
transformer는 2017년 구글의 논문 "Attention is all you need"에서 나온 Attention만으로 구현한 모델이다. 기존의 RNN구조를 제거한뒤에도 높은 성능을 보인 모델 아키텍처이다.

transformer구조를 배우기에 앞서, seq2seq 모델에 대해서 알아야한다.
seq2seq
seq2seq 모델은 인코더-디코더 구조로 구성되어있다. 각각의 역할은 아래와 같다.
인코더: 입력 시퀀스를 하나의 벡터 표현(context vector)으로 압축
디코더: 인코드에서의 벡터 표현을 통해서 출력 시퀀스 만듬.
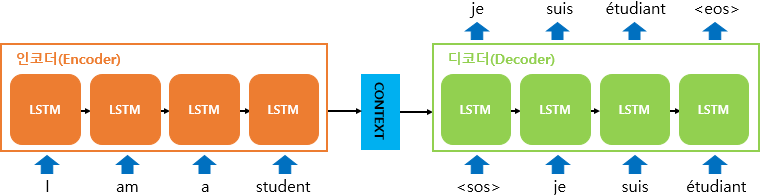
출처: https://wikidocs.net/24996
이 구조는 인코더가 입력 시퀀스를 하나의 context vector로 압축하는 과정에서 고정된 크기 의 vector로 압축하기 때문에, 입력 시퀀스의 정보가 일부 손실된다는 단점이 있다. 또한, 각 인코더와 디코더의 셀로 사용되는 RNN에서의 경사 소실/폭발 문제가 발생할 수 있기 때문에, 이를 보정하기 위해 어텐션이 도입되었다.
seq2seq의 문제점
- 다양한 문장의 길이에 걸맞지 않게 정해진 길이의 context vector로 인해 손실되는 정보 발생
- RNN에서의 경사 소실/폭발 문제 발생
seq2seq with attention
고정된 길이의 context vector가 입력문장을 모두 표현하는 데 한계가 있다는 점을 해결하기 위해서 RNN에 attention 개념을 도입한 개념이 사용되었다.
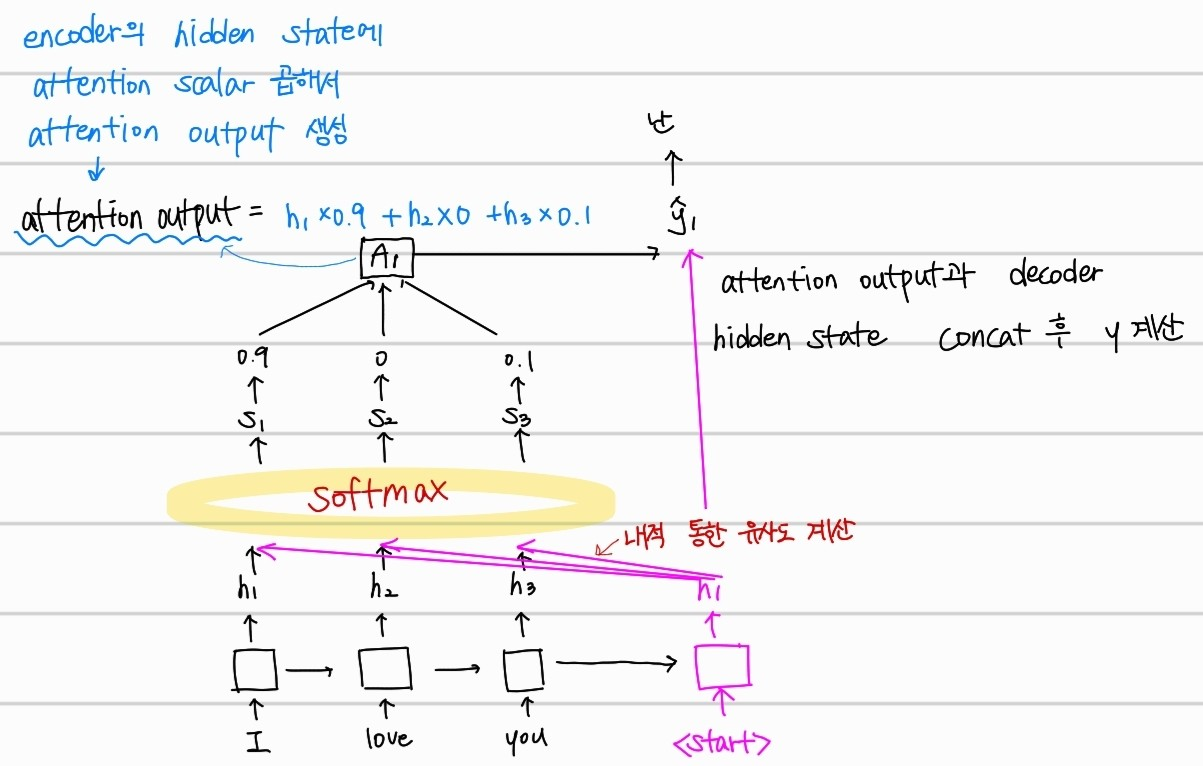
📌attention : 인코더의 time step 별 hidden state 값을 모두 반영하고, 어떤 값을 제일 중점으로 볼지 디코더의 현재 time step에 해당하는 hidden state 값과의 유사도를 계산한다.
