
오늘은 pre-training 및 fine-tuning에 대한 논문인 GPT-1에 대한 글을 읽어보고 정리해보았다.
❗Before Read ❗
- 완벽하게 순서대로 논문을 인용한 것이 아니고 부분부분 첨부하여 순서가 조금 다르거나 없는 부분이 있을 수 있습니다.
Abstract / Introduction

자연어 이해 task는 text 구문간 관계, 질의응답, 유사도 평가, 문서 분류 등 다양한 분야를 포함한다. 하지만, unlabeled text는 많은 반면, labeled text는 현저히 부족해서 특정 task에 맞게 학습한 모델이 적절한 성능을 내는 것이 힘들다. 마치 문제는 많지만 정답지는 부족한 것과 같은 것이다.

저자는 다양한 unlabeled text에 대해 생성적으로 사전학습을 진행한 후, 특정 작업에 맞게 미세조정하는 것이 큰 성능향상을 보였다고 한다. 해당 논문에서 사전학습과 미세조정의 개념이 도입되었다고 봐도 될 것 같다.

이전 접근과 다르게 효과적인 전이학습을 위해서 task에 맞는 input 변환을 사용했다. 그리고 model의 실질적인 구조에는 거의 변화가 필요하지 않았다.
이러한 task에 관계없이 일반화된 model은 다른 task에 특화되어 구조를 수정한 model보다 오히려 더 좋은 성능을 보였다고 한다.

annotate된 자원이 부족한 도메인은 성능이 제한되었다. 이를 해결하기 위해서 label이 없는 데이터를 학습할 수 있는 model을 써보기로 한 것이다.
pre-trained model에 annotate된 데이터도 사용하게 되면 큰 폭으로 성능향상을 이룰 수 있다.

현재까지의 기술들에는 한계가 있었는데, 먼저 첫째로 사전학습과정에서 최소화할 optimization objectives(목적함수) 가 확실하지 않다는 것이다.
앞으로 진행할 전이학습에 유용하게끔 text 표현을 잘 학습할 수 있도록 도움을 줄 사전학습시 목적함수에 대한 정의가 필요하다.
두번째로, 전이학습 과정에서 가장 효과적인 방법에 대한 합의가 없다는 것이다. 현재 존재하는 기술들은 task에 특화된 모델 구조로 변화시키거나, 보조 학습 목표로 추가하거나, 복잡한 학습 체계를 사용했다.

해당 논문에선 unsupervised pre-training과 supervised fine-tuning을 사용해서 semi-supervised로 언어 이해 task에 접근했다.
먼저 unlabeled 데이터에 language modeling을 목표로 신경망 모델의 초기 파라미터를 학습한다. 그 후, 학습 목표에 맞는 supervised objective을 사용해 이 초기 parameter들을 조정한다.

Transformer 모델을 사용하고, 전이학습에서는 구조화된 text 입력을 token들의 단일 연속 입력으로 처리하는 traversal-style 방법을 사용해 task에 특화된 input을 구축한다.
위 방법으로 pre-training과 fine-tuning을 진행한 모델이 다양한 task(자연어추론,QA,문맥유사도 판별,text 분류)에 대해서 SOTA 보다 높은 성능을 보였다고 한다.
Related Work

기존의 접근들은 unlabeled data를 단어나 구 level의 통계로 계산하여 사용했다. 이는 supervised model에 feature로 사용되었다.
최근에는 unlabeled 데이터에 학습된 단어 임베딩들을 사용하여 다양한 task에 대한 성능을 향상시켰지만, word level 이상의 의미를 학습하고 활용하는 연구가 진행되고 있고 phrase level, sentence level의 임베딩을 사용해서 다양한 target task에 맞는 vector 표현으로 text를 인코딩할 수 있다.


unsupervised pre-training은 semi-supervised learning의 특별한 경우다. unsupervised pre-training은 supervised learning의 목표를 수정하는 대신 좋은 초기화 지점을 찾는 것이 목표다.
pre-training이 정규화처럼 동작하며 더 좋은 심층 신경망의 일반화를 가능하게 한다는 것을 입증했다.
정리하자면, pre-training 과정은 unlabled data를 활용해서 통상적으로 사용할 수 있는 일반화된 model을 만드는 것이다.
이 과정에서 더 긴 언어 구조를 커버할 수 있는 Transformer model을 사용했다.
또한, pre-trained 언어 모델이 supervised learning에서 보조 특징으로 사용하는 경우도 제시한다. 이는 각기 다른 task마다 많은 새로운 파라미터를 포함하지만, 전이학습과정에서 model 구조의 변화는 최소화한다.

