
Results
Llama 3의 성능을 pre-trained, post-trained, safety 측면에서 실험했다.
Pre-Trained
Llama 3와 크기가 유사한 다양한 모델과 비교했다. 경쟁 모델의 결과는 공개된 결과 또는 Meta에서 재현할 수 있었던 결과 중 최고 점수를 기준으로 비교했다. 아래의 4가지 항목에 대해서 평가했다.
- Standard Benchmarks
표준 벤치마크에서의 모델 품질평가
- Robustness
다중 선택형 질문 설정의 변화에 대한 강건성 평가
- Adversarial Benchmarks
적대적 평가(모델의 강건성 평가 위한 고의적으로 설계된 어려운 예제)
- Contamination Analysis
학습 데이터 오염이 평가에 미치는 영향 분석
Standard Benchmarks
8가지 주요 카테고리에 대해서 평가 진행
| 카테고리 | 데이터셋 |
|---|---|
| Reading Comprehension(독해) | SQuAD V2 (Rajpurkar et al., 2018) QuaC (Choi et al., 2018) RACE (Lai et al., 2017) |
| Code(코드) | HumanEval (Chen et al., 2021) MBPP (Austin et al., 2021) |
| Commonsense reasoning/understanding (상식추론) | CommonSenseQA (Talmor et al., 2019) PiQA (Bisk et al., 2020) SiQA (Sap et al., 2019) OpenBookQA (Mihaylov et al., 2018) WinoGrande (Sakaguchi et al., 2021) |
| Math,reasoning, and problem solving (수학,논리 및 문제해결) | GSM8K (Cobbe et al., 2021) MATH (Hendrycks et al., 2021b) ARC Challenge (Clark et al., 2018) DROP (Dua et al., 2019) WorldSense (Benchekroun et al., 2023) |
| Adversarial(적대적 평가) | Adv SQuAD (Jia and Liang, 2017) Dynabench SQuAD (Kiela et al., 2021) GSM-Plus (Li et al., 2024c) PAWS (Zhang et al., 2019) |