위의 사진을 예시로 보면, "I"라는 단어를 "난"으로 번역할때, <start> 토큰의 hidden state 값과 인코더에서의 각 hidden state 값을 내적하여 softmax 함수로 얼마나 비중을 둘지 스칼라로 계산하는 것을 알 수 있다.
해당 스칼라를 계수로 하여 구한 attention output 값과 디코더의 hidden state 값을 concat한 후 y를 계산하는 방법으로 진행된다.
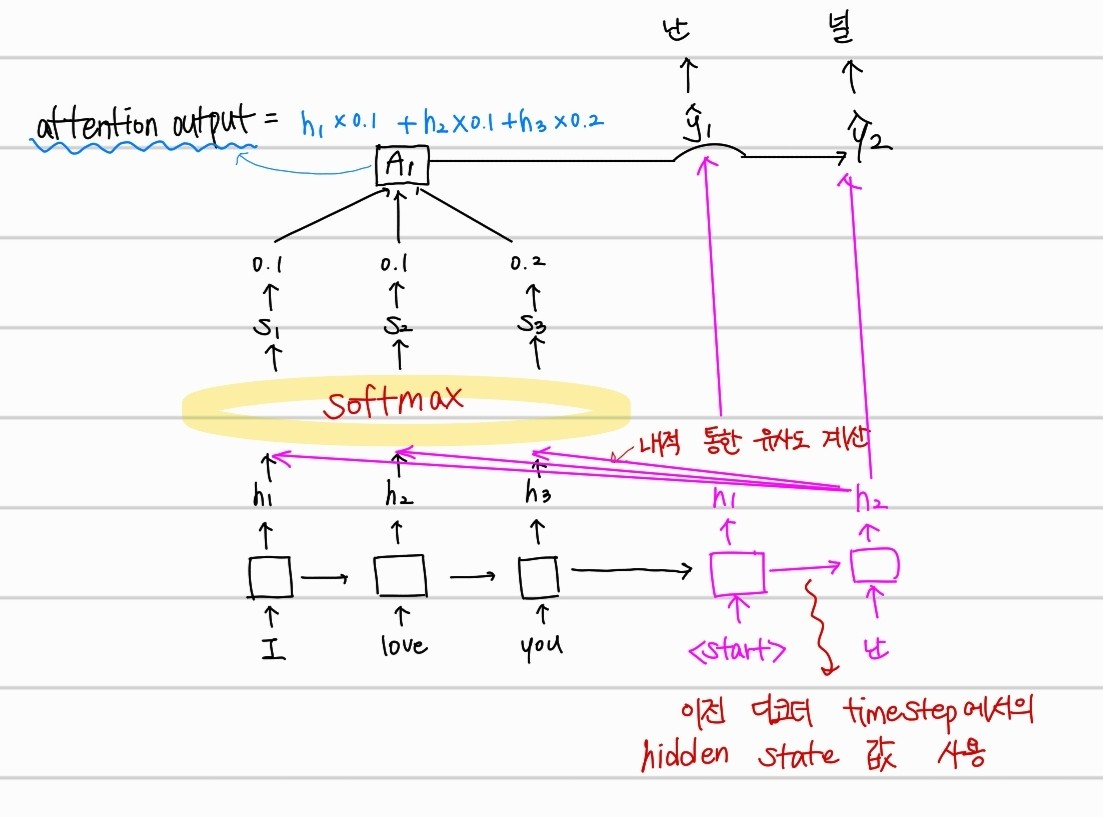
다음 단어에 대해서 예측할때도, 이전 time step의 디코더 hidden state 값을 입력으로 받아 디코더의 hidden state 값을 계산하고, 인코더에서의 hidden state 값과의 유사도를 계산하여 널 이라는 단어를 예측하는 것을 알 수 있다.
- teacher forcing
위의 attention 방법과 함께 many to many인 seq2seq 모델에서 디코더의 input에 해당하는 값들을 이전 time step에서의 디코더 output이 아닌 ground truth 값을 입력하는 것이다. 이는 학습과정에서만 이뤄진다.
Transformer
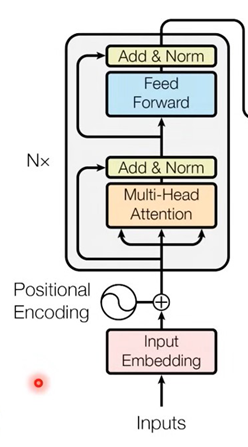
이전 seq2seq의 구조는 각각 하나의 RNN이 t개의 시점을 가지는 구조였지만, Transformer구조는 인코더와 디코더가 N개의 단위로 주어진다.
