
오늘은 inference level에서의 효율성에 대해 고민하여 좋은 결과를 낸 논문인 LLaMA에 대한 글을 읽어보고 정리해보았다.
❗Before Read ❗
- 완벽하게 순서대로 논문을 인용한 것이 아니고 부분부분 첨부하여 순서가 조금 다르거나 없는 부분이 있을 수 있습니다.
Abstract
LLaMA는 7B에서 65B 사이즈의 언어모델이다. 공개적으로 사용 가능한 데이터셋으로 SOTA 모델들을 학습할 수 있다는 것을 보여준다. LLaMA-13B 모델은 GPT-3를 대부분의 기준에서 능가하고, LLaMA-65B는 Chinchilla-70B나 PaLM-540B와 같은 최고의 모델들과 경쟁이 가능하다.Introduction
LLMs가 등장하면서 few-shot learning과 같은 특성도 등장하고 있다. 이는, 더 많은 파라미터 수가 더 좋은 성능으로 이어진다는 가정을 가지고 있다.


하지만, Hoffman은 최근 연구에서 주어진 자원 한도 내에서 가장 큰 모델 보단 더 많은 데이터를 학습한 작은 모델이 최고의 성능을 가진다고 밝혔다.


하지만, Hoffman은 학습 예산에 맞춰 최적의 dataset 크기와 model 크기를 제안했지만 추론 예산은 고려하지 않았다.
사실 추론 예산 관련된 부분이 언어 모델을 제공할때 더 중요한 부분이다. 따라서, 학습시가 아닌 추론시 가장 빠른 모델이 선호된다. 더 작은 model은 또한, 추론 과정에서 훨씬 값쌀 것이다.
Hoffman은 10B 크기의 model과 200B token을 제안했지만, 7B 크기의 model과 1T token을 사용해 더 높은 성능을 보였다.
앞서 초록에서 언급한것과 같이 LLaMA-13B 는 GPT-3의 성능을 앞섰고, LLaMA-65B는 Chinchilla와 PaLM-540B와 경쟁력을 가졌다.
또한, LLaMA는 공개적으로 접근 가능한 data만 사용하여 학습했다고 한다.
Approach

이전 연구(language models are fewshot learner)에서 사용된 방법과 유사하고, Chinchilla scaling 방법에 영감을 받아서 진행했다.

