
python의 re module에서 지원하는 method에 대해 정리했다.
re module methods
- match
문자열의 처음부터 시작해서 작성한 pattern이 일치하는지 확인한다.
import re
print(re.match('a','abcde'))
print(re.match('c','abcde'))
c의 경우 문자열의 시작이 c가 아니기 때문에, None을 return한다.
- search
처음부터 일치하지 않아도 되는 match
import re
print(re.search('a','abcde'))
print(re.search('c','abcde'))
match와 다르게, 2번째에서 3번째 index까지 matching되었음을 return한다.
- findall
문자열 안에 패턴이 맞는 케이스를 모두 찾아서 list로 return한다.
import re
print(re.findall('a', 'a'))
print(re.findall('a', 'aba'))
print(re.findall('a', 'baa'))
print(re.findall('aaa', 'aaaaa'))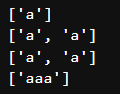
4번째 case의 경우, 한번 findall에 해당하여 찾아진 패턴을 겹쳐서 한번 더 찾는 것은 안되기 때문에 안겹치게끔 list에 한개의 case만 들어간다.
- finditer
findall()과 유사하지만 iterator 형식으로 return한다.
import re
re_iter = re.finditer('a', 'baa')
for s in re_iter:
print(s)
finditer 함수는 findall과 유사하지만 문자열내에서 찾은 pattern의 위치도 파악할 수 있다.
- split
문자열에서 패턴이 맞으면 이를 기점으로 쪼갠다. 그리고, 구분자는 빈 문자열로 리스트에 추가된다.
import re
print(re.split('a','abaabca'))
- sub
ctrl+h와 유사하게 pattern에 해당하는 text내 부분을 특정단어로 교체하는 것이다.
import re
print(re.sub('a','z','ab'))
sub(pattern,dst,text)로 이루어져있고, text내 pattern에 해당하는 부분을 dst로 바꾸는 함수이다.
- subn
sub와 동일하며, 매칭 횟수도 반환한다.
import re
print(re.subn('a','z','aaaab'))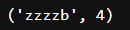
- compile
동일한 패턴이 여러번 사용되면, compile해두는 것이다. 위의 pattern이 인자로 쓰이던 모든 함수에 적용이 가능하다.
import re
c=re.compile('a')
print(c.sub('zxc','abc'))
print(c.search('vcxdfsa'))
Match object
findall()을 제외하고, search, finditer, match 모두 Match 객체로 반환된다. 해당 객체는 group(),start(),end() 와 같이 찾은 패턴의 위치 등을 반환하는 함수를 제공한다.
- group(),start(),end(),span()
- group() : pattern에 맞는 문자열 추출
- start() : 어디부터 pattern에 맞았는지
- end() : 어디까지 pattern에 맞았는지
- span() : 어디부터 어디까지가 pattern에 해당하는지
result = re.search('aa', 'baab')
print(result.group())
print(result.start())
print(result.end())
print(result.span())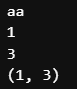
- groups(), group(integer)
pattern이 단순하지 않고 묶어 찾게 된다면 사용가능하다. group(integer)는 indexing과 유사하다고 생각하면 된다.
import re
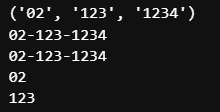
result = re.match('(\d{2})-(\d{3,4})-(\d{4})', '02-123-1234')
print(result.groups())
print(result.group())
print(result.group(0))
print(result.group(1))
print(result.group(2))
참고로, \d는 숫자를 의미한다. 또한, x{n} x가 n번 반복되어야한다를 의미한다. 즉, \d{2}는 숫자가 2번 반복되어야함을 의미한다.
- groupdict()
groupdict()를 사용하려면 pattern에 맞는 결과에 이름을 주어야한다.(?P<이름>) 형식으로 지정해야한다. ()도 포함해서 적어야한다.
import re
result = re.match('(?P<front>\d{2})-(?P<middle>\d{3,4})-(?P<rear>\d{4})', '02-123-1234')
print(result.groupdict())
print(result.groups())
print(result.group(1))
print(result.group('front'))
Pattern 형식
re에서는 아래와 같은 pattern을 지원한다.
- 대소문자 구분x
- \w \W \b \B 를 현재의 로케일에 영향을 받음
- 여러줄의 문자열에 대해 pattern을 탐색할 수 있음
- .을 줄바꾸기 문자도 포함해 매치하게 함
- 정규식 안의 공백 무시
- \w \W \b \B가 유니코드 문자 특성에 의존함
Reference