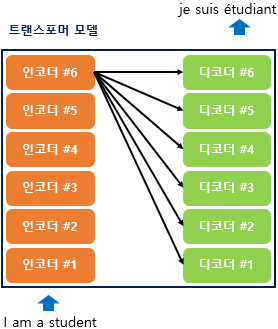
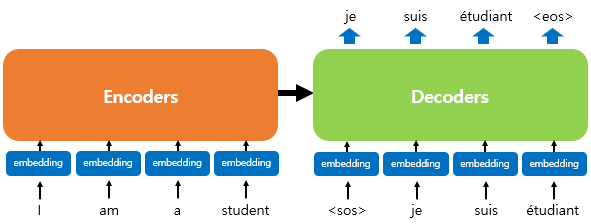
위의 그림은 인코더로부터 정보를 전달받아 디코더가 출력 결과를 만들어내는 트랜스포머 구조이다. 를 입력으로 받아 종료 심볼 가 나올 때까지 디코더는 연산을 진행한다. RNN없이 인코더 디코더 형태가 유지된다. 위의 그림은 단순하게 그린것으로 자세히 살펴볼 필요가 있다.
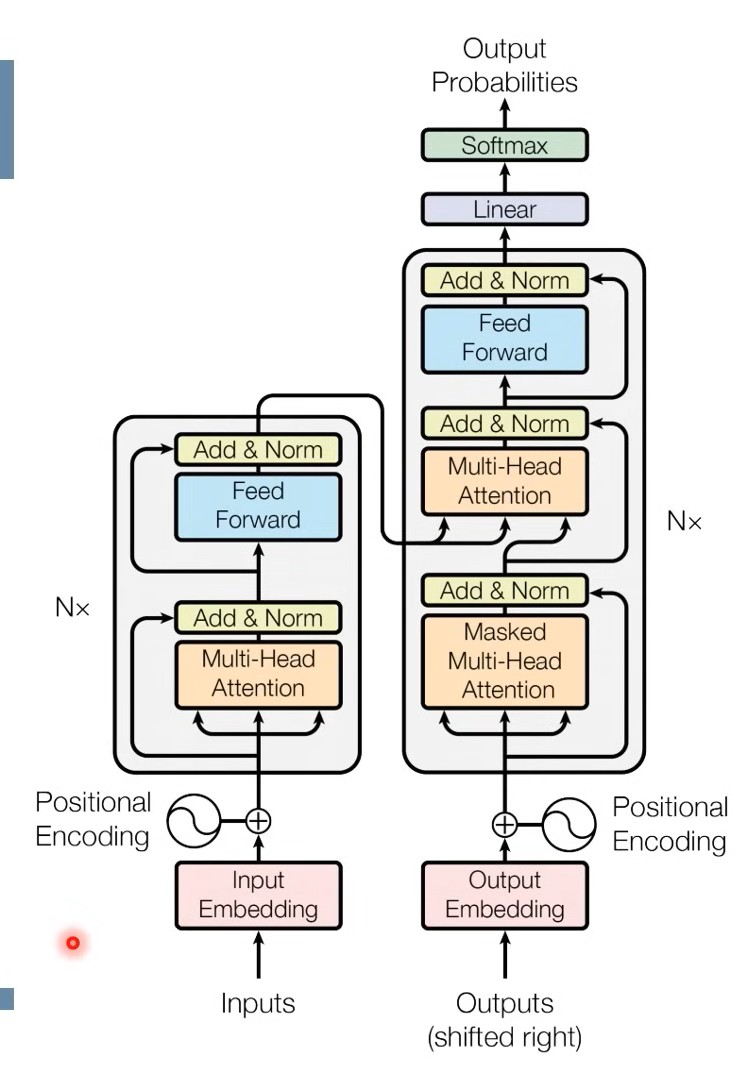
위의 그림에서 좌측에 해당하는 것이 encoder, 우측에 해당하는 것이 decoder이다.
먼저 encoder에 대해 자세히 살펴보자.
Encoder
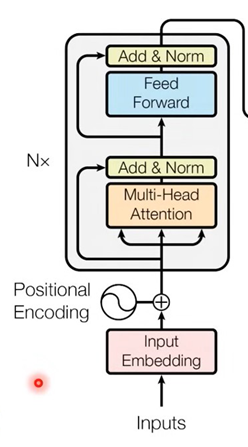
먼저 입력되는 inputs가 input embedding, positional encoding을 통해서 encoding된 sequence가 입력된다. 여기서 input embedding이 어떻게 이뤄지는지 알아보자
input embedding
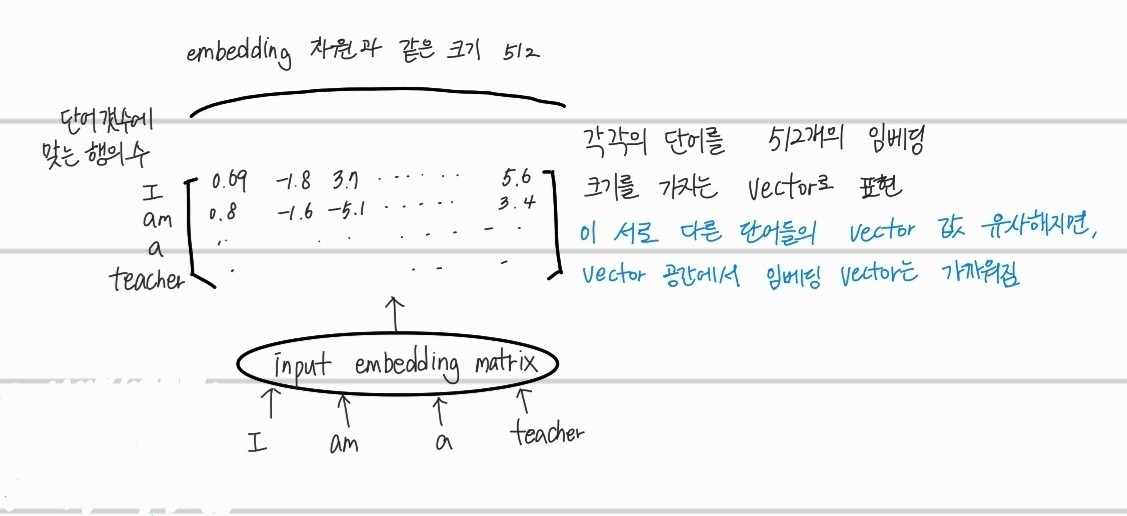
embedding은 쉽게 단어를 수치화하는 과정이다. 주로 특정 언어에 존재하는 단어의 갯수와 같기 때문에 입력되는 차원이 많다. 그리고, 단어는 one hot encoding 된 형태로 입력되게 된다.