보조 학습 목표(unsupervised)를 추가하는 것은 semi-supervised 학습의 또 다른 형태다.
Collobert와 Weston의 초기 연구는 POS 태깅, chunking, 개체명 인식, 언어 모델링 같은 다양한 보조 NLP 작업을 사용해 의미역 결정(semantic role labeling)을 개선했다.
최근에는 Rei가 목표 작업의 학습 목표에 보조 언어 모델링 목표를 추가해 시퀀스 라벨링 작업에서 성능 향상을 입증했다.
이 논문을 작성한 팀은 물론 언어 모델링 목표를 보조 목표를 사용했지만, 비지도 사전 학습만으로도 이미 목표 작업과 관련된 여러 언어적 측면을 학습할 수 있었다.
여기서 목표 및 목적에 해당하는 부분은 Loss function으로 봐도 된다.
Framework
학습과정은 아래의 두 순서로 진행된다.
- 큰 규모의 text 말뭉치로 대용량 언어모델(LLM) 학습하기
- label이 있는 데이터를 사용해, model을 각 작업에 맞게 fine-tuning하기
Unsupervised pre-training

unsupervised pre-training은 실제로 논문에 기재된 model의 구조와 함께 보는 것이 수식의 이해에 도움이 될 것 같다.
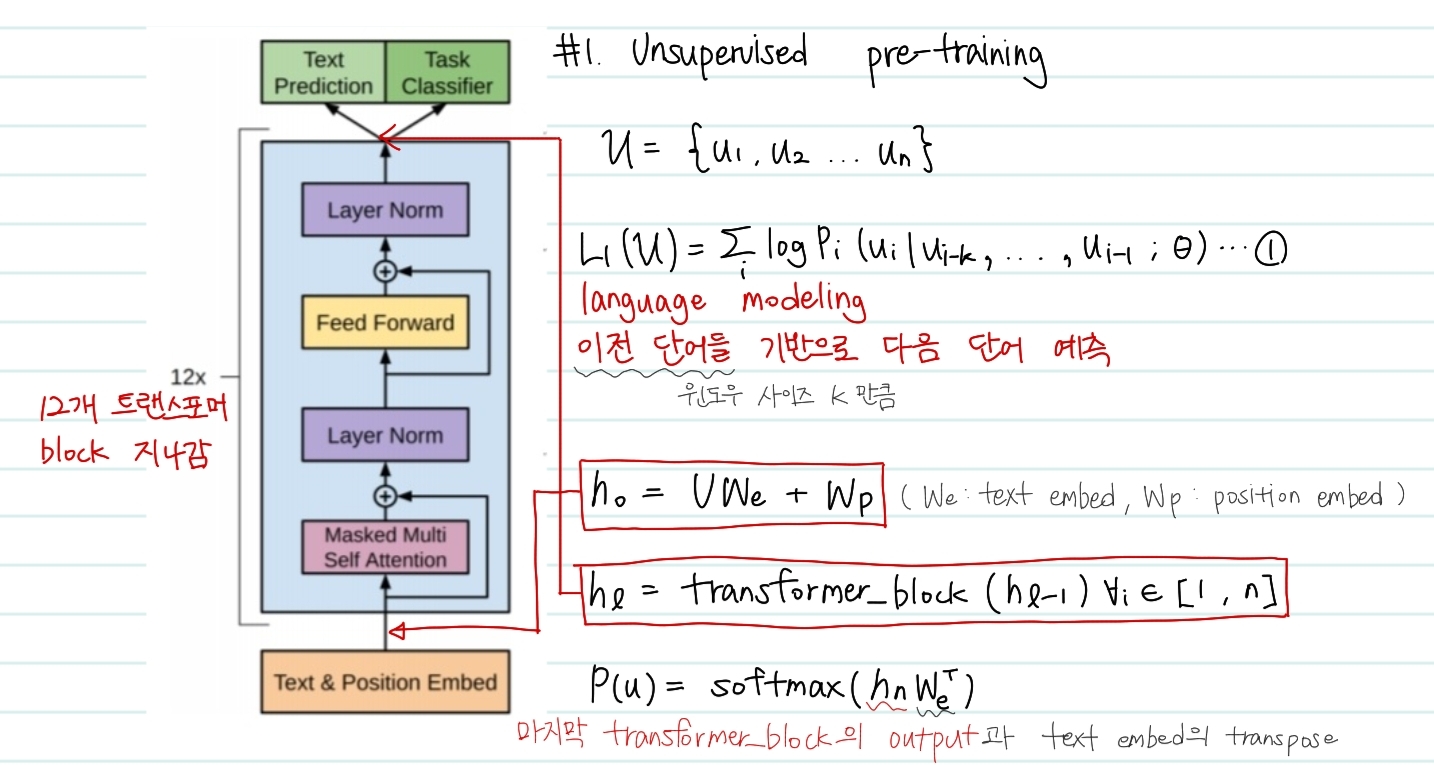
pre-training에서 제일 중요한 점은 바로 language modeling이다. Language modeling이란 이전 단어를 기반으로 하여 다음 단어를 예측하는 것이다.
