
영상이나 텍스트처럼 연속적인 특성을 가진 입력값들이 존재한다. 이는, input 과 가 서로 독립적이지않고, 어느정도의 연관성을 가지고 있다. 이러한, 연속성을 띄는 data를 modeling한 것이 바로 Temporal Modeling으로, 일반적인 neural network와 다르게 순차적인 데이터를 처리하는 네트워크 구조이다.
RNN
RNN (Recurrent Neural Network)은 이름에서 알 수 있듯이 반복되는 인공신경망이다. hidden layer를 반복해서 사용하는 것이다. 먼저 간단하게 반복적인 형태의 그림이 아닌 한 줄로 편 그림에 대해서 알아보자
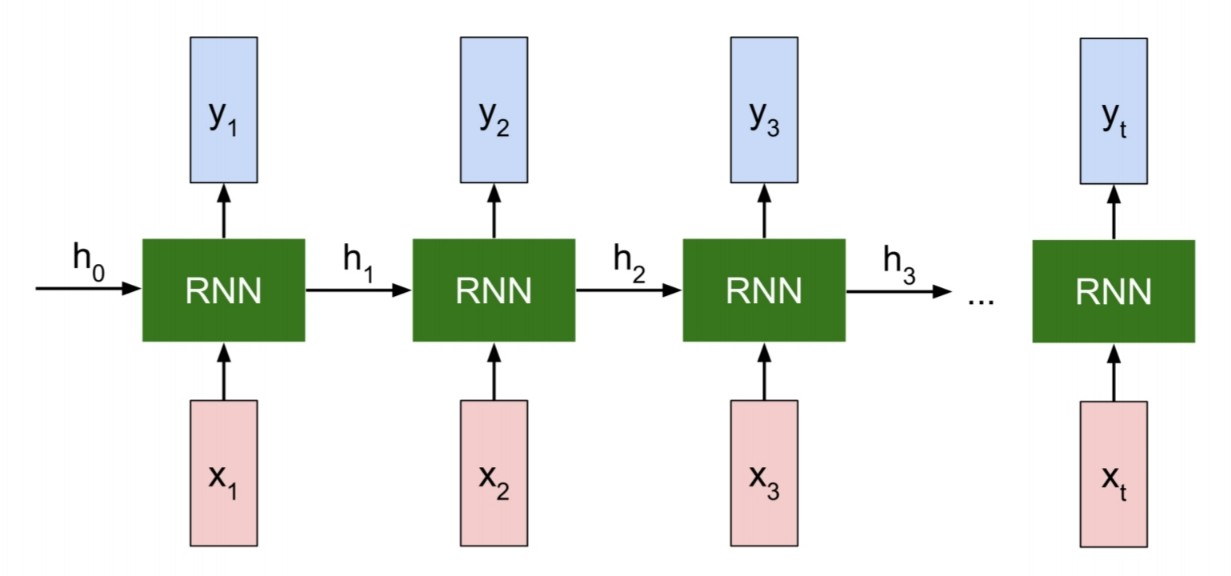
위의 그림에서 RNN cell들은 hidden state로 봐도 된다. 이전 hidden state에서의 output이 다음 hidden state의 input으로 들어가는 것을 확인할 수 있다. 그리고 각각의 hidden state에서의 model output 도 출력되는 것을 확인할 수 있다. 이를 수식으로 나타내면 아래와 같다.