- one hot encoding
각 단어에 대해서 인덱스화하여 표현하고 싶은 단어의 인덱스만 1로 부여한다.

position embedding
RNN이나, CNN을 사용하지않았기 때문에, 문장내 단어의 위치에 대한 정보가 없어서 position embedding이 필요하다. position embedding시에는 주의해야할 점이 세가지 있다.
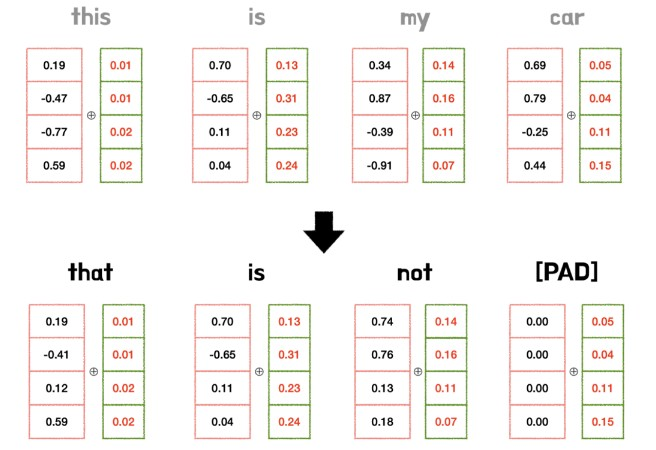
1) token이 어떤값인지와 무관하게 위치값은 모두 같다.
위의 사진을 보면, this와 that의 position embedding값은 모두 같은걸 알 수 있다.2) 너무 큰 값이면 안된다.
3) 위치 벡터 값은 sin,cos함수를 사용하여 설정한다. 먼저 sin,cos함수를 사용하게 된 이유가 있다.
- 위치에 비례한 정수값을 사용하면 문장의 마지막 token은 너무 값이 커져서 2)의 성질을 못지키게 됨
- 처음을 0 마지막을 1, 그 사이를 로하면 sequence가 어떤 값이 들어올지 모르기 때문에 예측이 힘듬
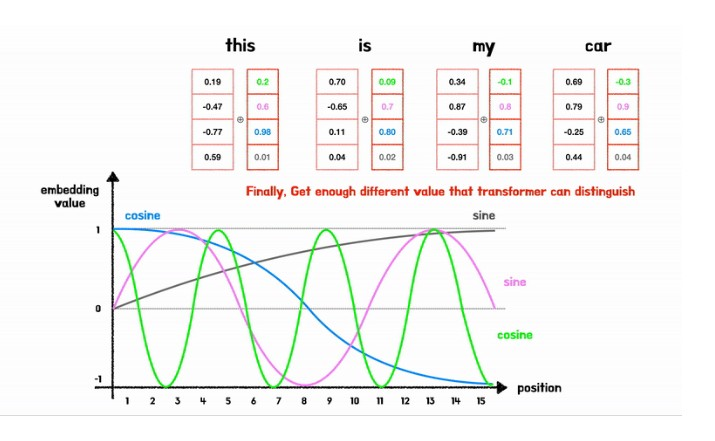
sin, cos함수 사용한 방법)
sin함수와 cos함수도 계속 같은 주기의 함수를 사용하면, 다른 위치의 값에 대해 같은 vector값을 가질 수 있기 때문에, 각 차원마다 서로 다르주기의 sin과 cos함수를 사용해서 모두 다른 위치벡터값이 나오게끔해서 positional embedding을 수행한다.
최종적으로 input embedding과 positional embedding의 결과를 elementwise합 한 결과가 Multi-Head Attention에 입력되는 것이다.