여기서 모델은 Transformer의 디코더 부분을 사용하였다. 입력된 문장에 대해서 Masked Multi Self Attenttion을 수행하고, position-wise feedfoward layer를 지난다. 논문에 의하면 해당 디코더 구조는 12번 반복된다고 한다.
이 첫번째 likelihood 함수는 바로 pre-training 과정에서 언어모델이 다음 단어를 올바른 단어로 예측할 확률을 높이기 위한 가능도이다. 해당 값을 최대화 시키는 방향으로 를 학습하게 된다. (는 transformer 모델의 가중치)
그렇다면 가능도는 어떻게 계산될까 위의 수식들은 복잡해보이지만 사실 저 네트워크 구조를 통과하는 것을 수학식으로 작성한 것 뿐이다. 과정은 아래와 같다.
1. Text & Position Embed
첫번째 수식은 Text & Position Embed에 해당하는 부분이다. 와 는 각각 text, position embed를 가리키고 transformer 모델 구조에 처음으로 들어가는 input을 의미한다.
2. Transformer block (12ea)
두번째 수식은 12개의 transformer_block을 통과하는 것을 의미한다. 이전 block에서의 output이 input으로 들어가는 것을 알 수 있다.
3. Language modeling
최종적으로 transformer 모델을 통과한 output과 처음 입력시 사용한 text embed값을 활용해 다음 단어를 예측하게 된다.
Supervised fine-tuning

unsupervised pre-training을 한 후, label이 존재하는 데이터셋을 통해서 남은 fine-tuning을 진행한다. pre-training과 마찬가지로 fine-tuning도 그림과 함께 살펴보자.

