
F1 score란
F1 score는 분류 모델에서 사용되는 머신러닝의 평가지표이다.
Accuracy
뜻 : 정확도. 즉 얼마나 정확한지를 나타내는 지표다. 예를 들어 생각해보자.
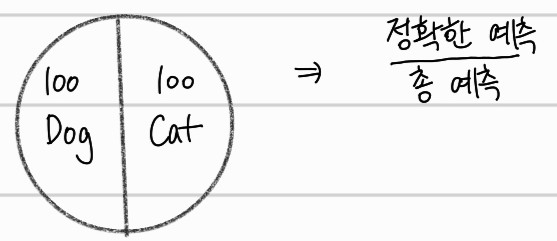
위 처럼 개와 고양이의 사진 각각 100장에 대해서 분류하는 모델을 학습했다고 가정하자. accuracy는 총 예측한 case중 올바르게 예측한 case를 나타낼 것이다. 여기서 문제는 바로 데이터의 불균형이다. 현재는 고양이와 개의 사진을 각 100장씩 사용하며 균등한 분포를 갖고 있지만, 만약에 고양이 사진만 199장이고, 개 사진은 1장만 존재할때도 같은 방법으로 평가해도 되는걸까?
불균형한 데이터에 대한 Accuracy 지표의 위험성
위의 예시를 이어서 생각해보자, 만약 모델이 입력된 모든 사진에 대해서 고양이라고 분류를 한다면 과연 이는 올바른 예측을 한 것일까? 모든 입력에 대해 고양이라고만 분류해도 오답은 단 1장만 존재하게 된다.
모델의 성능이 매우 나쁘지만, Accuracy는 99% 이상의 정확도를 보이게 된다.
즉 불균형한 데이터에 Accuracy지표를 사용한 평가는 좋지 않다는 것이다. 즉, 불균형한 데이터에 대한 모델의 성능 평가를 진행하기 위해 F1 score를 사용하는 것이다.
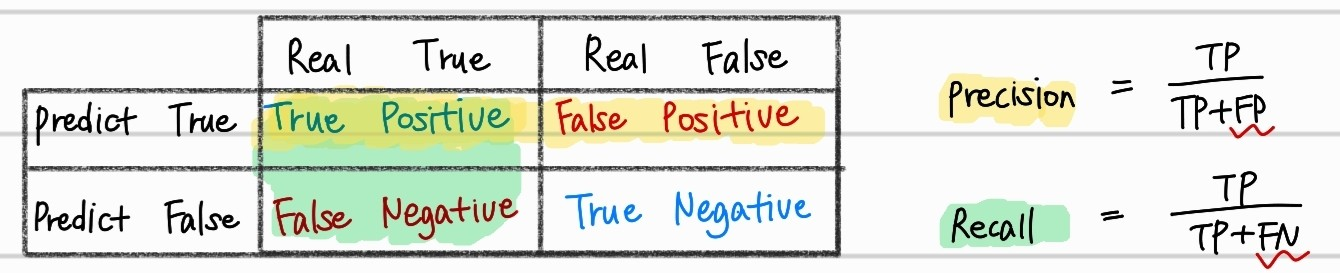
Precision
위의 수식에서 볼 수 있듯이 Precision(재현율)은 모델이 True로 예측한 경우중에서 실제로도 True인 경우의 수다. 이 Precision값이 높다는 것은 model이 pure하다는 것을 의미한다. 모든 positive case를 찾지는 못할 수 있지만, 적어도 model이 positive라고 예측한 값들은 모두 positive인 것을 의미한다. 조금 신중하게 positive라고 예측해, 예측을 한다면 거의 맞는다고 생각하는 것이 이해하기 쉬울 것이다.
