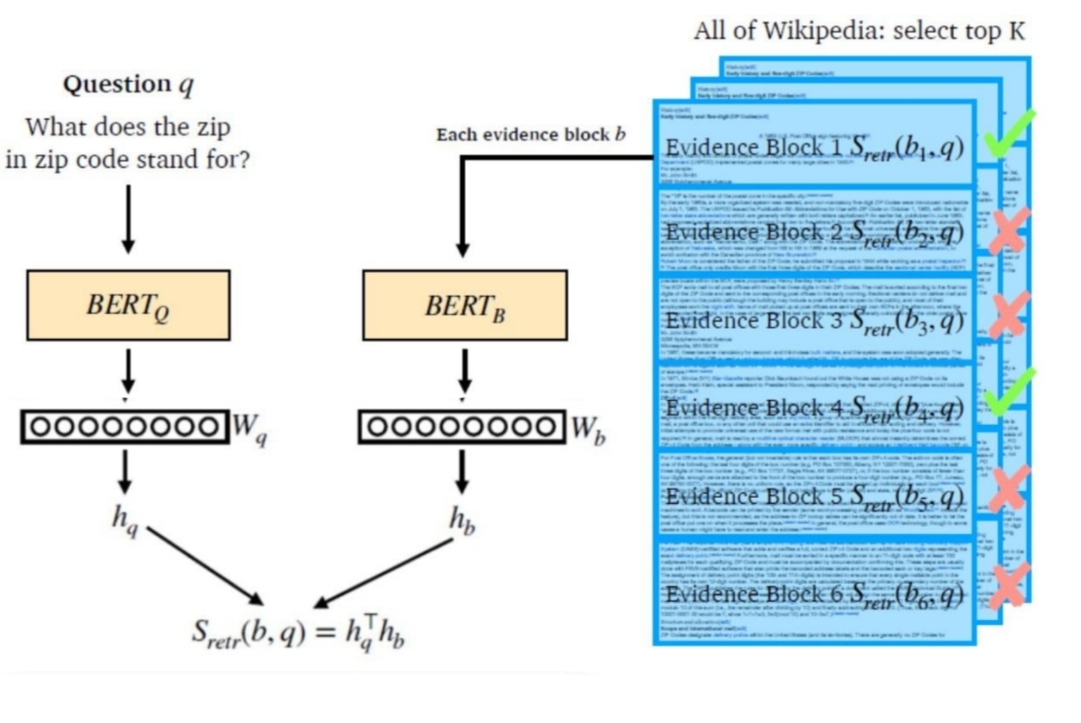
생각보다 어렵지 않게 dense passage retrieval은 이뤄진다.
question에 대한 임베딩을 수행할 모델과 passage에 대해 임베딩을 수행할 모델 두가지로 나뉜다. 여기서 두 모델은 서로 다른 모델을 쓸수도있고, 같은 모델을 쓸 수도 있다.
주어진 질문 에 대해 가장 관련성 높은 지문을 정확하게 찾는 것이 목표다. 따라서, 질문 와 관련된 지문 는 높은 유사도를 가지게 하고, 관련 없는 지문인 들은 낮은 유사도를 가질 수 있게 학습해야한다.
- Object Function
- 어떠한 질문 , 이와 관련된(=positive) 지문 , 관련이 없는(=negative) n개의 지문 로 이루어져 있음
- NLL (Negative Log-Likelihood) Loss를 사용해서 최적화
이 손실 함수를 최소화하는 과정에서 모델은 질문과 관련된 지문과의 유사도는 최대화하고, 관련이 없는 지문과의 유사도는 최소화하도록 학습된다.