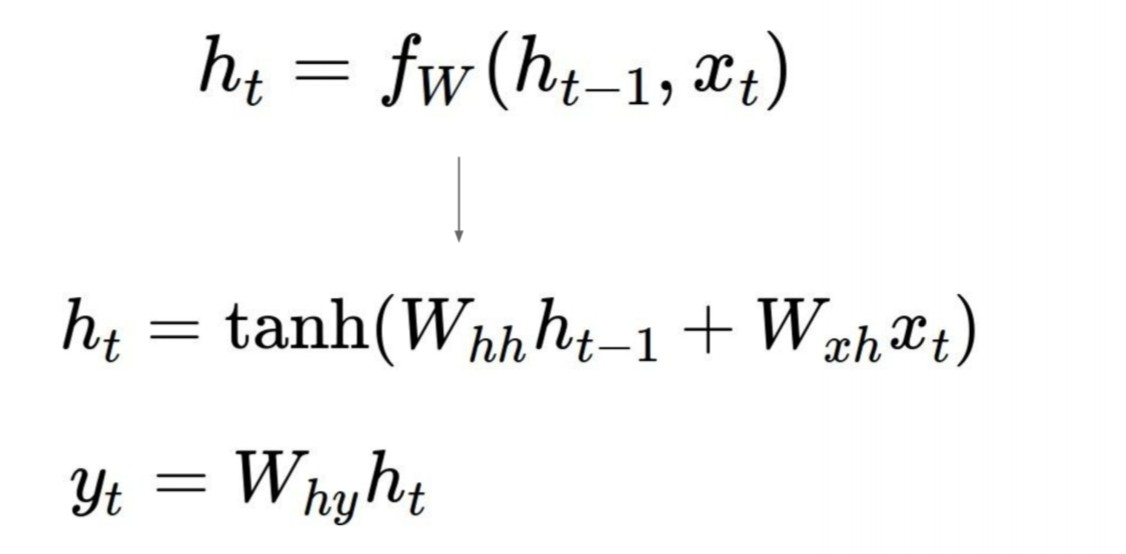
hidden state의 결과가 model의 output 로 출력되고, 이전 hidden state에서의 값 가 다음 hidden state로 입력되는 것을 알 수 있다. 이 과정에서 model자체에 들어가는 input 에는 가중치가 곱해지고, 이전 hidden state에서 입력받는 값 에는 가 가중치로서 곱해지는 것을 알 수 있다.
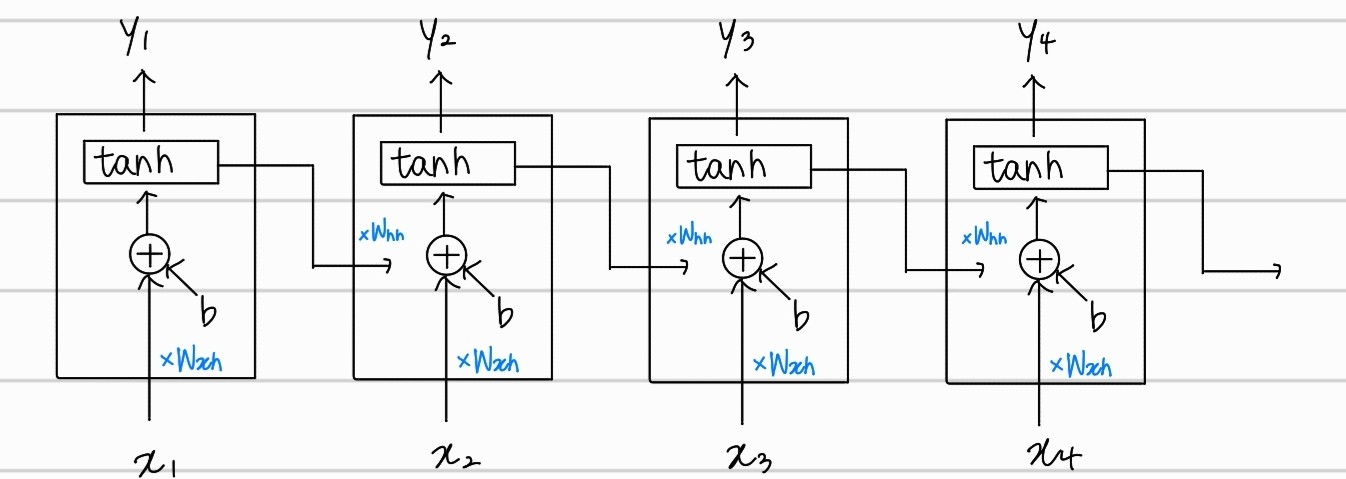
각 step마다 입력되는 값들에 를 곱하고 bias 값을 더한 다음, 이전 hidden state에서의 값에 를 곱해 더해주는 것으로, 들의 연속적인 값들을 모두 고려해서, 이전 값들에 대한 고려도 하며, 각각의 hidden state에서 output값을 가지는 것을 알 수 있다.
