
문자열 단위 language modeling
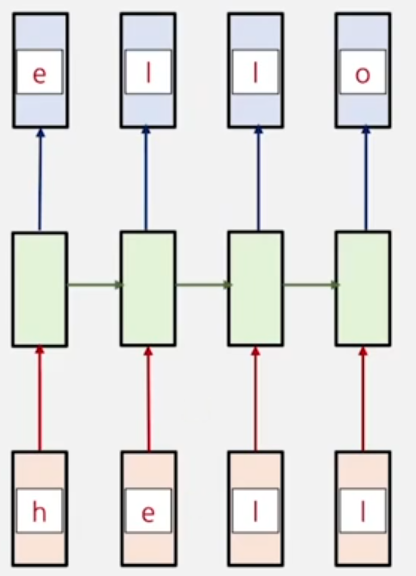
위의 경우 "hello" 라는 학습 문자열을 문자 단위로 tokenization을 수행하고, 이를 집합으로 가지는 vocabulary를 [h,e,l,o]로 구축한다.
각 글자의 다음 글자를 예측하는 것으로 모델을 학습시킨다.
model의 input layer
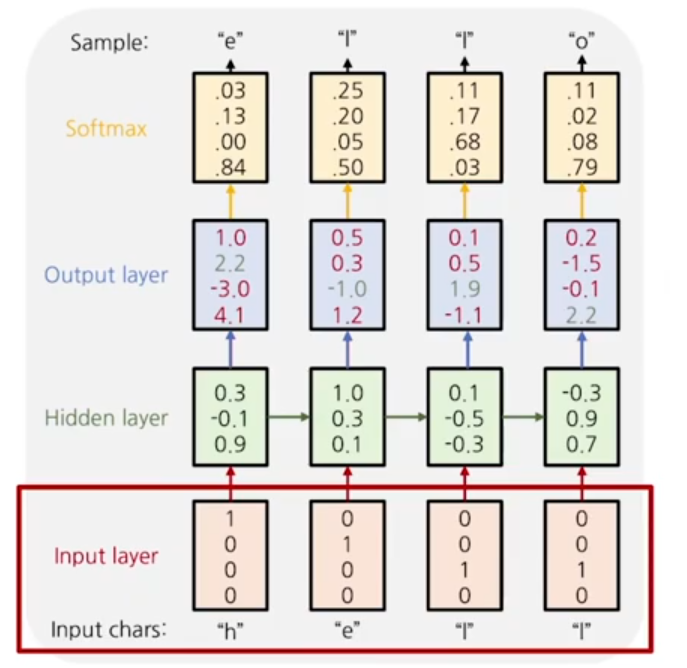
RNN 모델의 입력은 vocabulary의 size와 같은 크기의 차원을 가지는 one hot vector로 이루어져있다.
model의 hidden layer
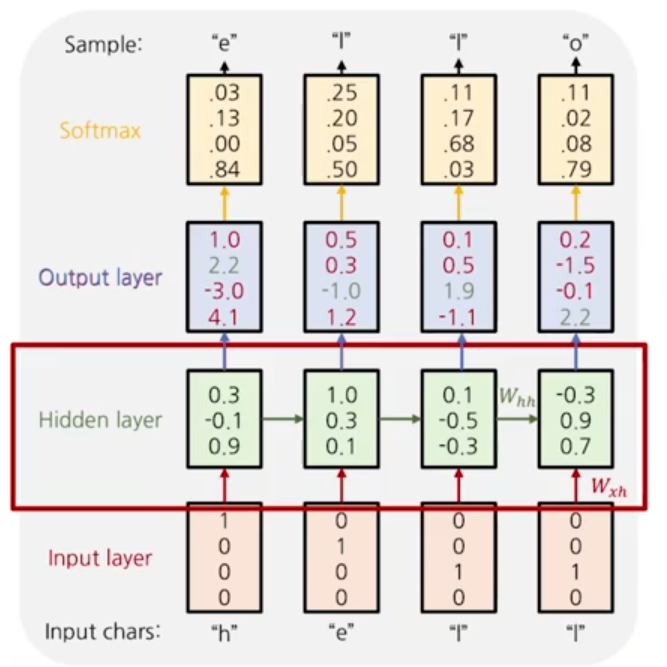
다음 layer에서는 hidden state value를 계산한다. input layer에서 이뤄지는 선형변환과, hidden state간에 이뤄지는 선형변환이 존재한다.