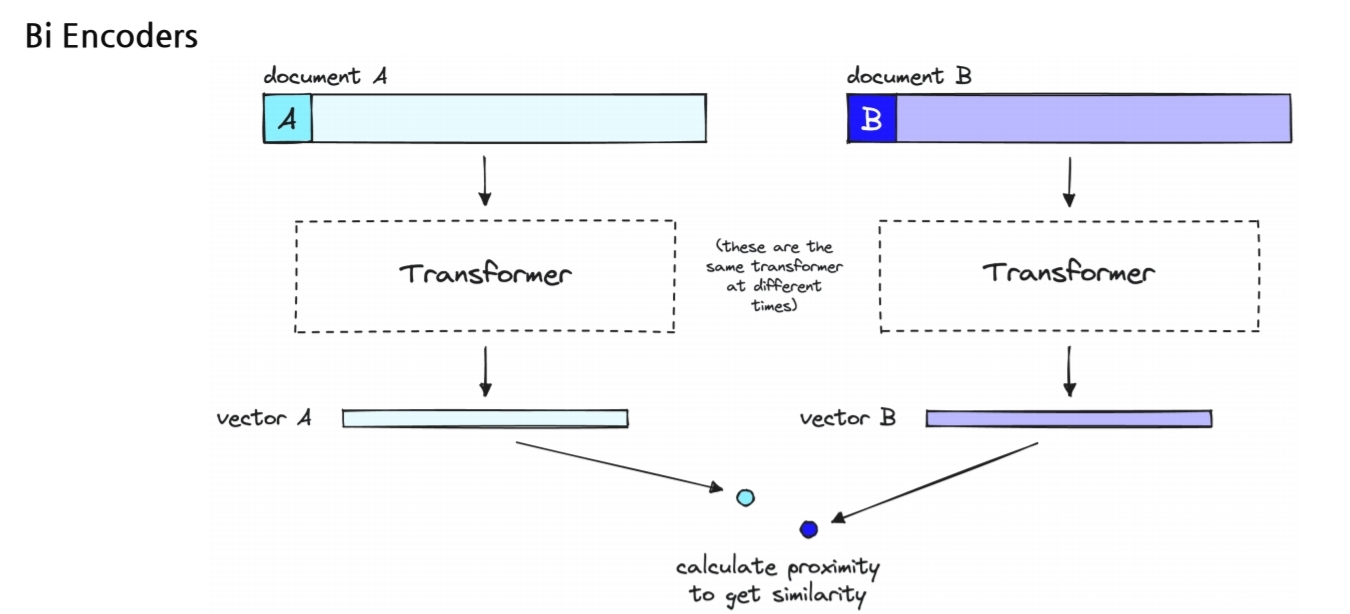
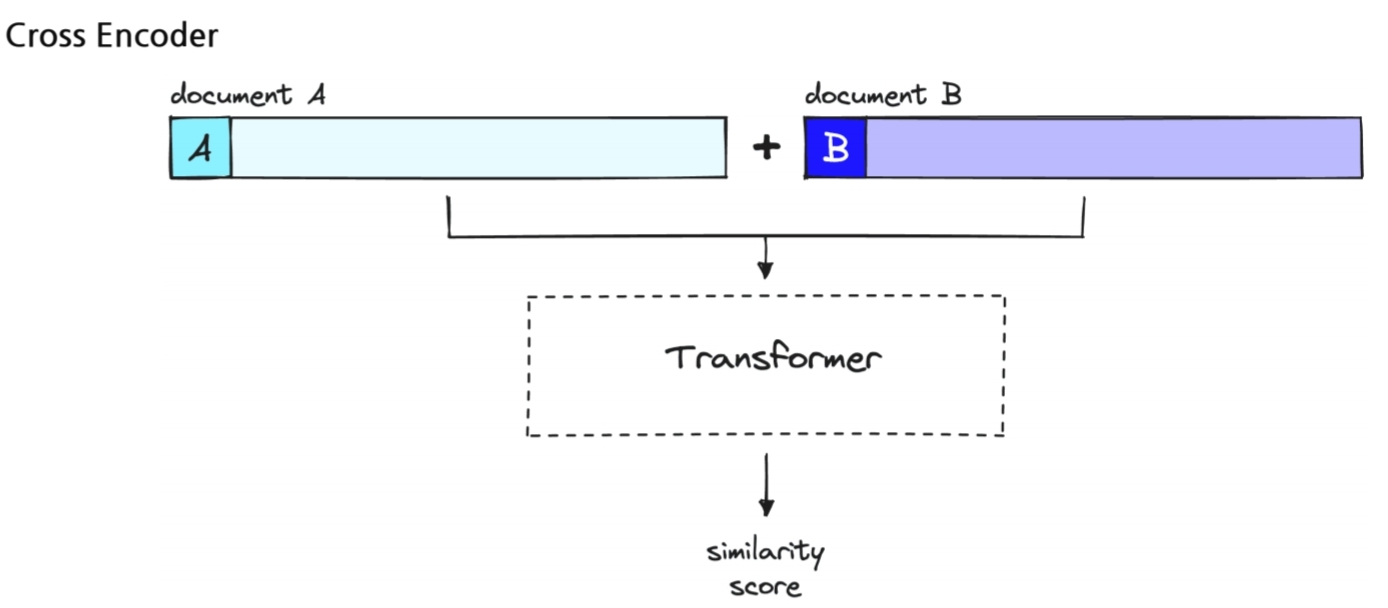
여기서 중요한 다른 포인트는 바로 model이다. 연구목적에서 한번 실험하고 끝날땐 상관없지만, 상용화된다면 query가 들어올때마다 question과 context 쌍을 학습하는 것은 사실상 불가능하다. 매 query마다 진행해야하기 때문이다. 따라서, 두가지의 encoding 방법이 있는데,그 중에서 서로 다른 모델을 쓰는 경우를 선호한다.