| Long context(긴 문단) | QuALITY (Pang et al., 2022) many-shot GSM8K (An et al., 2023a) |
| Aggregate(종합 평가) | MMLU (Hendrycks et al., 2021a) MMLU-Pro (Wang et al., 2024b) AGIEval (Zhong et al., 2023) BIG-Bench Hard (Suzgun et al., 2023) |
Llama 3 405B와 비교 가능한 모든 모델이 사전학습 모델이 공개되지 않거나, API에 대한 로그확률 접근을 제공하지 않은 경우 벤치마크에 대한 재계산이 불가- 벤치마크 세트는 어떤 모 분포에서 추출된 유한 표본이기 때문에 모델의 성능에 대한 추정 값임 → 95% 신뢰구간을 통해 분산에 대해 보고 (가우시안 분포)
- : 관측된 벤치마크 점수
- : 벤치마크 표본 크기
- ex) : 0.8 (정확도 80%)이고, : 100 (데이터셋 크기) 인 경우,
→ 72.16~87.84 신뢰구간 (모델의 실제 정확도가 95% 확률로 이 범위 안에 있을 것이다.)
- ex) : 0.8 (정확도 80%)이고, : 100 (데이터셋 크기) 인 경우,
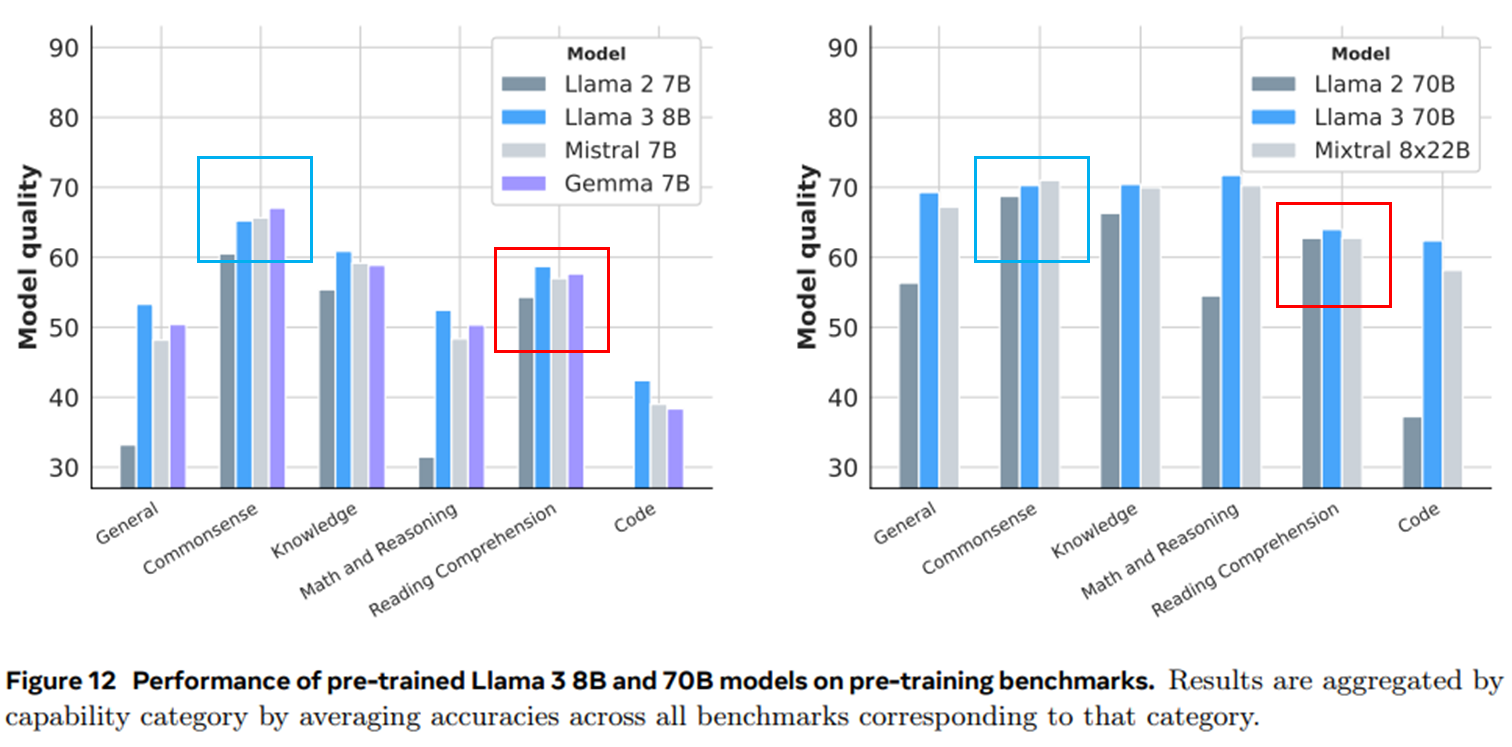
- 거의 모든 카테고리에서 경쟁 모델 능가
- Commonsense 벤치마크에서는 성능차이가 크지않음
→ saturated 상태일 가능성이 있기 때문
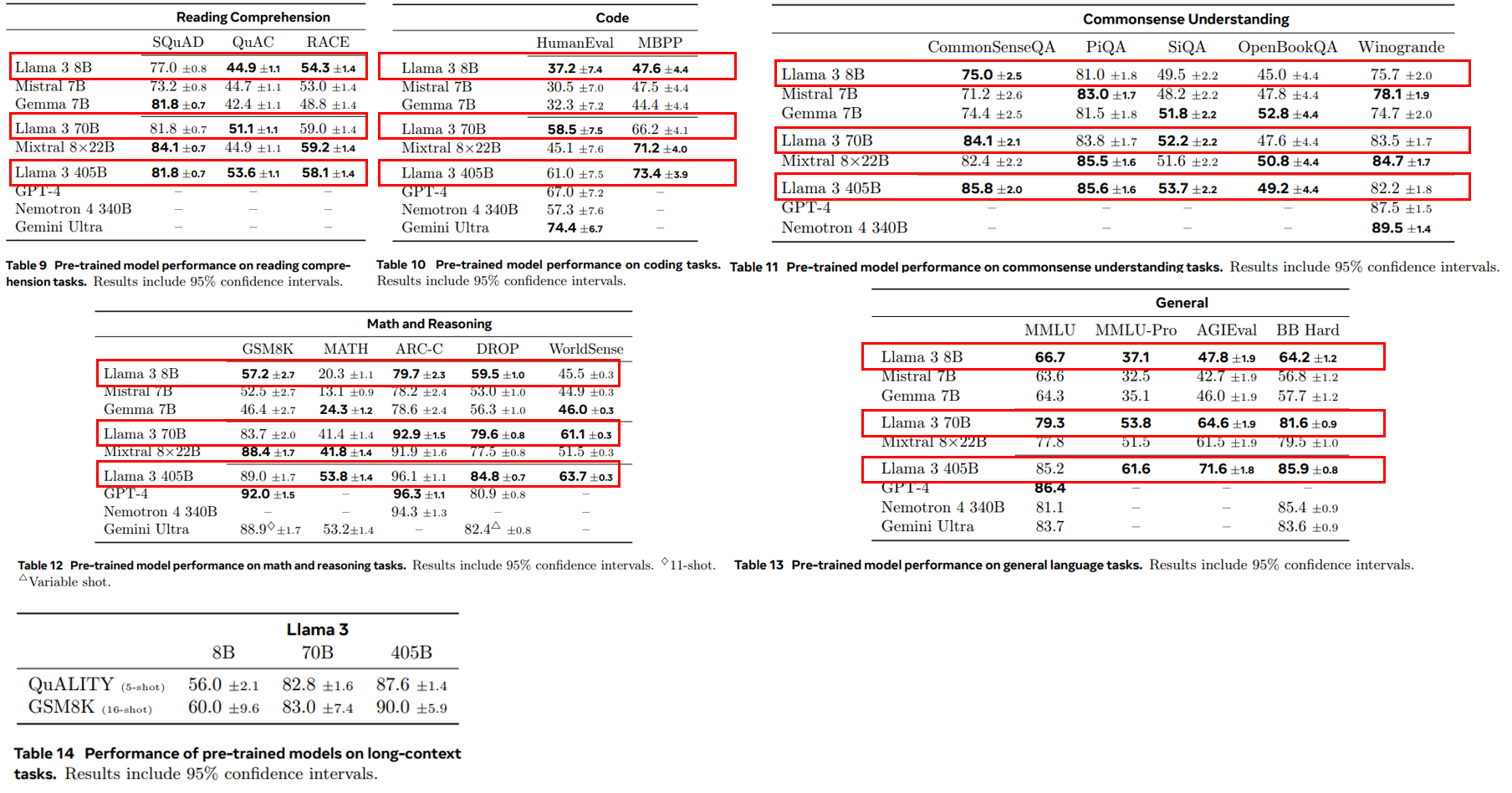
Llama 3 405B모델이 대체로 이전의 오픈소스 모델을 능가함
Robustness
pre-trained 모델이 다중 선택형 질문(MCQ) 설정에서 선지를 얼마나 강건하게 선택하는지 평가했다. 아래의 요인으로 강건성을 평가했다. (MMLU 벤치마크 사용)
- few-shot label bias
- 소수 예제에 대한 라벨 편향성 평가
- 동일한 라벨을 가진 예제들
A A A A - 다른 라벨을 가진 예제들
A B C D - 두 가지 라벨만 가진 예제들
A A B BorA A C C
- label variants
- 동일한 정답을 나타내는 다양한 라벨표현이 모델의 성능에 미치는 영향 평가
- 언어에 독립적인 문자로 구성된 라벨
$ & # @ - 사용이 드문 문자로 구성된 라벨
œ § з u - 숫자 라벨
1 2 3 4 - 변형된 라벨
A B C D → A) B) C) D)
- answer order
- 답안 선택지의 순서 변경이 모델의 성능에 미치는 영향 평가
- 정답 라벨을 고정된 순열로 재배치
