
WordPiece
wordpiece 토큰화는 subword토큰화로 BERT와 DistilBERT,Electra에 사용된 알고리즘이다. 기존의 BPE알고리즘은, 빈도기반으로 subword를 병합하는 과정을 거쳤다. 너무 단순한 병합 원리로 최적의 결과를 보장할 수 없다.
wordpiece 토큰화는 language model을 사용하여 subword 병합시 병합결과에 대한 확률을 계산한다. 제일 높은 확률의 subword 쌍을 병합하는 방향으로 vocab을 구성하게 된다. 여기서 확률이란 (A,B) 쌍이 존재한다고 할때, A subword 이후에 B subword가 올 확률을 의미한다.
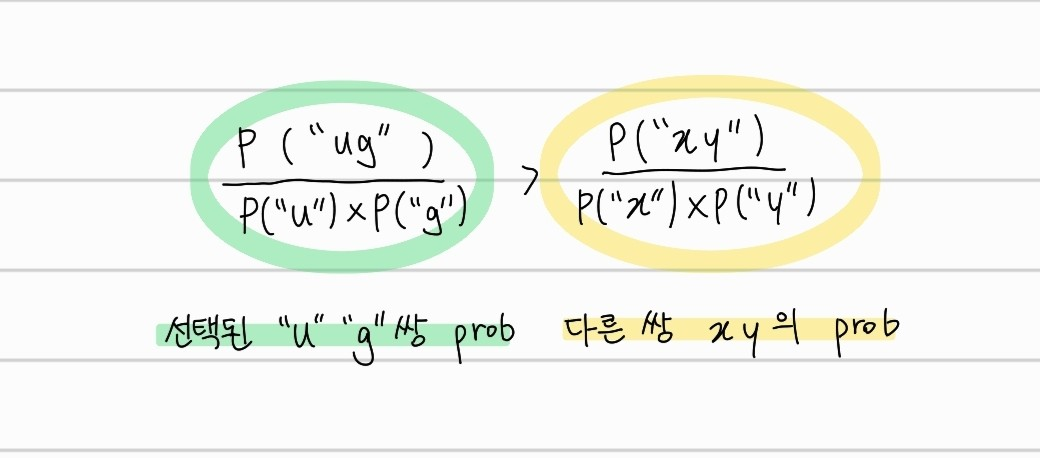
"u" 뒤에 "g" 가 오는 경우, 위와 같이 "ug"의 확률이 다른 기호 쌍보다 더 클때 병합이 이루어진다.
직관적으로 보면, BPE와 다르게 두 subword 혹은 symbol을 결합할때, 잃는 것에 대해서 평가를 함으로써, 그 병합이 가치가 있는지를 판단하는 것이다.
Unigram
BPE와 WordPiece와 다르게, Unigram은 초기 vocab을 많은 수의 기호로 설정한다. 그리고, vocab을 점진적으로 줄이는 방향으로 구축한다. 예시로, base vocab은 사전 토큰화된 단어와 가장 흔한 substring이다. Unigram은 단일로 사용되기보다 SentencePiece와 함께 transformer 계열의 모델에 사용된다.
각 학습단계에서 Unigram 알고리즘은 현재 vocab과 Unigram 언어 모델 기반으로 loss(log-likelihood)를 정의한다. vocab에서 각 기호가 제거 되었을 때, 전체 loss가 얼마나 증가하는지를 계산한다. Unigram은 학습 데이터의 손실값에 적은 영향을 미치는 기호들을 p% 제거한다.
Unigram은 병합 규칙을 기반으로 하지 않는다. 오히려 최초에 구성한 vocab에서 제거하는 방향이다. Unigram의 vocab을 기반으로 토큰화를 하게되면, 다양한 경우의 수가 나올 수 있다. 아래를 Unigram 토크나이저의 vocab이라고 생각해보자.
["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"],"hugs" 라는 단어가 text에 존재한다면 아래와 같이 세가지 방법으로 token화 될 수 있다.
- "hug" "s"
- "h" "ug" "s"
- "h" "u" "g" "s"
이 세가지 방법 중 어떻게 token화를 해야할까?
사실 Unigram의 vocab에는 subword만 존재하는게 아니라, 각 subword의 확률이 같이 저장되어있어, 각 세가지 방법에 대한 확률을 계산하는 것이 가능하다. 물론, 알고리즘은 가장 가능성이 높은 token화 경우를 선택하지만, 확률에 따라서 가능한 token화 방법을 sampling할 수 있다.
이 확률들은 tokenizer가 학습을 진행한 loss식으로 정의할 수 있다. 학습 데이터가 으로 구성되어 있고, 에 대한 tokenizer 집합이 로 정의되면 손실함수는 아래와 같다.

hugs라는 단어에 대한 여러 token화 방법에 대해서 확률을 계산한 후 손실값을 판단하는 것이다.
손실값을 계산한 이후 Unigram은 vocab내 존재하는 모든 token에 대해, 해당 token 제거시 token화 방법이 바뀌게 되었고, 손실값이 얼마나 커지는지 계산한다. 손실값에 그닥 영향을 주지 않는 token을 vocab에서 제거한다.
SentencePiece
기존의 tokenization 방법들은, 먼저 token화하는 작업을 거친다. 이는 단어 구분을 위해서 공백을 사용한다고 가정하기 때문이다. 하지만, 교착어의 특성을 가진 한글이나 중국어,일본어와 같이 띄어쓰기로 구분하기 힘든 언어는 이러한 토큰화 과정에 문제가 발생할 수 있다.
이러한 문제를 general하게 해결하기 위해서 SentencePiece는 공백도 사용할 문자 집합에 포함시켜 입력 텍스트를 공백 포함 원시 입력 스트림으로 처리하고, 공백도 사용할 문자 집합에 포함시킨다.
예를 들어, "Hello World" 라는 문장은 ["_Hello","_world"] 로 토큰화된다. 그리고, SentencePiece는 subword 모델을 구축할때, BPE와 Unigram 언어모델을 모두 지원한다.
결론
간단하게, Wordpiece tokenizer는 BERT SentencePiece tokenizer는 transformer 기반 모델에 사용된다. 그리고, Wordpiece tokenizer는 병합과정에서만 BPE와 다르다. SentencePiece tokenizer는 Unigram 알고리즘이나 BPE 알고리즘을 선택하여 subword를 구축할 수 있고, 초기 데이터에서 띄어쓰기도 하나의 token으로 생각한다는 차이가 있다.
Reference
https://huggingface.co/docs/transformers/en/tokenizer_summary#summary-of-the-tokenizers