Attention
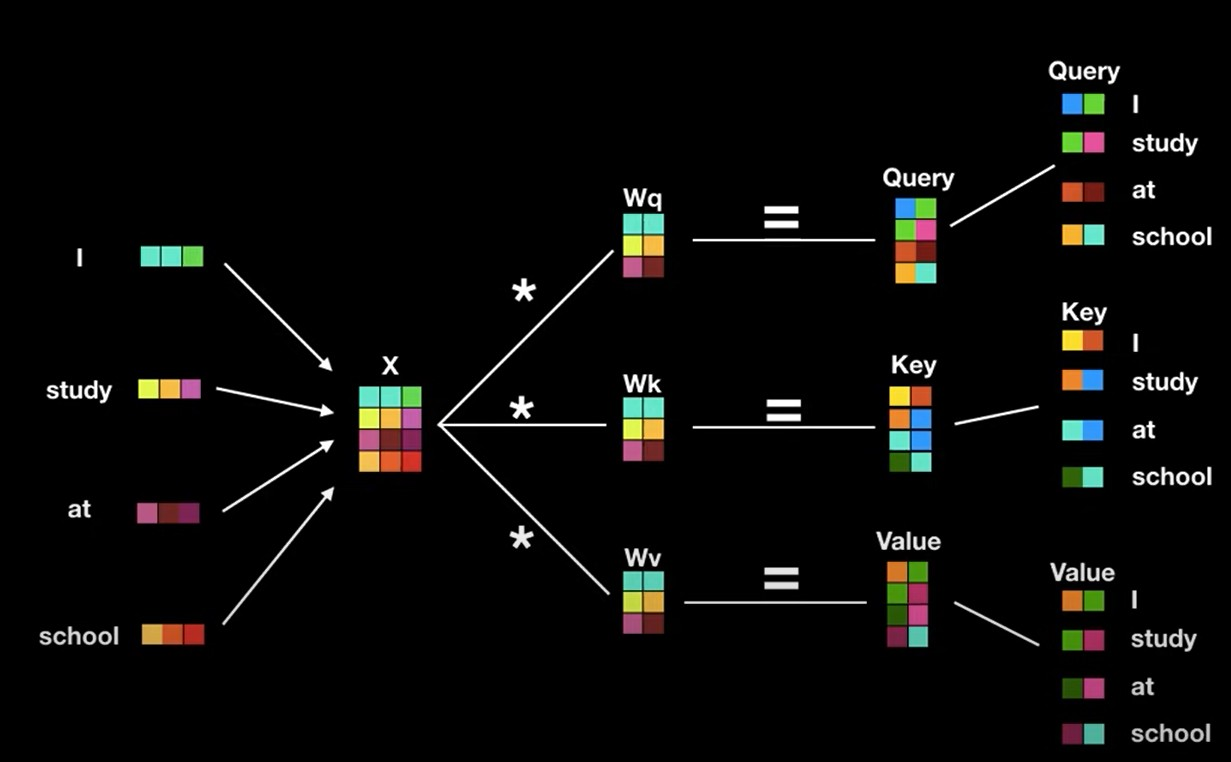
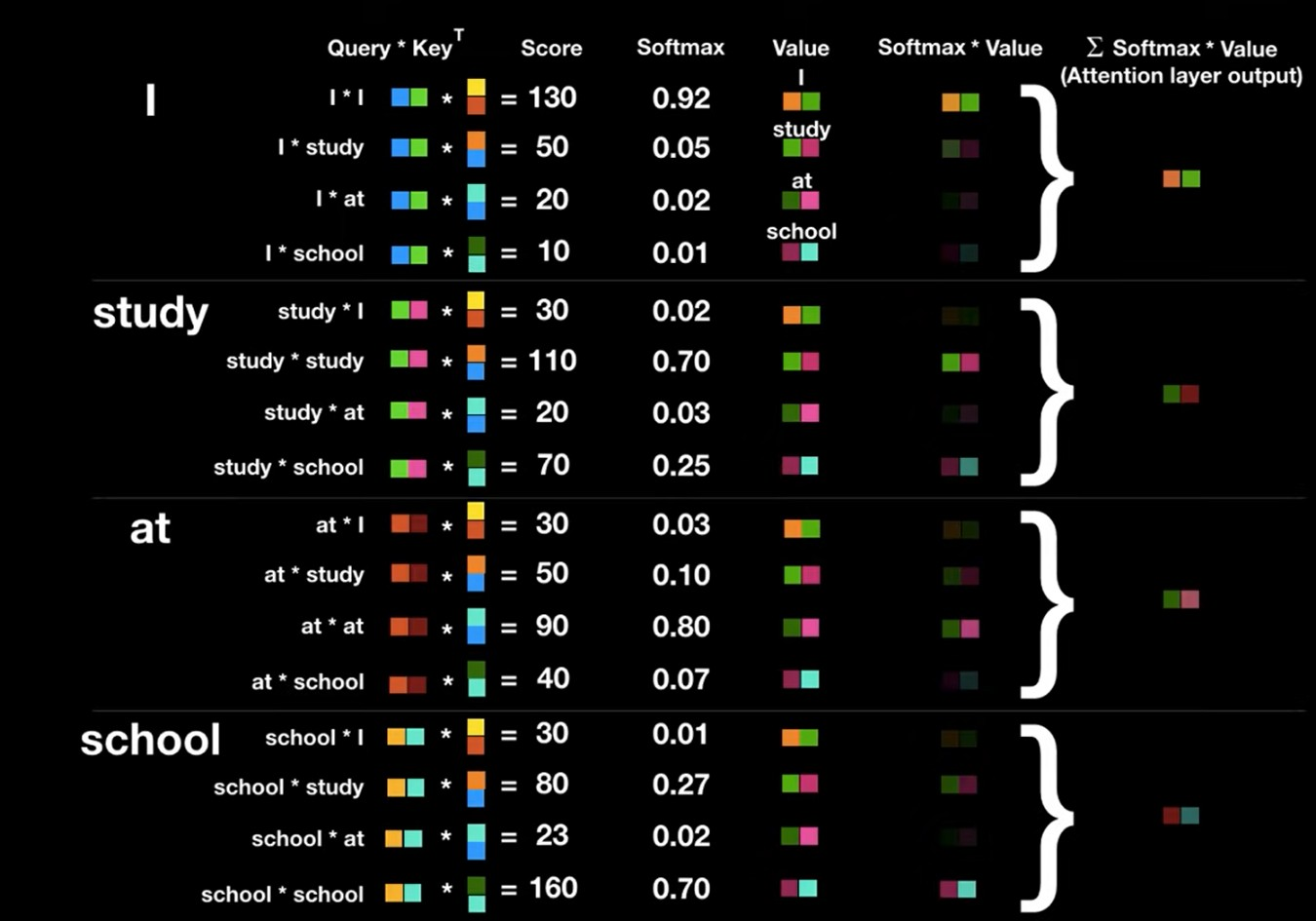
Attention은 Query값에 해당하는 단어가 Key에 해당하는 단어와 얼만큼 연관성을 가지는지를 의미한다. 예를 들어서, I am a teacher라는 문장이 self attention 수행시, 첫번째 단어 I에 대해서, 아래와 같이 그림을 그릴 수 있다.
Query: I
Key: I, am, a, teacher위의 그림을 통해 알 수 있듯이, Query값과 Key값의 내적을 통해서 scalar값이 나오는것을 알 수 있다. 사진에는 나와있지않지만, 내적 output값들을 softmax 취하며 각 관계중에서 어떤 관계가 가장 높은 점수를 가지는지 나타낸다. 마지막으로 value vector를 softmax output인 scalar값과 곱해 단어의 value 뿐 아니라 attention 값도 포함한 vector를 얻게 된다.