passage용 모델은 미리 embedding해두고, query만 들어올때마다 embedding하는 방법을 실제론 사용한다고 한다.
쉽게 두가지 차이는 딸기요플레를 딸기한입 먹고 플레인 맛인 요플레로 먹거나, 딸기요플레로 먹거나 차이다.
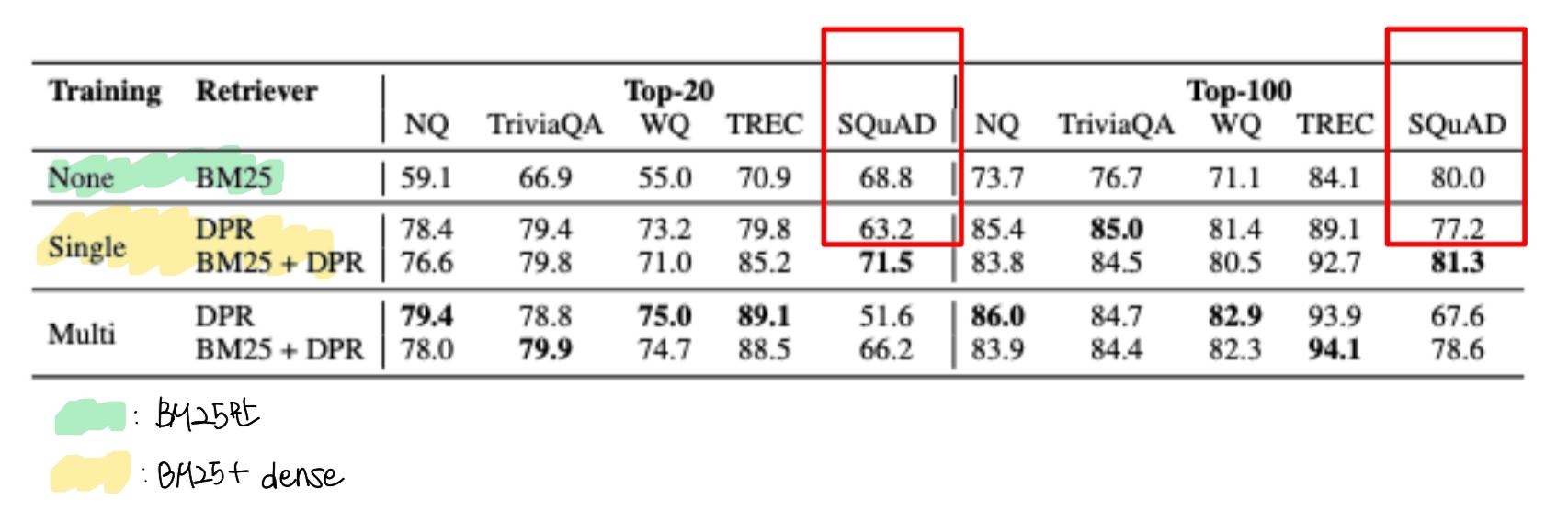
Dense Retreival의 경우 SQuAD데이터에서 좋지않은 성능을 보인다. 그 이유는 데이터셋이 생성된 이유에 있다. 데이터셋을 만들떄, passage를 보고 question을 만들기 때문에 passage에 있는 어휘가 question에서 같은 어휘로 겹치는 가능성이 높았던 것이다. 