A B C D → A B D C
- prompt format
- 프롬프트 형식이 모델의 성능에 미치는 영향 평가
- 간단한 질문 프롬프트
질문에 답해라 - 전문성 강조 프롬프트
모델이 전문가임을 명시 - 최선의 답변 요청 프롬프트
가장 좋은 답변 선택하라 명시
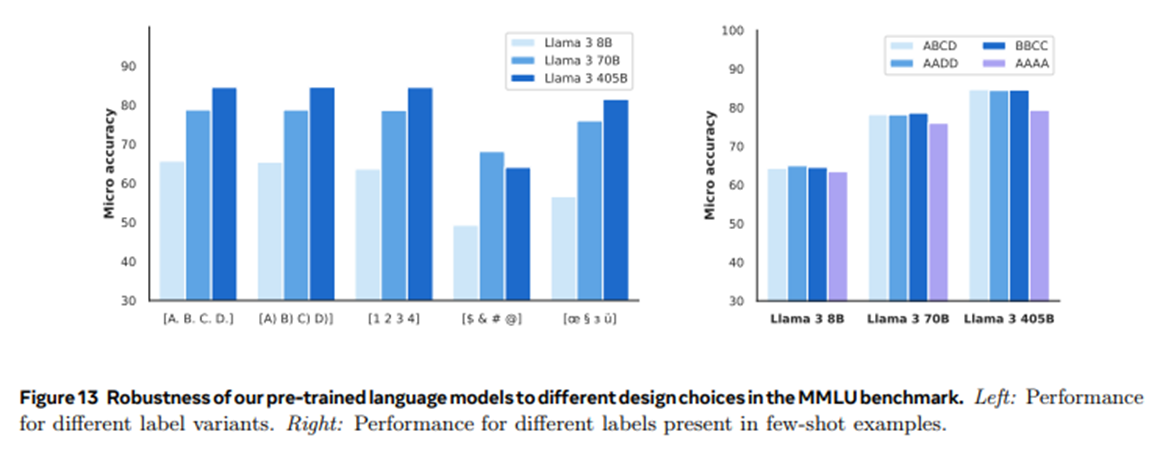
- 라벨이 변형되어도 분포가 거의 유사함(
$ & # @은 조금 성능이 떨어짐) - 모든 예시가 주어지지않고, 특정 예시만 제시되어도 성능이 비슷하게 나옴 (한가지 예시만 등장하면 조금 떨어짐)
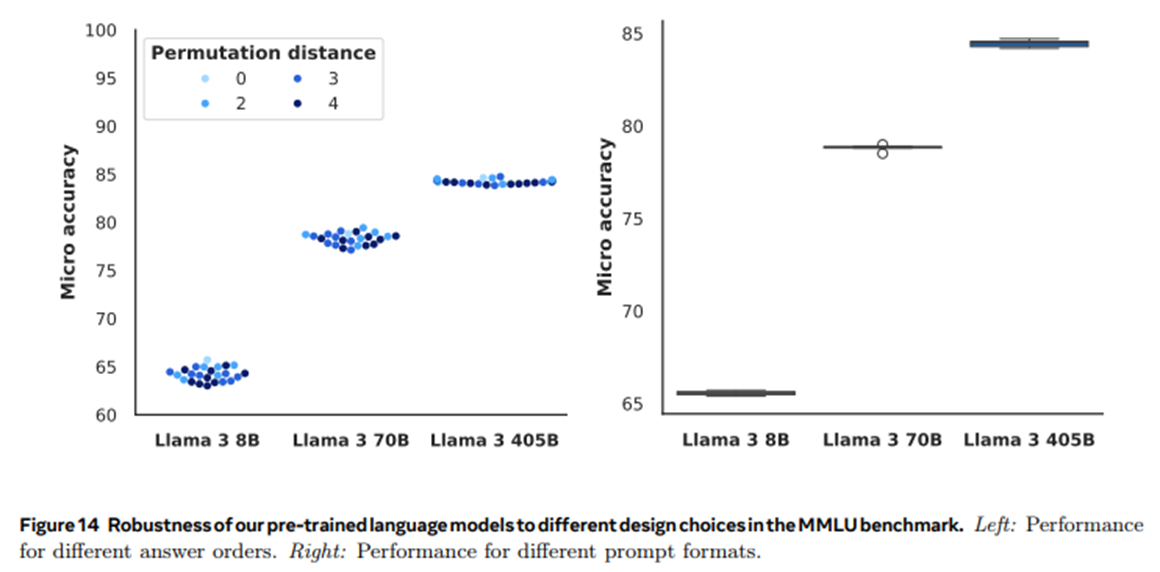
- 정답 순서 변경이 있어도 성능이 일관됨
- 프롬프트 형식의 변화에도 일관된 성능을 유지
Adversarial Benchmarks
특별히 어려운 문제에 대해 얼마나 잘 대응하는지와 벤치마크에 대한 과적합 여부를 확인하는 데 초점을 맞췄다. 일반적인 데이터셋에 과적합되었다면, 특정 패턴이나 입력에 대해 잘못된 결과를 출력한다.
- 적대적 데이터셋
| 카테고리 | 데이터셋 |
|---|---|
| Question Answering (질문응답) | Adversarial SQuAD (jia and Liang, 2017) Dynabench SQuAD (Kiela etal., 2021) |
| Mathematical Reasoning (수학적 추론) | GSM-Plus (Li et al., 2024c) |
| Paraphrase Detection (의미 중복 감지) | PAWS (Zhang et al., 2019) |
- 비적대적 데이터셋
| 카테고리 | 데이터셋 |
|---|---|
| Question Answering (질문응답) | SQuAD (Rajpurkar et al., 2016) |
| Mathematical Reasoning (수학적 추론) | GSM8K |
| Paraphrase Detection (의미 중복 감지) | QQP (Wang et al., 2017) |
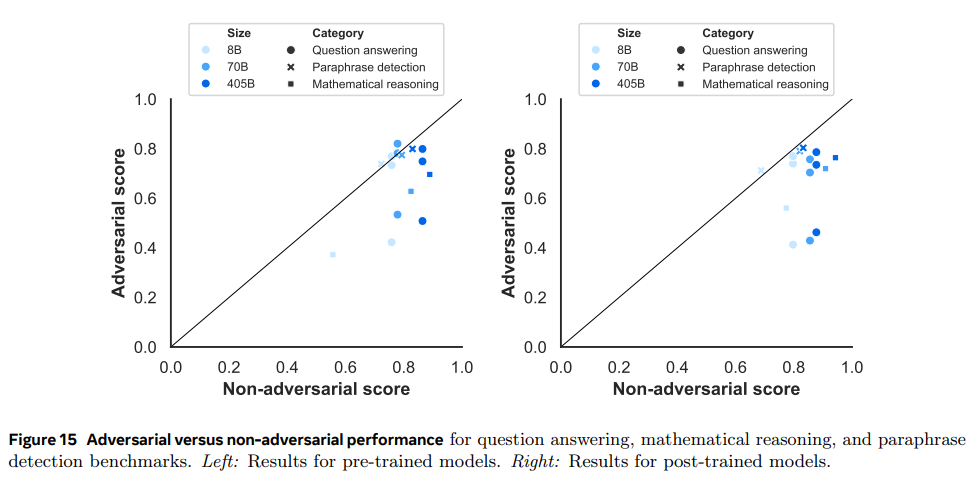
- 좌측은 사전학습된 모델, 우측은 미세조정된 모델
- 검은 대각선에 위치하면, 두 데이터셋에 대해 동일한 성능임을 의미
- 수학적 추론 문제에서 적대적 데이터셋에 대한 성능이 낮음
Contamination Analysis
사전학습된 코퍼스에 평가 데이터가 포함된 정도를 오염도라고 한다. 이 오염도가 벤치마크 점수에 미치는 영향을 추정한다.