LLaMA 모델을 학습하는 데에는 공개적으로 접근 가능한 데이터만 사용하였기 때문에 어느정도 제한이 존재했다. 따라서, 다양한 domain의 data가 혼합되어 training set이 구성되었다.
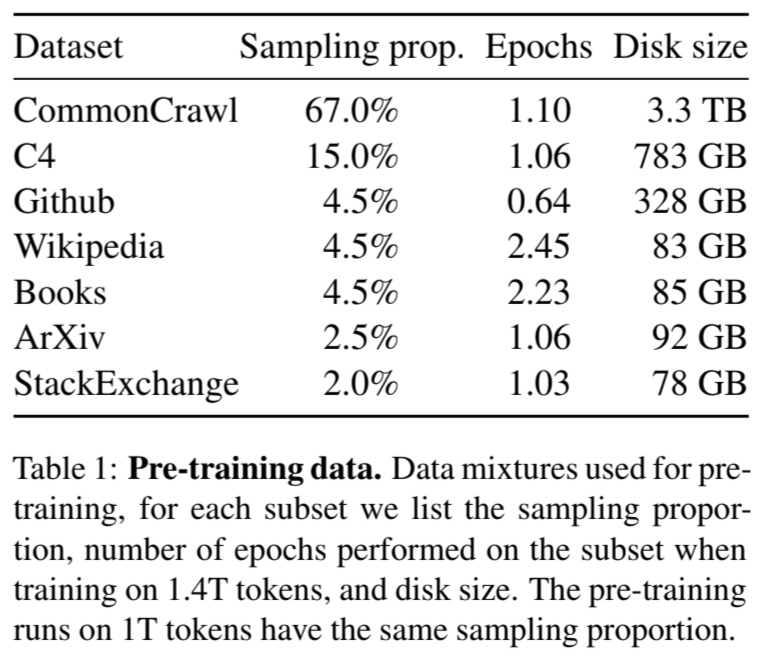
위의 표에 나왔듯이 다양한 dataset이 사용된 것을 알 수 있다.
- CommonCrawl 67%
- CommonCrawl 덤프를 CCNet 파이프라인으로 전처리(2017~2020)
- 전처리 과정에서 중복된 데이터 제거
- fastText 선형 분류기를 이용한 비영어 페이지 제거
- n-gram 언어 모델을 통한 저품질 콘텐츠 필터링 수행
- Wiki에서 참조된 페이지와 무작위로 선택된 페이지를 분류하는 선형 모델 훈련
→ 참조로 분류되지 않은 페이지 제외
- C4 15%
- 중복 제거와 언어식별 포함
- CCNet과 차이는 구두점 유무, 단어 및 문장의 수와 같은 휴리스틱 기반으로 한 품질 필터링
- Github 4.5%
- Google BigQuery에서 제공하는 공개 Github 데이터셋
- Apache,BSD,MIT 라이선스 하에 배포된 프로젝트만 사용
- 라인 길이나 알파벳-숫자 비율과 같은 휴리스틱 기반 품질 필터링
- 정규표현식 사용해 헤더와 같은 불필요한 부분 제거
- 파일 수준에서 중복 제거
- Wikipedia 4.5%
- 2022.06~08 Wikipedia 덤프 추가
- 라틴,키릴문자 사용하는 20개 언어 포함
- 하이퍼링크,주석,기타 형식적인 내용 제거
- Gutenberg 및 Book3 4.5%
- 도서 코퍼스인 Gutenberg과 Book3 추가
- 책 수준에서 중복 제거를 수행
- 90% 이상의 콘텐츠가 중복된 책은 제외
- ArXiv 2.5%
- 과학 데이터 추가 위해 arXiv Latex 파일 처리
- 첫번째 섹션 이전과 참고문헌 제거
- .tex파일의 주석을 삭제
- 사용자 정의 및 매크로를 확장 → 일관성 높임
- Stack Exchange 2%
- 컴퓨터 과학부터 화학까지 다루는 고품질 질의응답 사이트
- 28개의 가장 큰 웹사이트에서 데이터를 가져옴
- HTML 태그 제거하고 점수에 따라 답변을 정렬(내림차순)
위는 모두 dataset에 대한 cleansing 및 취득 과정이다. 중복되어있는 컨텐츠를 제거하는 과정은 거의 모든 data에 적용됐고, 이외에도 정규표현식이나 fastText 선형 분류기 등 다양한 방법으로 cleansing을 진행한것을 확인할 수 있다.

BPE 알고리즘을 사용해 tokenizing하였고, 정확히는 SentencePiece tokenizer를 사용하였다. 모든 숫자는 개별로 찢은 후, 알 수 없는 UTF-8 문자는 모두 byte로 분해했다고 한다.

토큰화 이후 training 데이터셋은 전체적으로 1.4T token을 포함한다. 대부분은 훈련 중 한번 사용되었고, Wikipedia와 Books 도메인만 2 epoch에 걸쳐 사용되었다.

transformer 구조를 기반으로 하고, PaLM같은 모델에서 사용된 다양한 개선사항을 활용했다.