먼저 앞서 pre-training을 통해 어느정도 보편화 model이 만들어졌다고 생각하고 이제 label이 있는 데이터셋을 사용하게 된다. 이는 input token sequence 와 y로 구성된 데이터셋이다. 위의 그림에서 에 해당하는 dataset이다.
fine-tuning에서의 예측확률
transformer_block을 모두 통과한 최종 output인 이 task에 맞게 사용하기 위해서 끝단에 추가한 linear layer인 를 통과한 후 softmax취한 값을 최종 예측확률로 사용하게 되는 것이다.
fine-tuning에서의 loss함수
이로써 전체 모델의 구조를 바꿀 필요도 없고 단순히 가중치를 가지는 linear layer만 추가해도 된다. 여기서 흥미로운 점은, 보조 목표를 포함시키는 것이다.
보조 목표를 포함한 최종목표
처음에 pre-training을 통해 얻은 language modeling을 보조 목표로 설정하고 전이학습을 진행하게 되면 supervised model의 일반화 성능을 높이고, 수렴하는 속도를 높이는데 도움을 주었다고 한다.
Task-specific input transformations
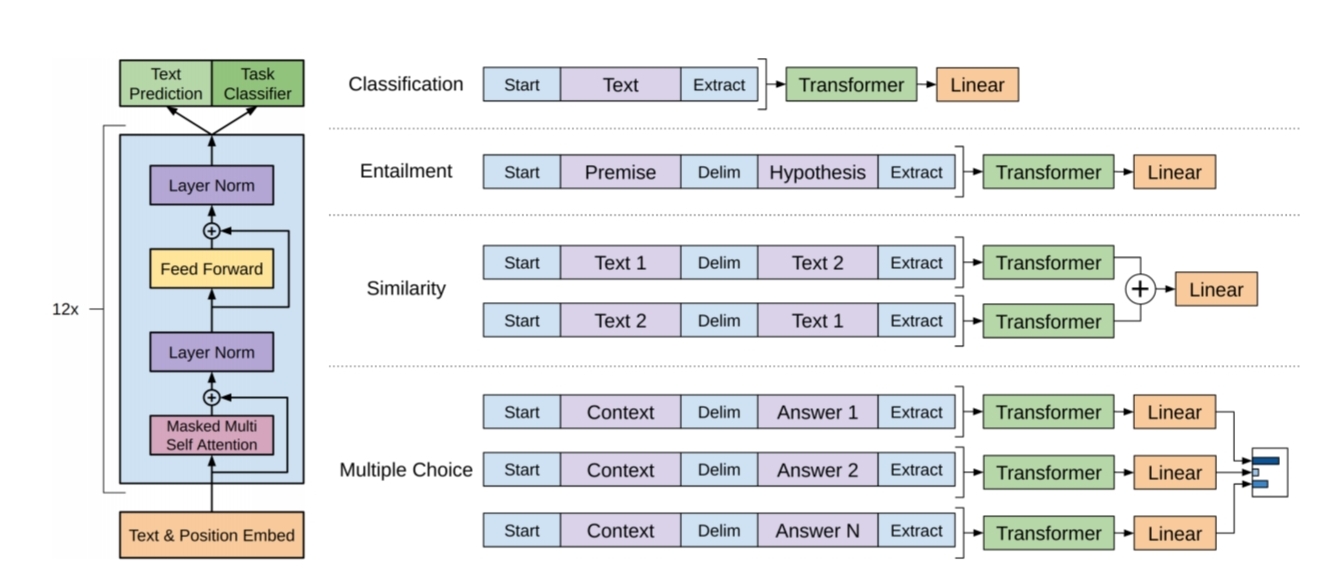
위 사진의 왼쪽은 transformer모델의 구조와 학습 목표들을 나타낸 것이다. 그리고 오른쪽은 다른 task마다 fine-tuning할때의 input 변환이다. 모든 구조화된 입력을 pre-trained model이 처리할 수 있게 sequence로 변환하고 linear, softmax layer를 활용한다.

classification의 경우 위의 예시와 같이 해결이 가능하지만, (document,question,answer )와 같이 3쌍이 한개의 instance에 존재하는 QA와 같은 task는 input이 달라져야한다.
이전 연구들은 task마다 다른 특화된 구조를 학습하는 방법을 제안했지만, 해당 논문은 pre-trained model을 적극활용하며 input을 sequence로 이어 붙이는 것으로 model 구조를 거의 변화시키지않고 fine-tuning을 진행했다.
위의 그림은 이를 시각적으로 표현한 것이고, 모든 변환에는 랜덤으로 초기화된 시작,종료 토큰이 추가된다.

- Text entailment
전제(Premise)와 가설(Hypothesis)의 token sequence를 이어 붙이고 그 사이에 구분자를 넣는다.
- Similarity
비교되는 두 문장의 순서가 중요하지 않기 때문에, 이를 반영하기 위해서 두 순서를 바꿔서 하나 더 포함시킨다. 이 두가지 표현들을 각 요소별로 더한후 linear layer에 전달한다.
- QA, Commonsense Reasoning
문서(context),질문(question),답변(answer)가 주어진다. 문서와 질문을 각각 가능한 답변과 이어 붙이고 구분자를 추가해서 context;question$;answer 와 같은 sequence를 만든다. 그후 softmax layer를 통해서 가능한 답변에 대한 분포를 생성한다.
Experiments