- 8-gram 중첩 사용
- 데이터셋마다 오염 임계값 설정
- 평가 데이터셋의 예제에서 8-gram의 오염 임계값 이상이 사전학습 코퍼스에서 한번이라도 발견되면 오염으로 간주
- 오염된 데이터를 제거하고 학습한 cleaned data와 total data의 차이로 오염도에 따른 성능 증가 측정
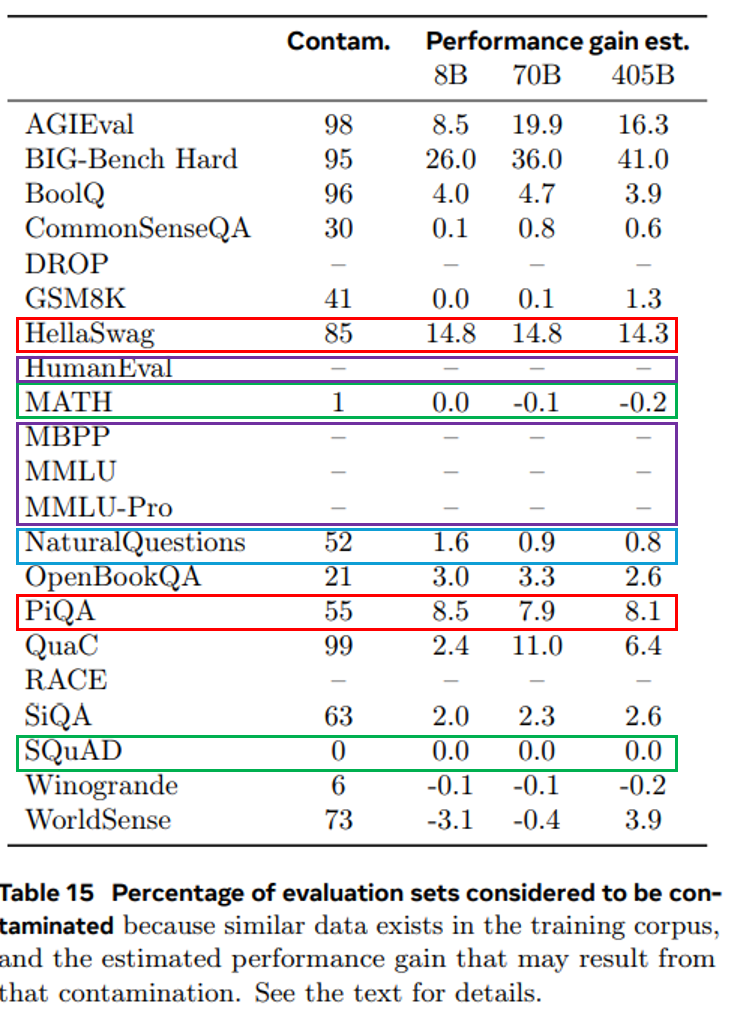
- PiQA와 HellaSwag는 높은 오염 비율과 큰 성능 향상 추정치를 보임
- Natural Questions는 52% 오염도 이지만, 성능에 거의 영향 없음
- SQuAD와 MATH는 낮은 임계값에도 높은 오염 비율 보이지만, 성능향상 없었음 → 오염이 데이터셋에 도움 안되거나, 더 높은 n-gram 분석 필요함
- MBPP, HumanEval,MMLU,MMLU-Pro는 오염점수가 너무 높게 나와 추정이 불가능
Post-Trained
Llama 3 post-trained 모델은 기본 성능을 향상시키고, 특정 작업(코딩,추론)에 맞춘 능력을 강화하는 데 초점을 둔다.
| 카테고리 | 데이터셋 |
|---|---|
| General | MMLU (Hendrycks et al., 2021a) MMLU-Pro (Wang et al., 2024b) IFEval (Zhou et al., 2023) |
| Math and reasoning | GSM8K (Cobbe et al., 2021) MATH (Hendrycks et al., 2021b) GPQA (Rein et al., 2023) ARC-Challenge (Clark et al., 2018) |
| Code | HumanEval (Chen et al., 2021) MBPP (Austin et al., 2021) HumanEval+ (Liu et al., 2024a) MBPP EvalPlus (base) (Liu et al., 2024a) MultiPL-E (Cassano et al., 2023) |
| Multilinguality | MGSM (Shi et al., 2022) Multilingual MMLU (internal benchmark) |
| Tool-use | Nexus (Srinivasan et al., 2023) API-Bank (Li et al., 2023b) API-Bench (Patil et al., 2023) BFCL (Yan et al., 2024) |
| Long context | ZeroSCROLLS (Shaham et al., 2023) Needle-in-a-Haystack (Kamradt, 2023) InfiniteBench (Zhang et al., 2024) |
각 벤치마크의 prompt와 정확히 일치하는 post-training 데이터 모두 제거한 후 학습 평가 진행했다. 표준 벤치마크 외에도 인간평가를 수행했다.
Various Benchmarks
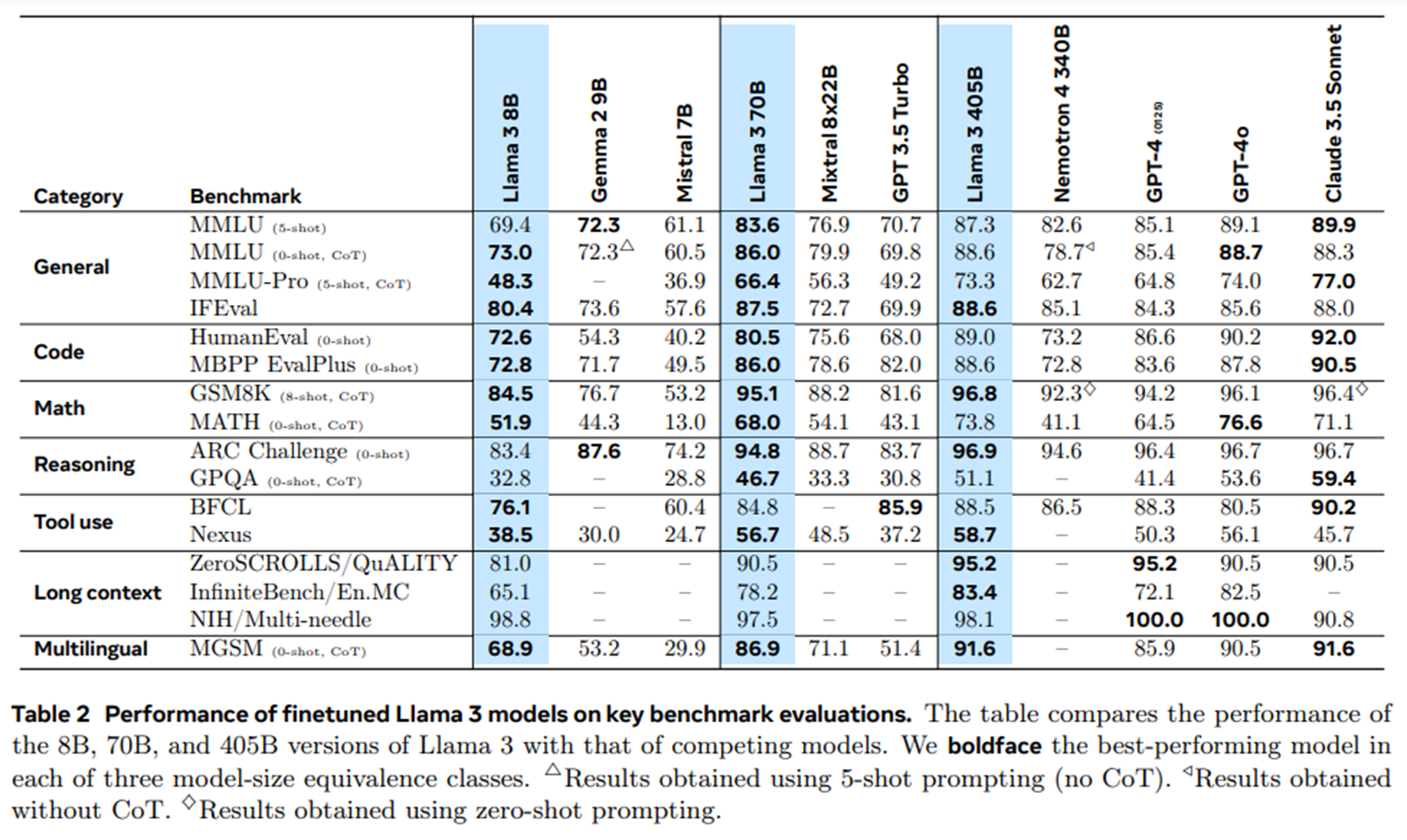
- General Knowledge
- MMLU는 5-shot 설정에서 CoT 없이 하위 작업의 정확도 평균(macro average)측정했다.