수식으로 표현하면,
이다.
: Query에 대한 key의 engergy값
: key dimension, gradient vanishing을 방지하기 위해 루트를 사용한 개의 Attention layer
여러 개의 Attention layer
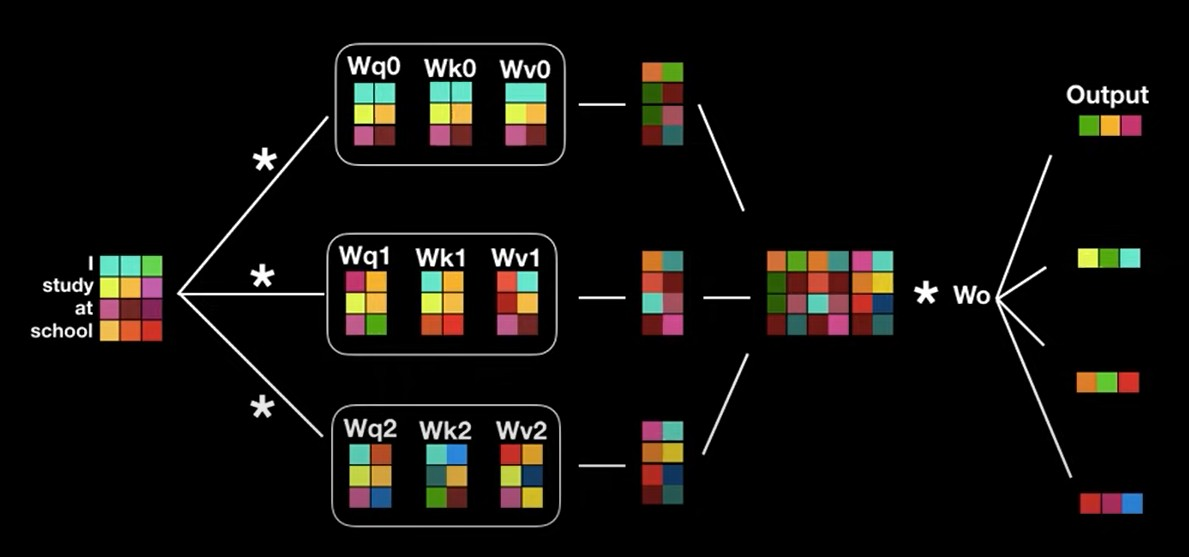
서로다른 n개의 Query,key,value값을 구한뒤, 이를 concat해서 Multihead attention을 수행한다. 수식으로 보면 너무 복잡해서 그림을 통해서 이해하는게 도움이 될것이다. 위의 attention 계산과정을 진행하면 처음 input으로 들어갈때와 shape이 변하지않은것을 확인할 수 있다. 기존의 attention이 적용된 RNN과 다르게 행렬 병렬연산이 가능하기 때문에 더 빠른 속도로 학습이 가능한 장점이 존재한다.