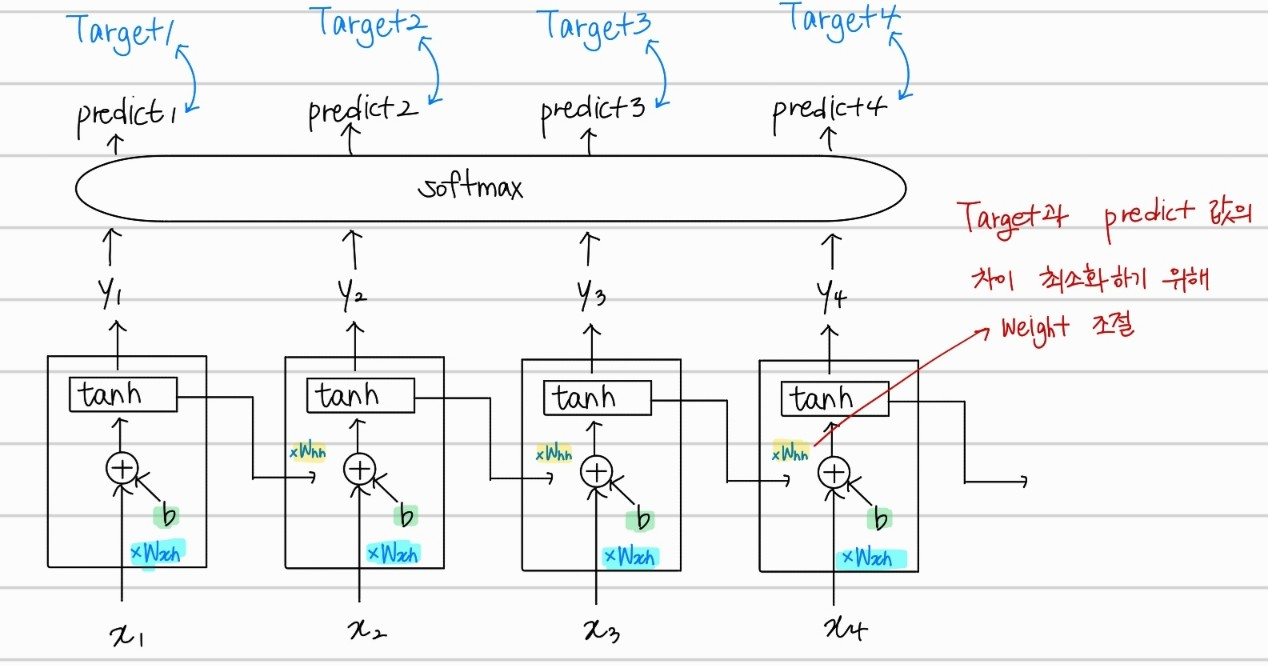
RNN은 supervised learning으로 특정 label로 옳게 predict하는지 오차를 계산한다. 또한, 이후 back propagation을 통해서 weight를 수정하는데, 모든 hidden state에서의 , , 값이 동일한 값이다. 따라서, Back Propagation Through Time(BPTT)이라고 한다. 각 hidden state에서의 output 를 활용한 것 외에도, 마지막 hidden state값을 softmax 취해 text에서의 감정분석과 같은 task를 수행할 수 있다.