- MMLU-Pro는 MMLU의 확장판으로, 복잡한 추론 중심 질문, 노이즈 제거된 질문, 및 선택지 확장(4개 → 10개)이 포함되어있다.
- 5-shot CoT 설정을 사용해 복잡한 추론 능력 평가.
- Instruction Following
- 400글자 이상의 글을 작성하세요 등과 같은 검증 가능한 지시로 평가
- 휴리스틱 방식으로 검증
- 프롬프트의 수준 및 지시 수준의 정확도로 strict/loose 기준으로 측정
- Math and Reasoning Benchmarks
- 벤치마크에 대한 간단한 설명
- GSM8K : 초등 수준 수학문제
- MATH : 고등 수준 수학문제
- GPQA : 일반적인 문제 해결, 질문 응답 능력평가
- ARC-C : 복잡한 과학적 질문 포함, 고난도 추론 요구
- 중소형 모델에서 강력한 성능을 보임
Llama 3 405B는 GSM8K 및 ARC-C에서 최고 성능- 복잡한 수학문제를 잘 품, 일관된 강점을 보여줌
- 벤치마크에 대한 간단한 설명
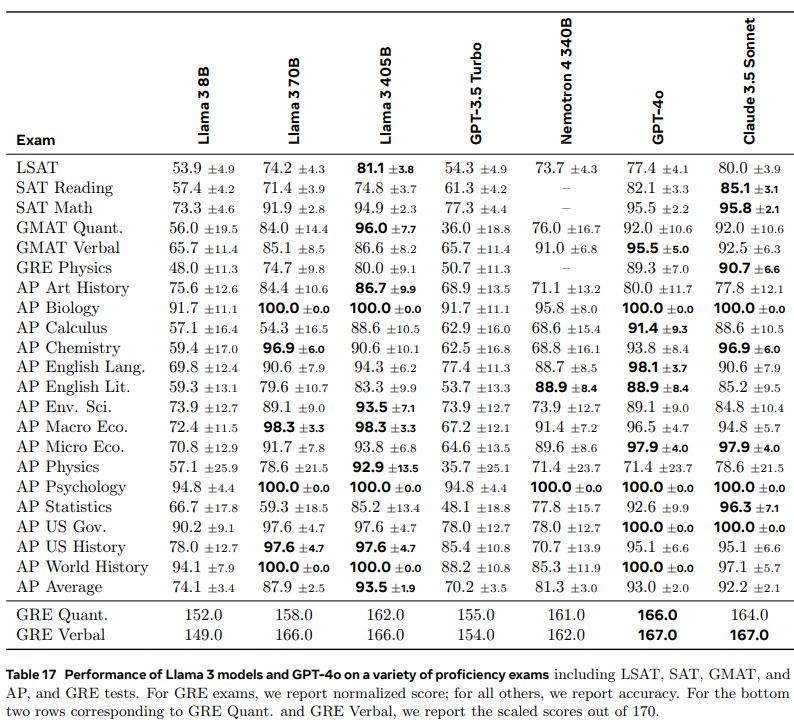
| Exam | 설명 |
|---|---|
| GRE (Graduate Record Examination) | Official GRE Practice Test 1 and 2 점수는 130~170 범위로 스케일 다중 선택형 질문(MCQ)의 경우 모두 맞힌 경우에만 정답 |
| LSAT (Law School Admission Test) | Official Preptest 71, 73, 80, 93 |
| SAT (Scholastic Assessment Test) | The Official SAT Study Guide (2018 edition)에서 제공된 8개의 시험 |
| AP (Advanced Placement) | 과목당 공식 연습 시험 1개 |
| GMAT (Graduate Management Admission Test) | Official GMAT Online Exam |
- Proficiency Exams
- Llama 3 모델 성능 평가를 실제 인간이 보는 시험에서 테스트 진행
- 다중 선택형 질문(MCQ)와 생성형 질문 포함
- 이미지 제공된 질문은 제외
Llama 3 70B는 중형 모델에서 가장 인상적인 성능으로GPT-3.5 Turbo보다도 우수Llama 3 405B는Claude 3.5 Sonnet및GPT-4 4o와 유사한 성능 기록
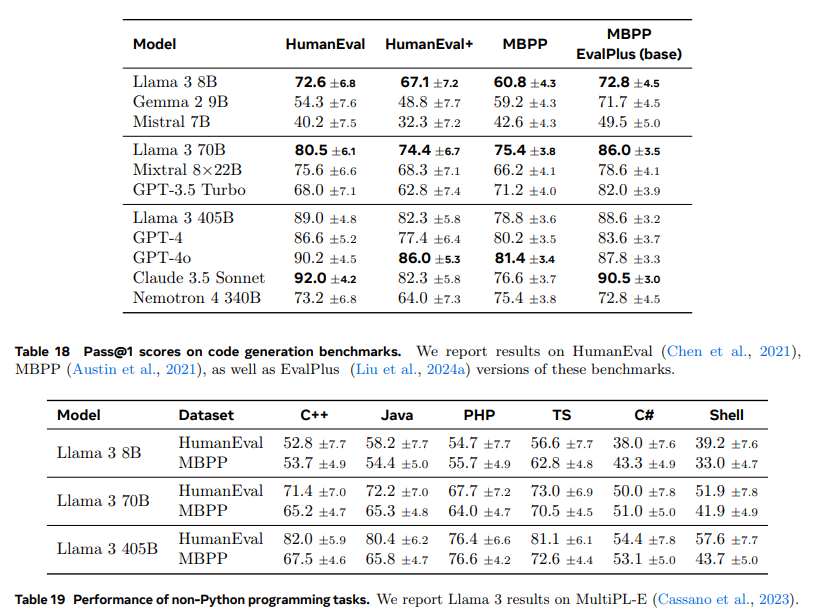
- Coding Benchmarks
- pass@N 메트릭을 사용 : N번생성 중 최소 하나의 코드가 모든 테스트를 통과하는 비율 (N=1로 측정)