영감 받은 model마다 사용한 방법에 대해 서술하였다.
- GPT3
훈련 안정성을 개선하기 위해, transformer sub-layer의 출력을 정규화하는 대신 입력을 정규화한다. RMSNorm 정규화 함수를 사용한다.
- PaLM
ReLU 비선형성을 SwiGLU 활성화 함수로 교체했다. PaLM에서 사용된 4d차원과 다르게 4d차원을 사용한다.
- GPTNeo
절대적인 position embedding을 지우고, Rotary Positional Embeddings (RoPE)를 각 레이어에 추가한다.
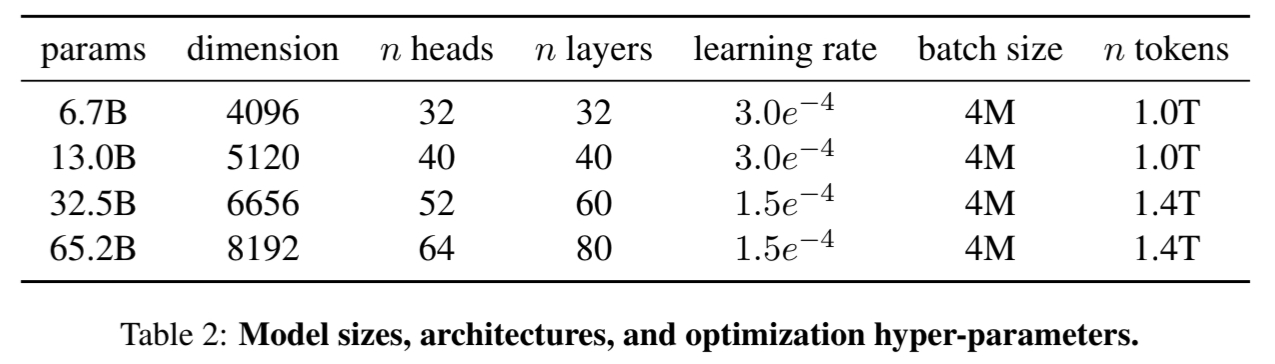
위 표는 하이퍼 파라미터 정보이다.
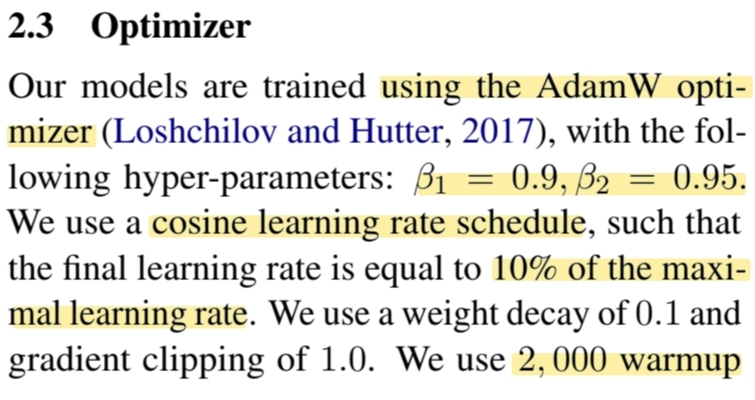

- AdamW optimizer ()
- cosine scheduler : lr 점점 줄어들고, 최대 학습률의 10%로 최종수렴
- weight decay : 0.1
- clipping : 1.0 (gradient 너무 커지는 것 방지)
- warmup steps : 2000
warmup steps는 learing rate를 천천히 올리는 방법이다. 반대로, cosine scheduler 는 learning rate를 천천히 줄이는 방법이다.

모델의 훈련속도를 개선하기 위해서 몇가지 최적화를 적용했다. 먼저, memory 사용량과 실행시간을 줄이기 위해 causal multi-head attention을 효율적으로 사용했다. 이는 xformers 라이브러리에서 제공된다.
attention 가중치를 저장하지 않고, causal 특성을 사용해서 마스킹된 key/query 점수를 계산하지 않는다.
더 효율을 높이기 위해서, checkpointing을 사용하여 backpropagtion 동안 다시 계산되는 activation의 양을 절약한다.
더 정확하게는 linear layer의 output과 같은 계산하기 비싼 연산들은 수동으로 backward function을 구현하여 Pytorch의 autograd를 대신해 학습 효율을 높였다.