최종적인 값은 tanh를 거치며 -1~1의 값을 가지게 된다.
model의 output layer
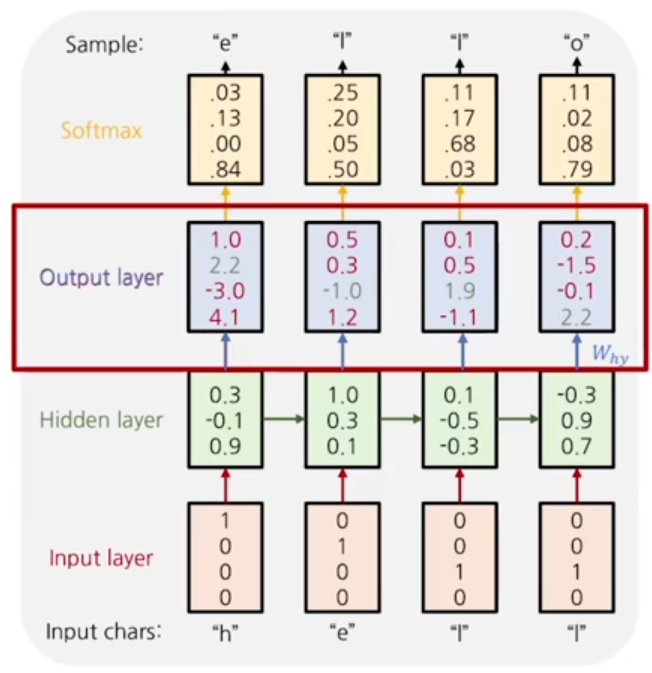
각 time step에서 얻어진 hidden state vector를 입력으로 vocabulary의 size 차원에 해당하는 결과 값을 가지게 되고, 이를 softmax함수를 거쳐 다중 클래스 분류를 진행하게 된다.
cross entropy loss를 계산하여 backpropagation을 진행하게된다.
model inference
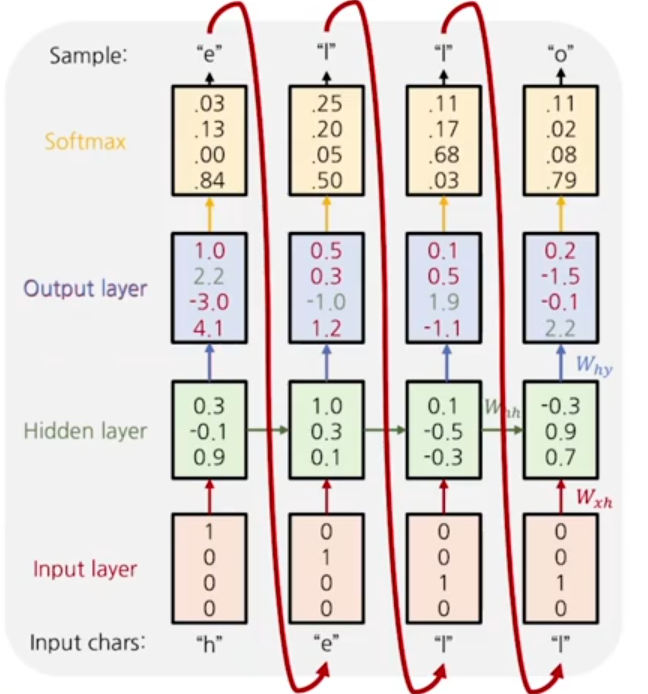
model의 추론과정에서는 첫번째 input이 주어지게 되면 그 이후의 input layer값들은, softmax를 거친 최종 확률값이 입력되게된다.
학습 과정중 추론이 이뤄지게 되면, 위의 경우, 사실 첫번째 time step 기준 o 값이 제일 크기 때문에, 이 값이 다음 step의 입력으로 들어가게 된다.
이런식으로 이전 time step에서의 입력값이 다음 time step에 들어가게 되는 것을 auto regressive model이라고 한다.