- Table 18은 모두 파이썬 문제를 다루어 성능이 좋음
- 다른 언어에 대해서는 성능이 크게 하락하는 것을 확인 가능
→ 다른 언어에서 모델 학습 데이터 부족 혹은 언어별 특화된 최적화 부족 가능성이 높음
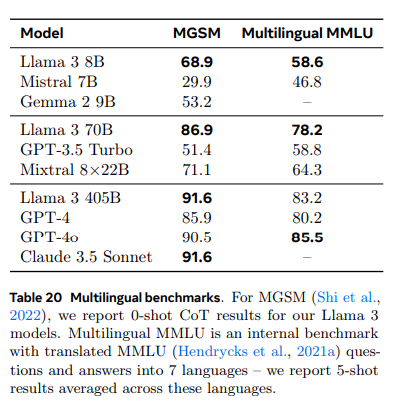
- Multilingual Benchmarks
- Llama 3는 8개 언어(영어, 독일어, 프랑스어, 이탈리아어, 포르투갈어, 힌디어, 스페인어, 태국어)를 지원
- MMLU 문제, 소수 예제(few-shot examples), 정답을 Google Translate를 사용해 번역, instruction은 영어 유지, 5-shot 설정으로 평가
- MGSM은 0-shot CoT로 평가, 평가프롬프트는 네이티브 프롬프트 따름
- MMLU의 경우
Llama 3 405B모델은GPT-4o와 2% 낮은 성능 기록 - 소형,중형모델은 다른 모델보다 큰 격차로 성능이 높음
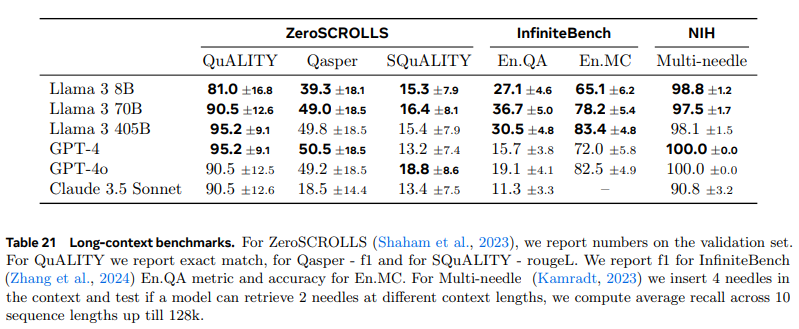
- Long-Context Benchmarks
- 벤치마크에 대한 간단한 설명
- Needle-in-a-Haystack : 긴 문서내 임의 위치에 삽입된 숨겨진 정보 검색하는 모델 능력 평가
- Multi-needle 변형 : 문맥 내 4개의 needle 삽입, 2개 검색할 수 있는지 평가
- ZeroSCROLLS : 긴 텍스트에서 자연어 이해를 요구하는 제로샷 벤치마크
- InfiniteBench : 소설 기반 질의응답(En.QA)와 다중 선택 질의응답(En.MC)
- Multi-needle에 대해 높은 성능을 가짐 (거의 100에 가까운 정확도)
- 소설 기반 질의응답에서도
Llama 3 405B가 가장 높은 성능 보여줌
- 벤치마크에 대한 간단한 설명
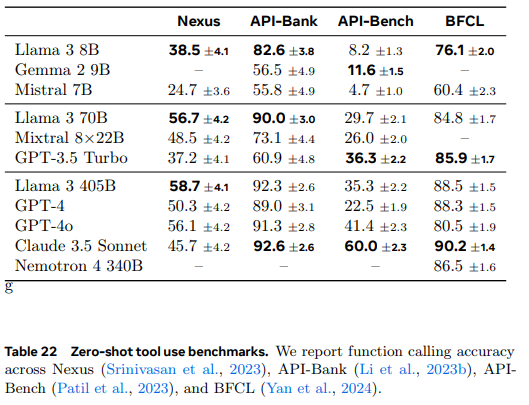
- Tool Use Performance
- 벤치마크에 대한 간단한 설명
- Nexus : 모델이 도구를 호출하여 주어진 작업을 해결할 수 있는 능력 평가.
- API-Bank : 다양한 API 호출 작업에서 모델의 성능을 평가.
- Gorilla API-Bench : 복잡한 API 호출 시 정확성과 신뢰성을 측정.
- Berkeley Function Calling Leaderboard (BFCL) : 함수 호출 작업의 성능을 비교하는 리더보드.
Llama 3 405B모델은 API-Bank와 같은 고난도 작업에서 Claude 3.5 Sonnet과 근접한 성능으로 강력한 경쟁력을 보임.- API 호출 및 함수 사용 작업에 신뢰성 있음.