따라서, BM25 (sparse embedidng)가 훨씬 더 좋은 성능을 보인 것이다.
Upgraded Retrieval
위에서 다룬 두가지 retrieval은 상호보완적인 성향을 가진 방법들이다.
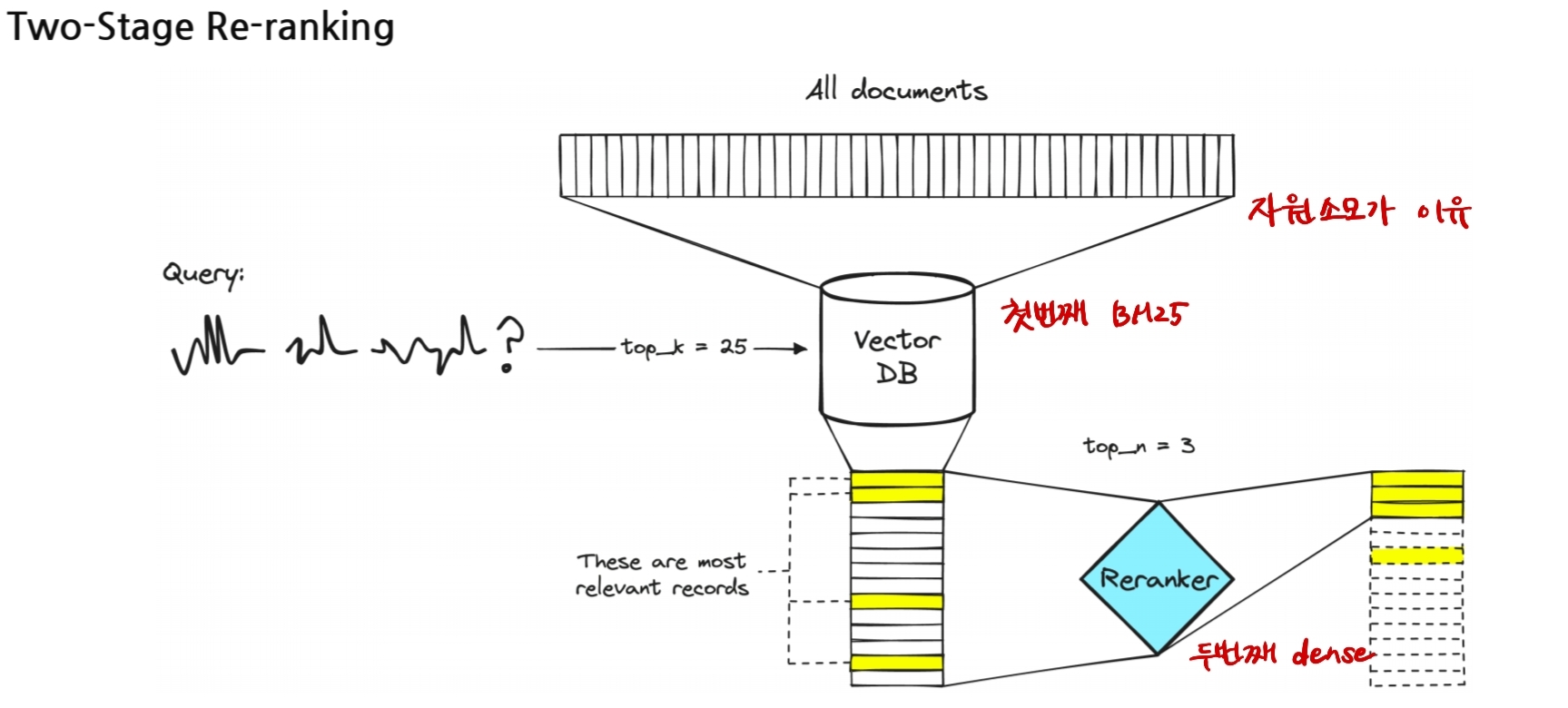
따라서, 두가지 방법을 모두 사용한다. BM25를 사용하여 먼저 top k개의 문서를 ranking한 이후 Dense Retreiver를 사용해서 마지막으로 최종 문서를 retrieval하는 방법은 two-stage Re-ranking으로 두 상호보완적인 방법을 모두 사용할 수 있게 해준다.