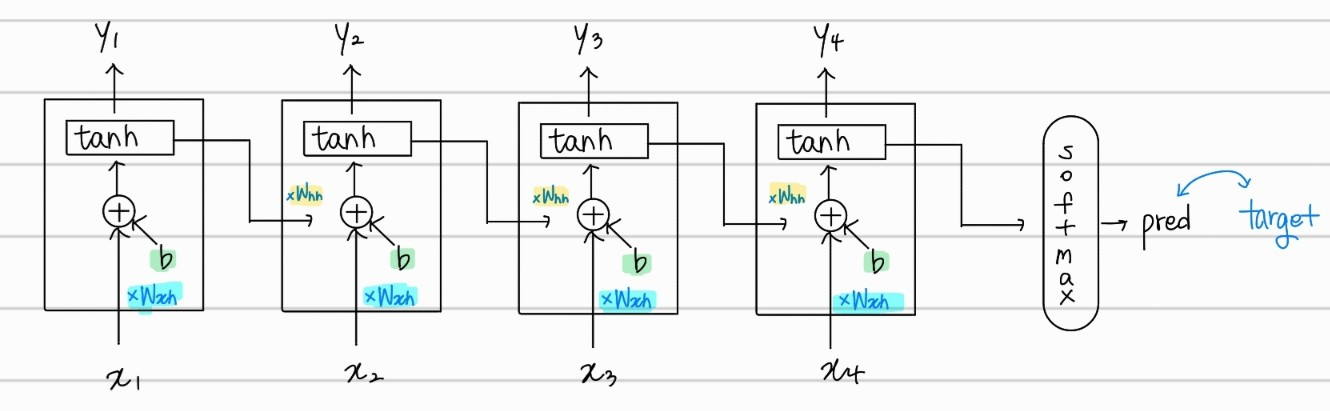
위와 같이 마지막 hidden state에서의 결과를 softmax 취해 predict한 값과 target의 차이를 활용해 같은 방법으로 back propagtion through time이 가능하다.
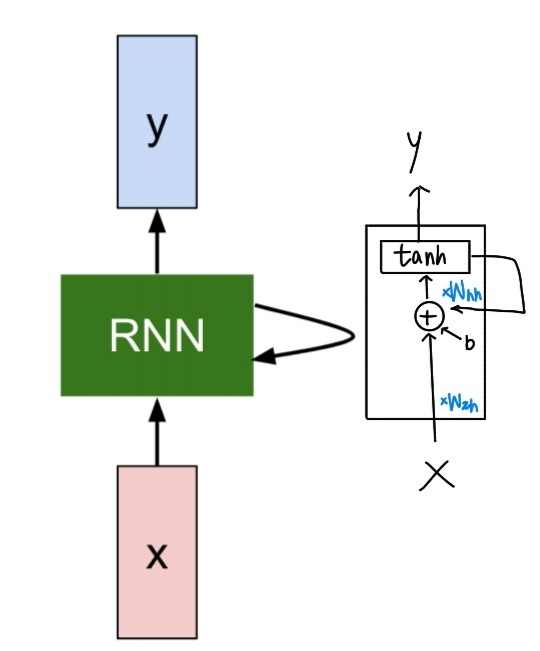
위의 과정들을 하나의 간단한 cell을 recurrent하는 모습으로 그릴 수 있다.
LSTM
RNN의 문제점 (gradient vanishing,exploding)

위는 hidden state 3개를 거쳐 output을 추출하는 과정이다. 자세히 살펴보면, back propagation 에서 hidden state의 갯수만큼 가 곱해지는 것을 알 수 있다. 이는 gradient 계산에 있어서 위험할 수 있다.
RNN은 이전 hidden state의 output이 다음 hidden state의 input이 되는 반복적인 구조이다. 마지막 hidden state에서의 gradient와 첫 hidden state에서의 gradient 사이에 있는 hidden state에서 0~1사이의 값이 계속해서 나오면, 초기 입력값에 대한 gradient가 작아지게 된다. 이러한 gradient vanishing 문제가 생길 수 있다. 반대로 1보다 큰 값들이 계속 곱해진다면, gradient exploding 문제가 발생한다. 긴 입력값에 대해서 이런 문제점이 발생하여 Truncated BPTT나 gradinet clipping로 완화하려 했지만 성능이 부족했고, LSTM이 등장했다.
직관적으로 생각해보면, hidden state는 고정된 크기로 한 input의 정보를 저장하지않고 sequence data모두를 저장한다.