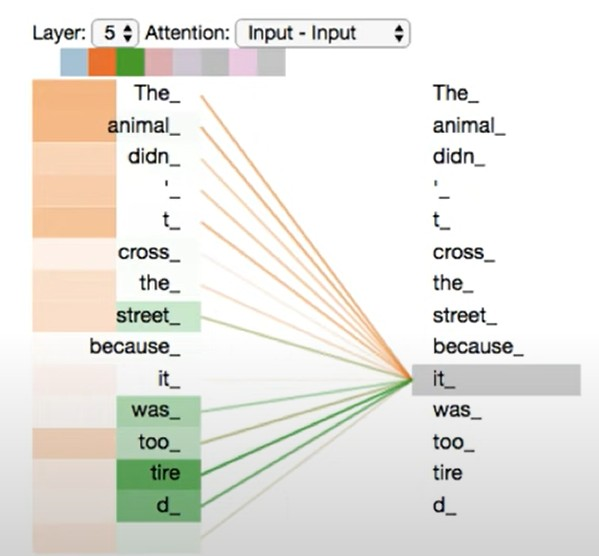
위의 사진과 같이 it 이라는 단어에 다양한 관점에서 바라본 attention layer를 적용해 animal과 tire이 큰 attention값을 가진다는것을 알 수 있다.
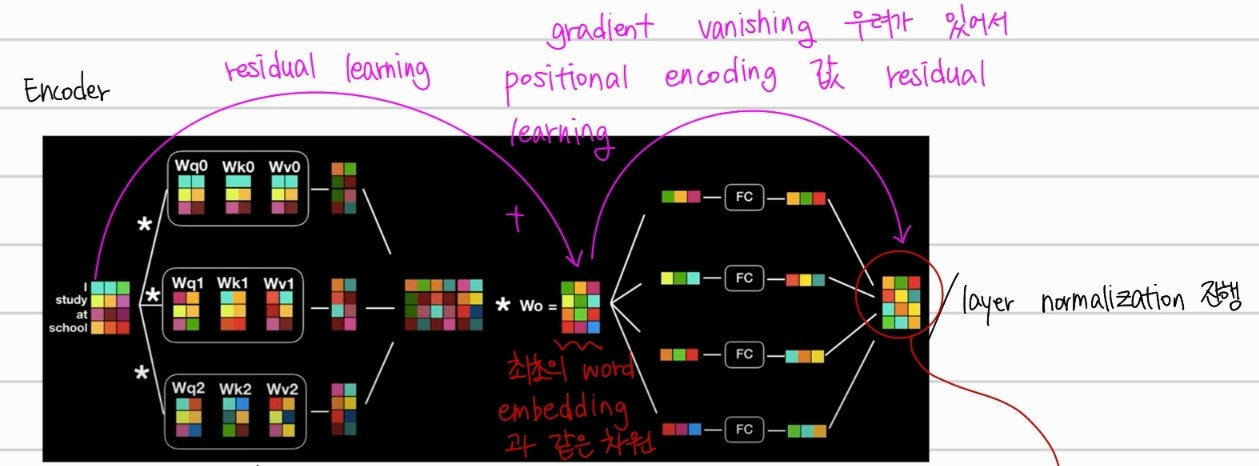
위는 한개의 인코더 구조를 설명한 것이다 위와 같은 구조의 인코더 계층이 여러개 붙어 있는 구조가 트랜스포머의 인코더 구조이다. 여기서 각 인코더 계층은 다른 weight를 가진다. 또한 input vector가 여러 인코더를 지나며 gradient vanishing 문제가 생길 수 있어 residual learning을 사용한다.
앞선 이 이미지와 같은 구조를 다르게 표현한 것 뿐이다.