BPTT(Back Propagation Through Time)
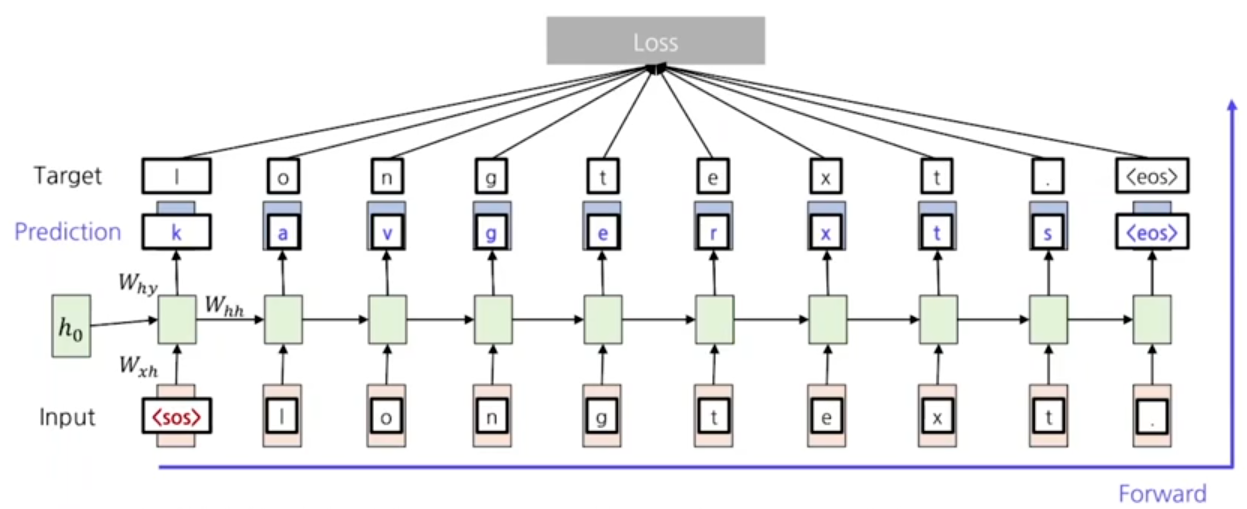
간단한 원리에 대해 알았으니, 깊이있게 살펴보자. 먼저 실제로 RNN을 활용한 언어 모델링에서 첫 input은 SOS라는 토큰이 사용된다.
sos는 start of sentence라는 의미로 문장의 시작을 알려주는 특수한 토큰으로 vocabulary에도 존재하게 된다. 그리고, 문장의 끝은 eos token을 출력하도록 학습을 진행한다.
eos는 end of sentence라는 의미로, 모델이 직접 출력으로 문장의 끝을 의미하는 token을 예측해 추론이 종료되게끔 학습한다.
모델의 학습과정에서는 input data로 일단, target에서 eos token까지의 ground truth 값을 순차적으로 입력하게 된다.
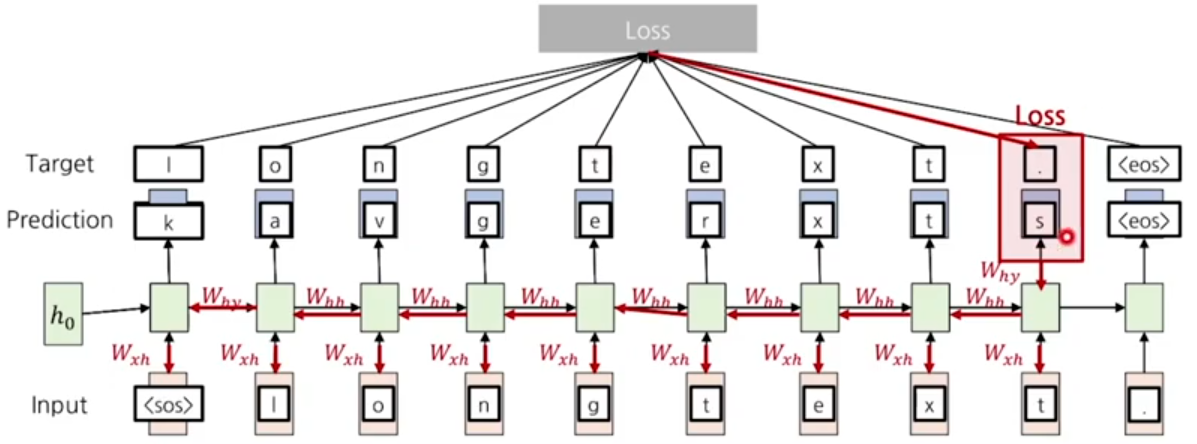
ground truth와 prediction 간의 차이가 발생할 때 loss가 발생하게 되고, 추론과정에서의 화살표를 역순으로 진행하여 back propagation을 진행한다.
해당 time step에서의 gradient만 계산하는 것이 아니라, 이전 hidden state에서 넘어온 값들에 대해서도 gradient를 축적하여 계산하게 된다. 이를 BPTT(Back Propagation Through Time)이라고 한다.
Truncated BPTT

sequence의 길이가 길어지고 데이터가 커질 수록, backpropagation을 위해 계산할 gradient의 layer수가 늘어나기 때문에, 누적되는 gradiennt를 GPU에 저장하기 위해 메모리 요구량이 증가하게 된다.
따라서, chunk 단위로 전체 sequence data를 나눠 forward와 backward를 진행한다. back propagation을 chunk 단위 안에서만 진행하는 것으로 계산량을 줄이게 된다.
그리고 다음 chunk로 넘어갈때는 hidden state value만 유지하게 되고, 이를 최초의 로 사용한다. GPU에 저장된 계산했던 gradient value를 모두 비우게 된다.