이때, 너무 긴 sequence data를 고정된 크기의 저장공간에 저장한다 생각하면, 제대로 모든 의미를 저장하기 힘들다는 것이다.
Memory cell
기존의 RNN구조에 새로운 memory cell line을 추가해 이를 해결했다. LSTM은 Long-Short Term Memory라는 뜻으로, 이전의 hidden state의 결과값에 대해서, 현재 hidden state의 결과값 및 출력값을 계산할때, 어느정도 적용을 할지, 다음 hidden state로 어느정도 넘겨줄지 등을 결정하는 memory cell을 추가해, 오래 기억해야하는 값과, 금방 잊어야하는 값을 학습하며, gradient 문제를 해소한 방법이다. 이는 Forget gate , Input gate , Output gate로 이뤄져 있다.
Forget gate
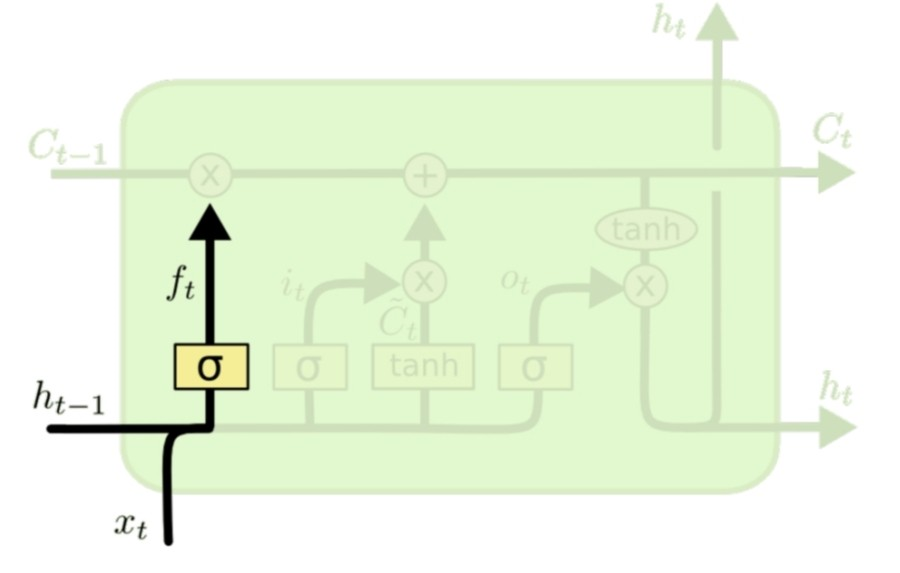
forget gate는 sigmoid 함수를 통해서 이전 hidden state의 값()과, 현재 input() 을 각각 weight를 곱하여 더해준 다음 sigmoid를 통과해, 0에서 1 사이 값으로 나오게 된다. 이는, 0은 forget을 의미하고, 1은 keep을 의미한다. 0의 값이 나오게 되면 에 해당 hidden state값을 반영하지 않도록 0을 곱하고, 1의 값이 나오게 되면 하는 즉, memory에 저장하고 삭제하는 역할을 수행한다.