Decoder
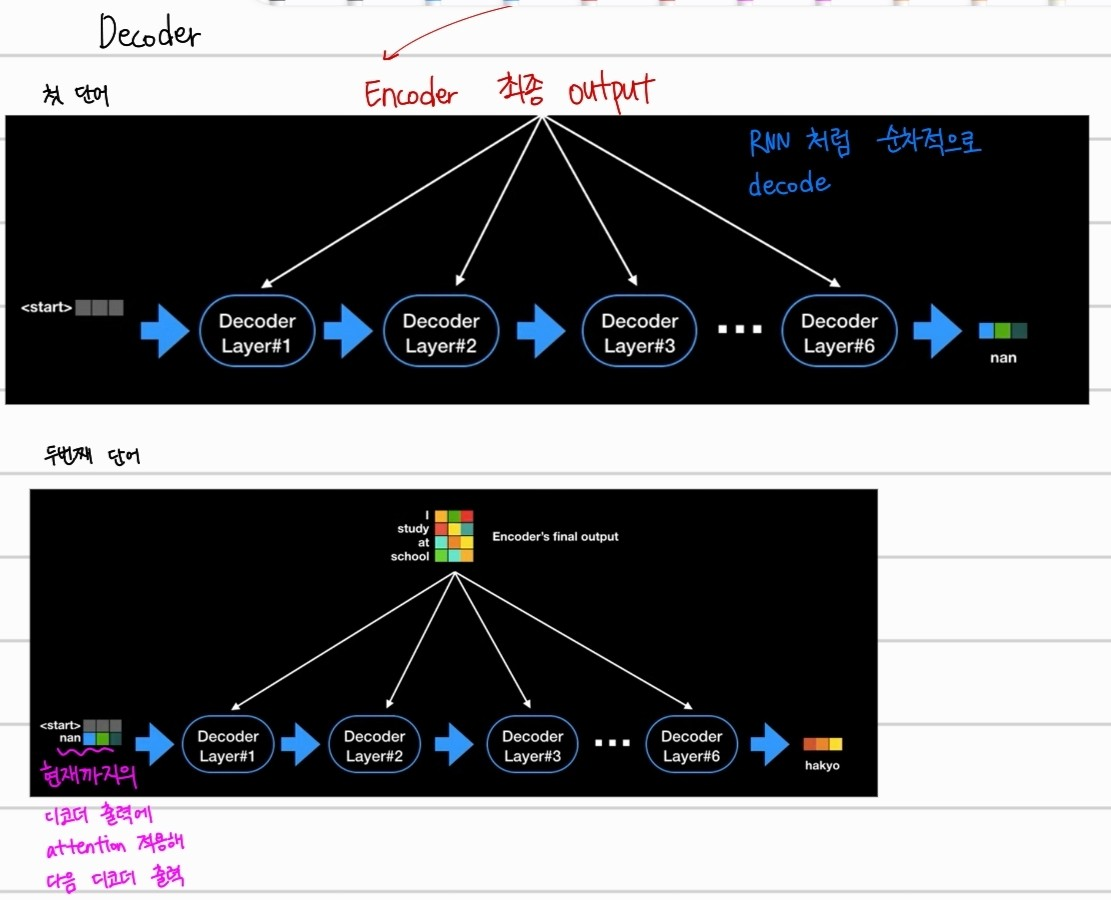
디코더는 RNN과 동일하게 한개의 단어씩 생성된다. 먼저 start를 입력으로 받고, "난"으로 번역한 뒤 그다음 단어를 예측할때는 현재까지의 디코더 출력에 attention을 적용해서 다음 디코더의 출력값을 예측한다.
Encoder → Decoder
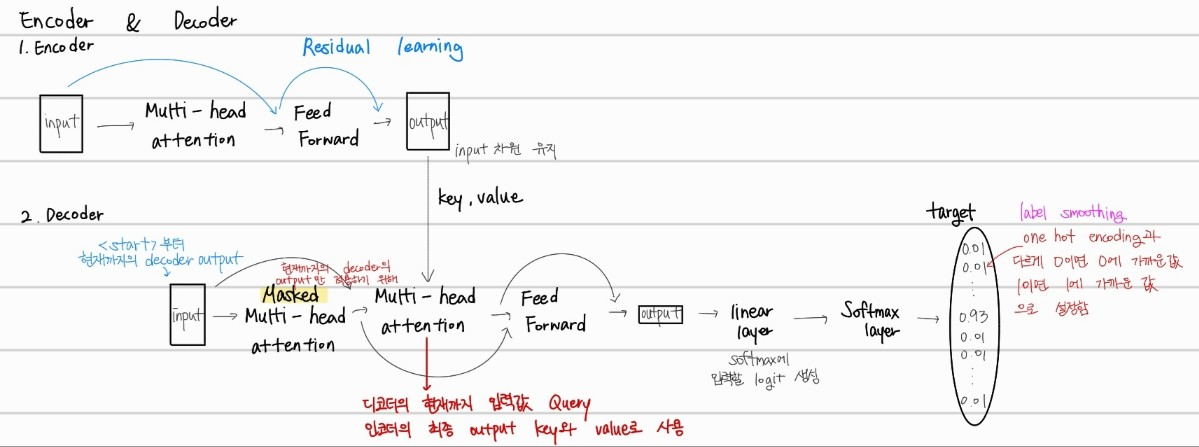
디코더에서는 Masked Multi-head-attention이 사용되는 것을 알 수 있다. 이는 현재까지 decoder의 output인 값들만 적용하기 위해서 masking처리를 한것이다. 또한, Multi-head-attention에서는 디코더의 현재까지의 입력값을 Query로 하고 인코더의 최종 output key와 value를 사용해서 디코더의 output을 예측한다. 또한, one hot encoding을 label smoothing을 통해서 0은 0에 가까운 어떠한 수 1이면 1에 가까운 어떠한 수로 softmax 결과값이 나오게 한다. 그 이유는, 예측확률이 정확도에 더 잘 정렬할 수 있게 하기 위해서 이다.
transformer의 등장배경
https://www.notion.so/Transformer-6ef00a5028544a6aa610a20ec8287478
Reference
https://wikidocs.net/31379
https://wikidocs.net/24996
Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