Recall
Recall은 관점이 살짝 달라진다. Precision과 매우 유사하지만, Recall은 실제로 True인 경우 중에서 모델이 True라고 예측한 것의 비율이다. 분모에 False Positive가 포함되지않기 때문에, Recall값이 높다는 것은, 실제로 False인 것을 몇개 True로 분류하더라도, 전체적으로 True로 분류하는 data가 많을 수록 높아지기 때문에, total data에서 True case를 잘 찾는 것을 의미한다.
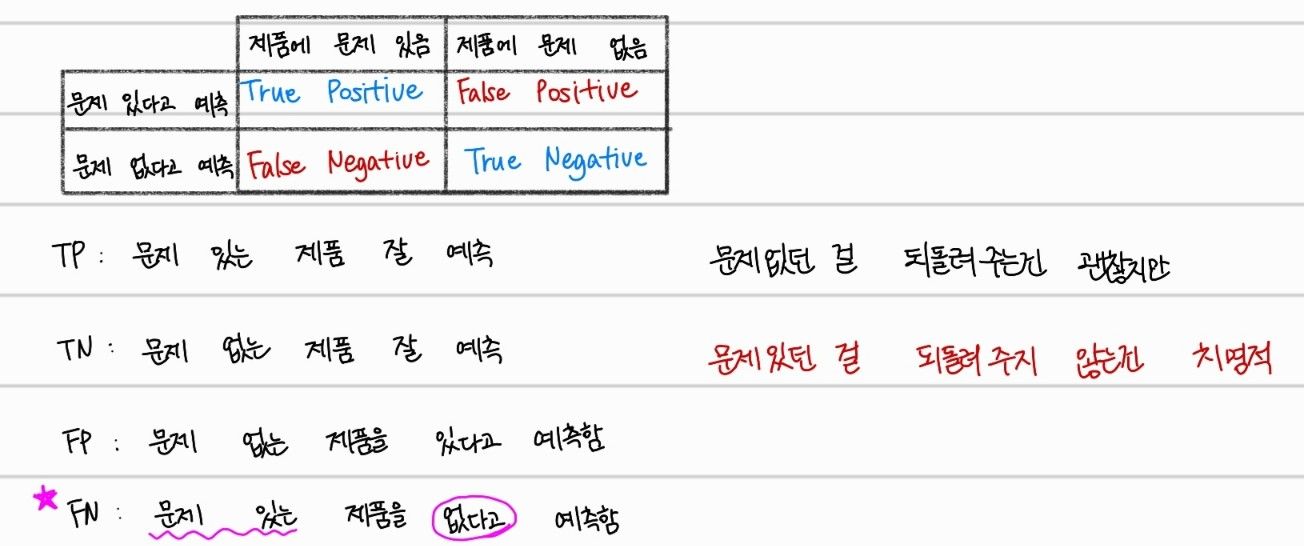
제품을 공급하는 어떤 회사에선,
- 문제가 없던 제품을 되돌려주는 것
- 문제가 있는 제품을 되돌려주지 않은것
위 두 경우중 후자가 훨씬 치명적인 정책상 실책이 될 수 있다. 존재하는 불량품보다 더 많은 양의 물품을 불량품이라고 판단하는 것은 오히려 괜찮지만, 불량품인데 불량품이라고 판단하지 못하면, 즉 Recall값이 낮으면 고소를 받을 수도 있다.
Precision-Recall Trade off
이상적인 모델은 positive한 것을 모두 제대로 분류하고(Recall), 그리고 positive한 것만 제대로 분류하면(Precision) 좋지만 두가지를 모두 높이는 것은 쉽지 않은 일이다.
F1 score
위의 Precision과 Recall의 조화평균으로 이루어진 F1 score는 불균형한 데이터에서 모델을 평가하기에 적합한 평가지표가 된다.
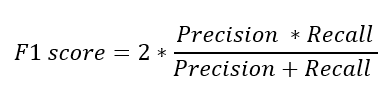
📌조화평균인 이유
: Precision과 Recall값 중 더 작게 나온 값에 영향을 더 받기 위해서이다.