model과 sequence의 병렬화를 통해서 여러 GPU에서 처리해 memory 사용량을 감소시켰다. 또한, GPU 간 통신과 activation 계산을 최대한 overlap 시켰다고 한다. 650억개의 파라미터 모델을 훈련할 때, 2048개의 A100 GPU를 사용해서 대략 21일 동안 훈련할 수 있었다고 한다.
Main result
다음은 주요한 결과들에 대한 분석이다.
Common Sense Reasoning
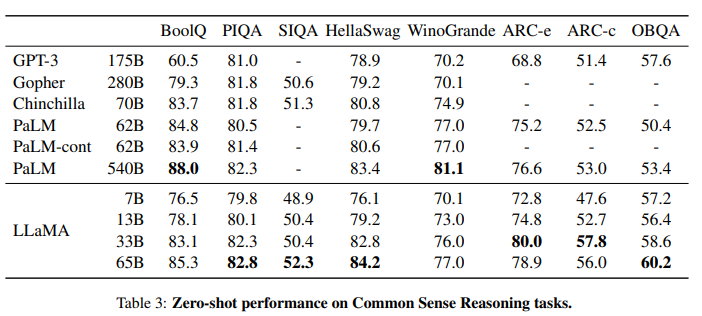
상식추론 과정에 대해서, LLaMA 13B 정도 모델이면 GPT-3보다 거의 대부분 앞서는 것을 확인할 수 있다. 65B 크기의 모델은 PaLM 보다도 뛰어나 거의 모든 벤치마크에서 가장 뛰어난 성능을 보이는 것을 확인할 수 있다.
QA
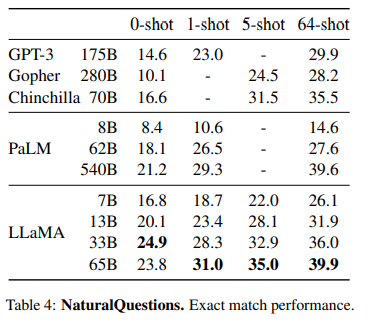 LLaMA를 free-from generation task(컴퓨터가 자유롭게 문장을 만들어내는 작업)와 multiple choice task(주어진 문맥을 바탕으로 제시된 답변 중에서 가장 적절한 답을 선택하는 작업)에 대해 평가했다.
LLaMA를 free-from generation task(컴퓨터가 자유롭게 문장을 만들어내는 작업)와 multiple choice task(주어진 문맥을 바탕으로 제시된 답변 중에서 가장 적절한 답을 선택하는 작업)에 대해 평가했다.
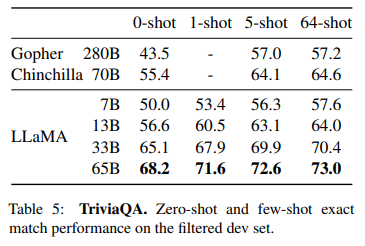
위 두가지 Question Answering task에 대해서 두 벤치마크에 대해 SOTA를 달성한 것을 알 수 있다. 또한, 13B 크기만 되도 다른 모델과 비슷한 성능을 가지는 것을 알 수 있다.
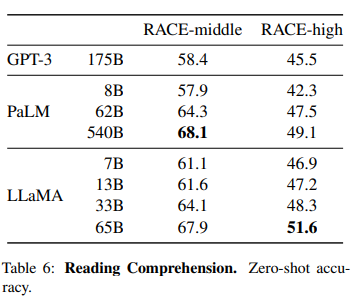
Reading Comprehension
Mathematical reasoning