Input gate
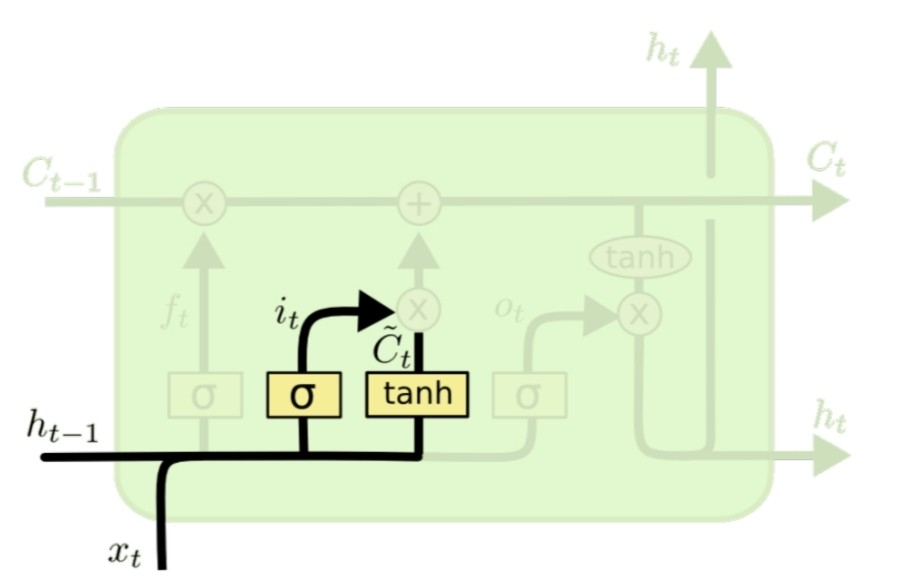
input gate는 어떤 값이 update될지를 정한다. 새로운 입력값에 대해서 마찬가지로 sigmoid와 tanh 값을 곱한 후, 이를 previous state를 나타내는 에 더하는 것으로 현재 state에 대한 값을 어느정도 반영하는지를 정하는 부분이다.
Output gate
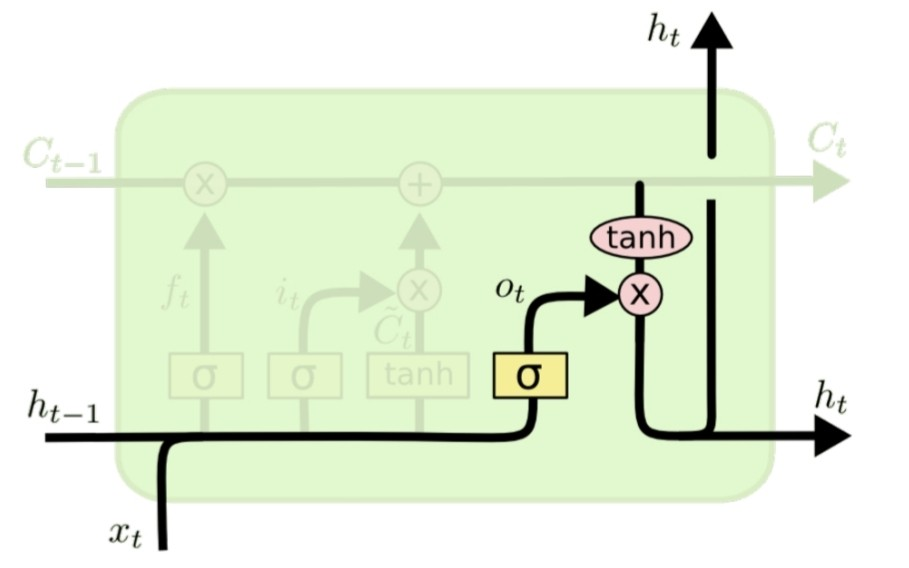
output gate는 마지막으로, 어떤 값이 output으로 출력되고 다음 hidden state로 넘어갈지를 정하는 부분이다. 마찬가지로 sigmoid를 거친 값을 현재 메모리에 들어있는 값과 곱하여 출력한다. RNN의 구조를 따르기 때문에 output으로 가 발생함과 동시에 다음 hidden state로 값이 넘어가는 것을 확인할 수 있다.
마무리
RNN은 결국 순차적인 데이터에 대해서 처리가 가능한 모델 네트워크의 구조이다. 하지만, 긴 길이를 가진 데이터에 대해서 gradient vanishing이나 exploding문제가 발생할 수 있고, 이를 해결하기 위해서 메모리 셀을 가지고있는 LSTM이 등장했다. 각각 이전 hidden state에 대해 forget input output gate를 가지고 있는 cell이였고, 해당 방법을 통해서 현재 입력값에 대해서 필요한 부분만 이전 hidden state에서 사용하며 gradient descent알고리즘을 적용할때 RNN에서 발생할 수 있는 문제를 어느정도 해소한 방법이다.
Reference
https://www.youtube.com/watch?v=PahF2hZM6cs
https://www.youtube.com/watch?v=bX6GLbpw-A4