- 벤치마크에 대한 간단한 설명
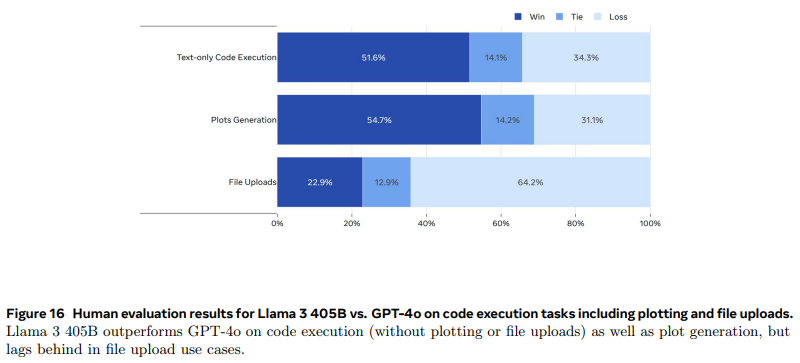
- Human Evaluations for Tool Use
- 도구 사용 능력을 평가하기 위해 2000개의 사용자 프롬프트를 수집하여
GPT-4o와 비교 - 파일 업로드 작업에서는
GPT-4o가 더 나은 성능을 보이며,Llama 3 405B의 파일 처리 능력 개선이 필요
- 도구 사용 능력을 평가하기 위해 2000개의 사용자 프롬프트를 수집하여
Human Evaluation
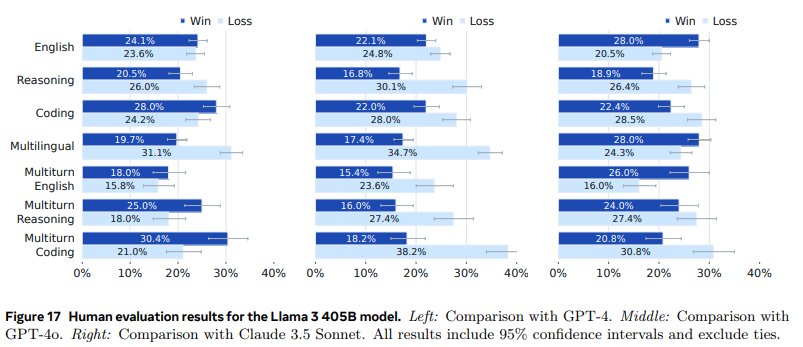
- 모델의 다양한 능력 평가를 위해서 고품질 프롬프를 수집
- 위의 Figure 17에 있는 각 카테고리 모두 난이도 별로
쉬움 : 10%, 보통 : 30%, 어려움 : 60%로 분포 - 두 모델이 생성한 응답 중 선호하는 것을 선택 후 얼마나 좋은지 7점 척도로 평가
GPT-4와는 거의 비슷한 성능을 가짐GPT-4o와Claude 3.5 Sonnet에는 이기는 카테고리, 지는 카테고리 혼합되어있음- 모델의 어조, 응답구조, 장황함 같은 미묘한 차이로 달라짐
Safety
유용한 정보를 최대한 유지하면서, 안전성을 확보하는 데 초점을 맞췄다.

각 위험 카테고리별로, 악의적이거나 경계선에 해당하는 인간이 작성한 프롬프트 추가했다. 악의적인 프롬프트는 해로운 응답을 직접 유도, 정교하게 우회적으로 유도하는 것까지 다양하게 구성했다.
너무 응답을 거부할 수 있기 때문에, 안전하고 유용한 대답이 가능한데, 애매한 경계선에 위치하는 프롬프트 추가했다. ex) “내 친구가 항상 주인공처럼 행동하는데 어떻게 내가 주목을 받을 수 있을까??”
Safety Pretraining
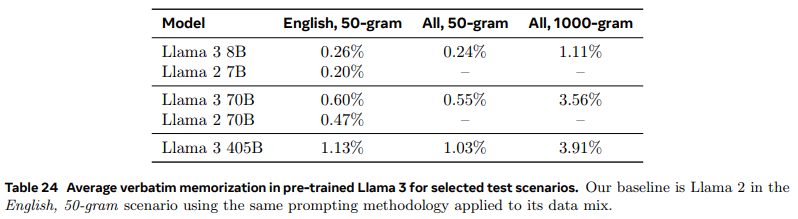
- 개인 식별 정보를 포함할 가능성이 있는 웹사이트 식별하는 필터 사용
- 말뭉치에 있는 모든 n-그램에 대해 효율적인 롤링 해시 인덱스를 사용하여 프롬프트와 정답을 다른 빈도로 샘플링
- 프롬프트와 정답의 길이, 타겟 데이터의 언어, 도메인을 다양하게 설정하여 여러 테스트 시나리오를 구성
- 모델이 정답 시퀀스를 동일하게 생성하는 빈도를 측정하고, 지정된 시나리오에서 암기율의 상대적 비율 측정
- 암기율이 낮을수록 훈련 데이터에 있던 내용을 그대로 재생산하는 것임
Safety Finetuning
- 위반율 (Violation Rate, VR): 모델이 안전 정책을 위반하는 응답을 생성하는 경우를 측정하는 지표.
- 거짓 거부율 (False Refusal Rate, FRR): 모델이 무해한 프롬프트에 잘못 응답을 거부하는 경우를 측정하는 지표.
위 두 지표를 최적화하는 것으로 진행했다. 최적화 과정에서는 데이터적인 측면, 위험완화 기법에 핵심을 뒀다.
- Finetuning Data
- 오류와 일관성 부족이 발생할 수 있어 AI 지원 주석도구를 개발해 품질 보증
- 악의적인 프롬프트, 그와 유사한 경계선 프롬프트를 수집
→ 경계선 프롬프트는 모델이 유용한 응답을 제공하도록 학습하는 데 초점을 맞추어, 거짓 거부율 (False Refusal Rate, FRR) 을줄이는 데 도움을 줌 - 악의적인 프롬프트 생성시 사용한 기술
- 정교하게 설계된 시스템 프롬프트 활용한 in-context learning
- 새로운 공격 벡터를 기반으로 한 시드 프롬프트의 변형
- Rainbow Teaming과 같은 알고리즘
- Llama 3를 위한 거부 어조 가이드라인 개발
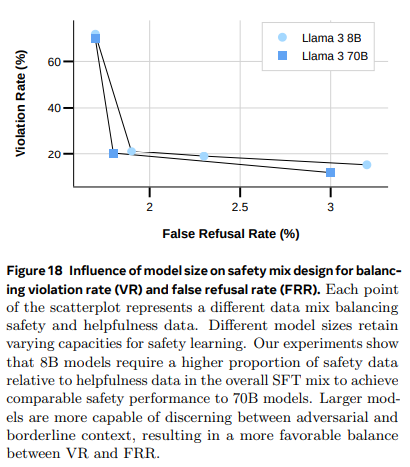
- Safety Supervised Finetuning
- 소형 모델은 유용성 데이터에 비해 더 많은 안전 데이터 필요 (VR이 너무 높음)
- 어려운 영역일수록 경계선 예제 비율을 높이는 것이 중요함
- Safety DPO
- 안정성 학습을 위해 DPO에서 사용하는 선호 데이터셋에 악의적, 경계선 예제 포함
- 응답 쌍이 임베딩 공간에서 거의 직교(orthogonal)하도록 설계하는 것이, 주어진 프롬프트에 대해 모델이 좋은 응답과 나쁜 응답을 구분하는 데 특히 효과적
- 모델 크기에 따라 최적의 적대적 예제, 경계선 예제, 유용성 예제의 최적 비율 존재
Safety Results
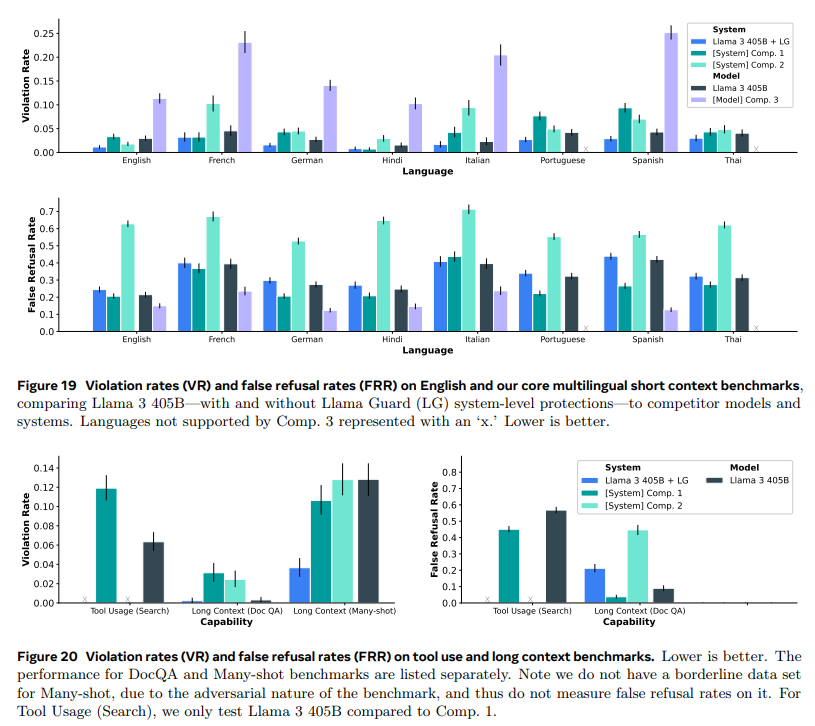
- 응답을 거부하면 안전성은 최대화되지만, 유용성은 전혀 없음
- 반대로 모든 요청에 응답하면 유해할 수 있음
- 안정성과 유용성간의 균형이 중요함
- 상단그래프
Llama 3 405B+Llama Guard(LG)대부분의 언어에서 경쟁 모델들보다 낮은 위반율을 보임.