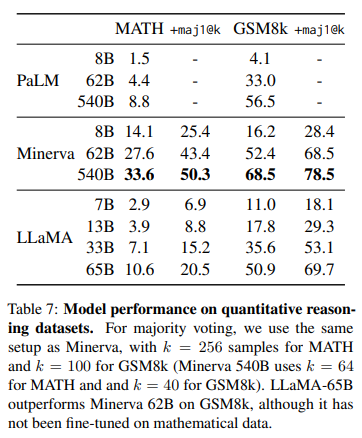
Math 데이터에 대해서는 Minerva보다 훨씬 낮은 성능을 보이는 것을 알 수 있다.
Code generation
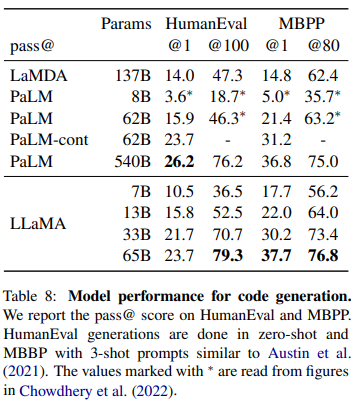
코드를 생성하는 task에도 LLaMA가 높은 성능을 보였다. 여기서 model은 설명과 주어진 test case에 대해 충족하는 코드를 작성해야 하는데, pass@k는 k개 prediction 중 k개 맞으면 pass임을 의미한다.
Massive Multitask Language Understanding
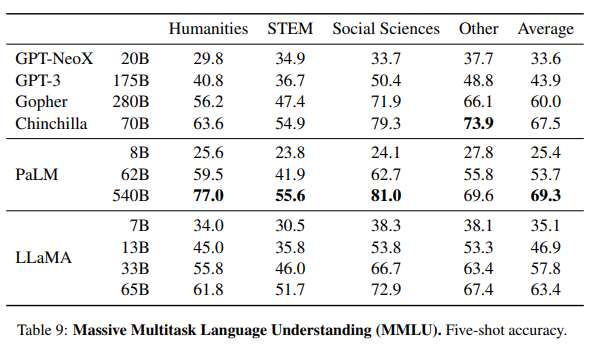
여러 분야를 포함하는 객관식 문항을 뽑는 task인데, 학습 데이터셋에 논문이나 책과 같은 데이터가 부족해 LLaMA가 뒤쳐진 것으로 예상할 수 있다.
Evolution of performance during training
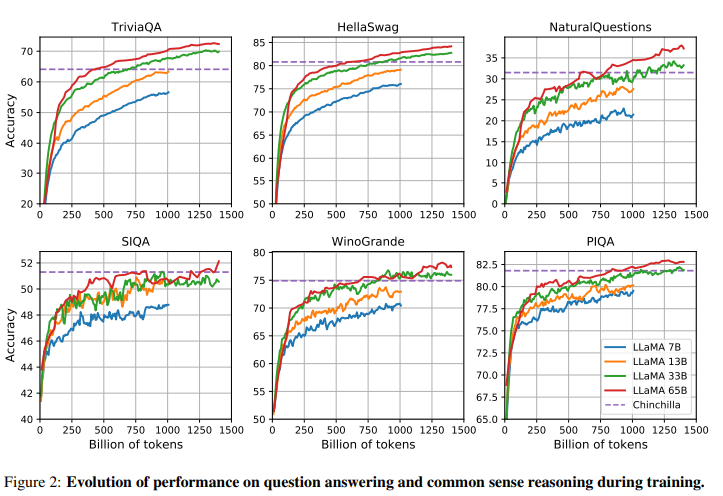
대부분읙 경우 상승곡선을 그린다.
Instruction Finetuning
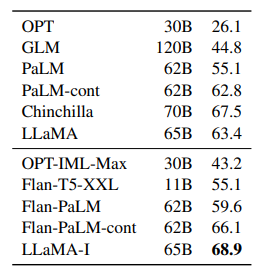
LLaMA model에 간단한 fine tuning을 진행했음에도 성능이 올랐다. 이는 본 논문의 주 focus가 아니라 간단하게 넘어갔지만, 그래도 instruction tuning이 되는 것을 알 수 있다.
Bias,Toxicity & Misinformation
LLaMA와 같은 대형 언어 모델은 훈련 데이터에 포함된 편향을 재생산하고 증폭시킬 수 있다. 또한, 많은 양의 웹 데이터를 사용해 훈련된 만큼, 유해하거나 공격적인 내용을 생성할 가능성도 있다. LLaMA-65B 모델을 다양한 벤치마크로 유해성을 평가했다.
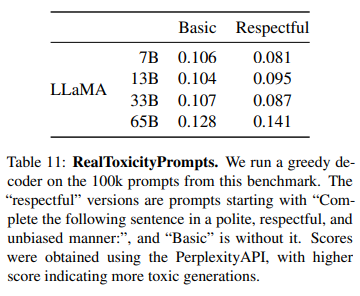