현 SOTA 방법들과 본 논문에서 제안하는 model의 성능을 비교한 것으로 여러 자연어 추론 task에 대해서 더 좋은 결과를 보이는 것을 확인할 수 있었다. 심지어 5개의 model을 앙상블한 model보다 더 좋은 성능을 보였다.
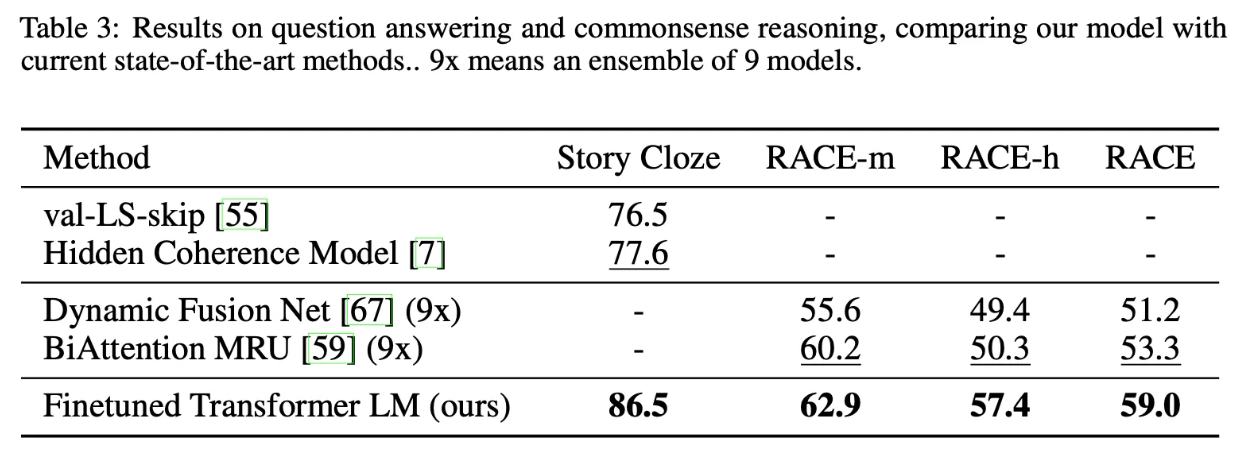
위는 QA, commonsense reasoning task에 대해서 비교한 지표이다. 마찬가지로 SOTA를 기록중이던 다른 model보다 더 좋은 성능을 보였다.
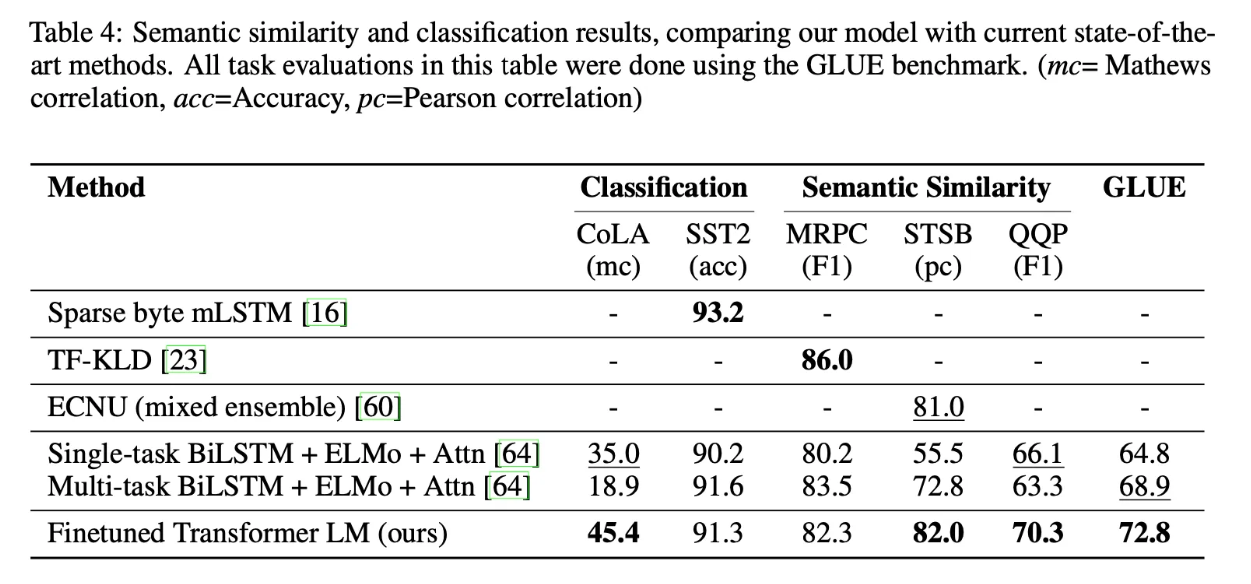
마지막으로 문맥 유사도 판별 및 classification model에서도 특정 dataset을 제외하고 대부분 더 좋은 성능을 보였다. 여기서 유의할 점은 GPT는 디코더 기반 model임에도 인코더 기반 model이 더 하기 쉬운 task에 대해서 꿀리지 않는 성능을 보였다는 것을 인지할 수 있다.
Analysis
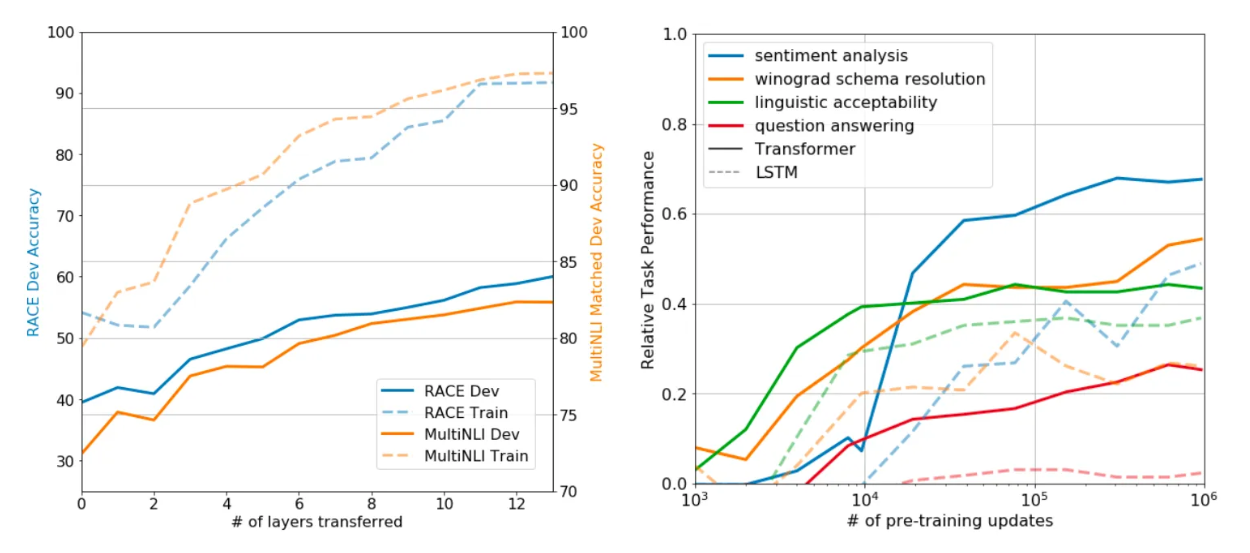
왼쪽 그래프는 Transfer에 사용한 Layer 개수에 따른 성능을 측정한 그래프로, Layer의 개수가 많을수록 성능이 좋아지는 모습을 보인다. 이는 Pretrained 정보를 많이 사용할 수록 Fine Tuning 했을때의 성능이 좋아짐을 의미한다.
오른쪽 그래프는 Zero Shot 성능을 측정한 그래프로, x축은 Pre-Training을 진행한 정도를 의미한다.
- 실선 : Transformer
- 점선 : LSTM
Pre-Training을 많이 진행할수록 성능이 좋아지고, Transformer 구조가 LSTM보다 높은 성능을 보인다.
Reference
https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
https://www.notion.so/imlabswu/Improving-Language-Understanding-by-Generative-Pre-Training-5460352d9675496d92953ca008585206?pvs=4