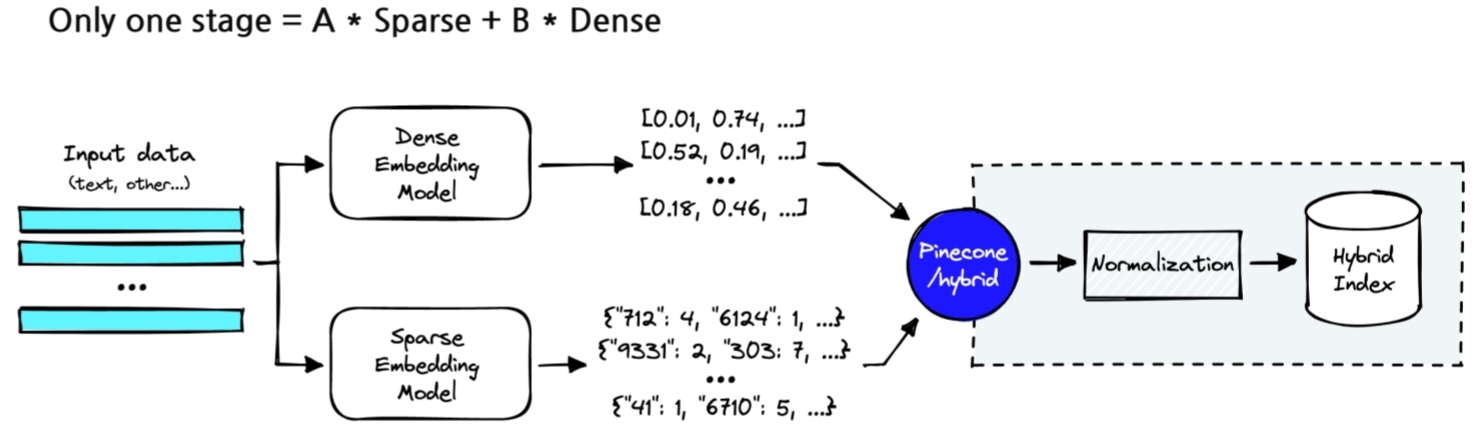
다른 방법으론 가중치를 부여하는 방법도 존재한다. sparse embedding과 dense embedding의 가중치를 모두 부여해서 하이브리드 방법으로 찾는 방법이다.
Reference
https://arxiv.org/abs/2004.04906
https://www.pinecone.io/learn/series/rag/rerankers/
https://www.pinecone.io/learn/hybrid-search-intro/