모델의 크기가 커질수록 toxicity도 증가하는 것을 확인할 수 있다. 특히, '정중한 질문'에 대한 응답에서 독성이 더 강하게 나타났다. 이전 연구들과 유사한 결과가 나왔지만, 연구마다 방법론이 다르기 때문에 직접적인 비교는 어렵다.
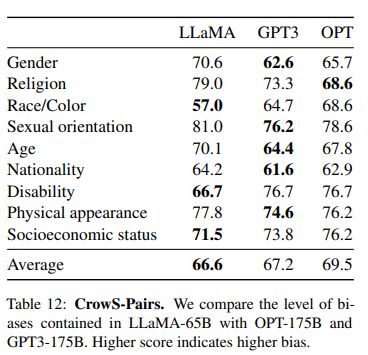
9가지 카테고리에 대한 고정관념을 평가한 결과다. LLaMA는 종교와 나이 관련 편향에서 특히 강한 편향을 나타냈다. 이러한 편향은 CommonCrawl 데이터셋에서 비롯된 것으로 보이며, 데이터 필터링에도 불구하고 나타났다.
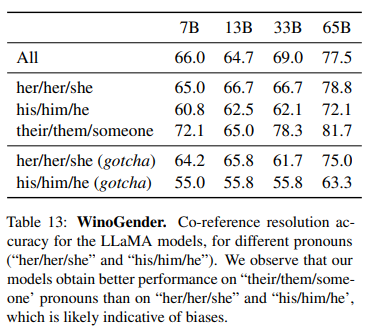
LLaMA의 성별 편향도 조사했다. 특히, 성별 대명사 관련 과제에서 성별 중립 대명사인 'their'에 대해선 잘 처리했지만, 'his', 'her' 같은 특정 성별 대명사에 대해선 편향된 결과를 보였다. 특히, 전형적인 성별 역할에 맞지 않는 직업과 연결될 때 더 많은 편향이 드러났다.
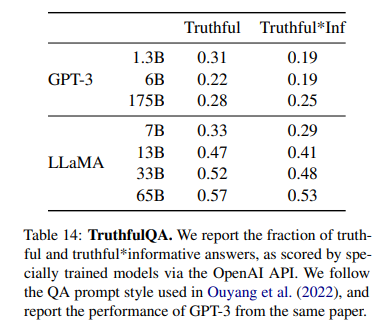
LLaMA-65B 모델은 GPT-3보다 높은 점수를 기록했지만, 여전히 정답을 생성하는 비율이 낮아, 모델이 허위 정보나 잘못된 답변을 생성할 가능성이 존재한다는 것을 보여준다.
Conclusion
모델 학습과정에서 탄소가 많이 배출되었지만, 학습이 완료되었기 때문에, 추론과정에서는 이런 수준의 GPU가 필요없다. 아직 Bias,Toxicity, Misinformation에 대해선 해결해야하는 과제로 남아있지만, LLaMA는 모델의 크기가 작고 open된 데이터로 학습했음에도 대부분의 벤치마크에서 고무적은 결과를 보였다.
Reference
https://arxiv.org/abs/2302.13971
https://www.notion.so/imlabswu/LLaMa-Open-and-Efficient-Foundation-Language-Models-12a8c9178afa4ca7aa765a3a2f83e034?pvs=4