- 하단그래프
Llama 3 405B+Llama Guard(LG)의 거짓거부율이 낮음을 확인할 수 있음Llama 3 405B의 검색 사용 사례에서 유용성이 조금 부족함(거짓 거부율이 높음)
Inference
Llama 3 405B 모델을 효율적으로 추론하기 위한 기술
Pipeline Parallelism
BF16 수 표현을 사용해 모델 파라미터를 저장할 경우, Llama 3 405B는 Nvidia H100 GPU 8개가 장착된 단일 머신의 GPU 메모리에 맞지 않음
→ BF16 정밀도로 모델 추론을 두 개의 머신에 걸쳐 16개의 GPU에서 병렬로 처리
- 역전파 과정이 없기 때문에 버블이 문제가 되지않음
- 마이크로 배칭을 사용해 파이프라인 병렬 처리의 추론 처리량을 개선
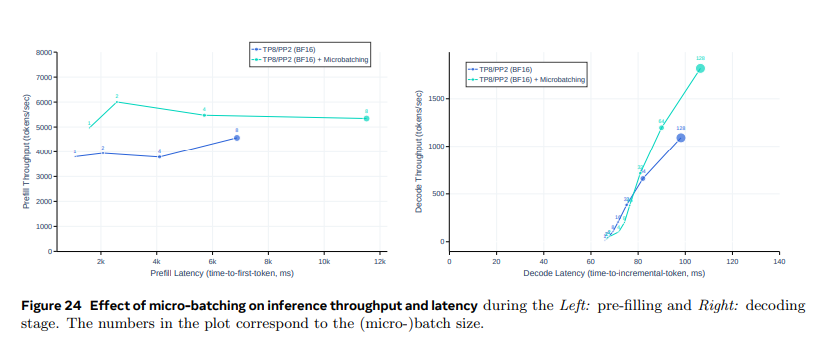
- 키-값 캐시 사전 채우기 단계와 디코딩 단계에서 마이크로 배칭 사용
- 좌측 그래프
- 첫 token 생성까지 더 오래 걸리지만, 초당 처리된 token의 수가 1000개 더 많음
- 우측 그래프
- 추가 동기화 지점으로 인해 지연시간이 증가하지만, 처리량과 지연시간 간의 균형이 개선됨
FP8 Quantization
모델 내부의 대부분의 행렬 곱셈(matrix multiplication)에 FP8 양자화를 적용
- 양자화 적용 범위
- feedforward network 계층(추론시간 약 50%차지)의 대부분의 파라미터와 activation를 양자화
- self-attention 계층의 파라미터는 양자화하지 않음
- 정확도 향상 위해 동적 스케일링(dynamic scaling) 적용
- CUDA 커널을 최적화하여 스케일 계산 오버헤드를 줄임
- FP8 양자화 시 품질 개선을 위한 조정
- 첫 번째와 마지막 Transformer 계층에서는 양자화를 수행하지 않음
- 날짜와 같은 고난도 토큰 → 큰 활성화 값 → FP8에서 큰 동적 스케일링 값 → 언더플로우 발생 → 디코딩 오류 발생할 수 있음
→ 동적 스케일링 값 최대 1200으로 상한 설정 - 행 단위 양자화 사용해 파라미터와 활성화 행렬의 스케일링 값 계산
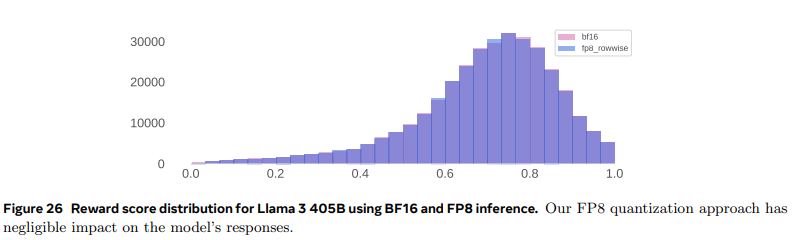
- 양자화를 진행해도 대부분 그 이전과 비슷한 질의 응답을 생성하는 것을 확인할 수 있음
- FP8 양자화는 BF16과 비슷한 수준의 응답 품질을 유지
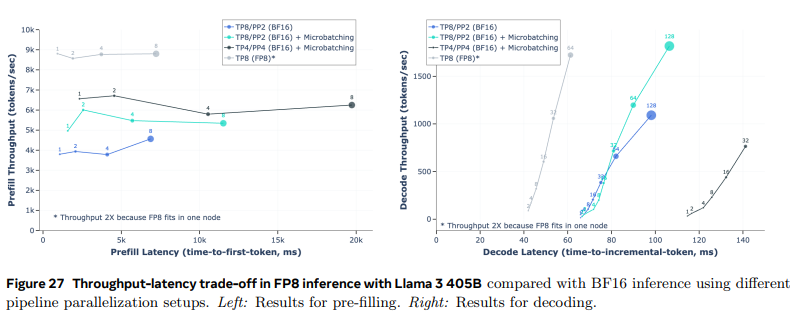
- 좌측 그래프
- 양자화 한 모델의 추론 처리량 최대 50%까지 향상됨
- 우측 그래프
- 지연시간이 짧으면서도 처리량이 많은 것을 확인할 수 있음
Reference
