
❗Before Read ❗
완벽하게 순서대로 논문을 인용한 것이 아니고 부분부분 첨부하여 순서가 조금 다르거나 없는 부분이 있을 수 있습니다!
ABSTRACT

- LLM 기반 evaluator는 정답없이 평가가 가능하다

- 하지만, 단일 agent시 bias 존재해 한계가 있다
- bias : agent가 특정 문장구조나 내용을 선호하는 응답을 가지게됨

- multi agent 기반한 DEBATE 기법
- agent A가 agent B의 의견을 비평하게끔 설계
- agent의 bias를 해결

- NLG 평가의 메타 평가 벤치마크인 SummEval 및 TopicalChat에서 이전 SOTA 능가
- agent 의견간의 폭, agent의 페르소나가 evaluator에 영향을 준다
Introduction

- 기존의 사전학습된 모델을 통한 문맥정보 평가는 인간의 평가와 상관관계 ↓
- 비용이 많이 드는 인간 주석 데이터에 크게 의존

- LLM 기반 NLG 평가는 task 특화된 prompt 필요, output token의 확률로 채점
- 비판, 후처리 없는 응답(채점결과) 은 내재된 편향에 취약

- DEBATE (Devil’s Advocate-Based Assessment and Textual Evaluation) 은 multi agent
- Commander : debate leader
- Scorer : calculate scores
- Critic : provide constructive criticism on scores
- 요약, 대화 생성에서 NLG 평가 벤치마크에서 최고 성능 기록
Method
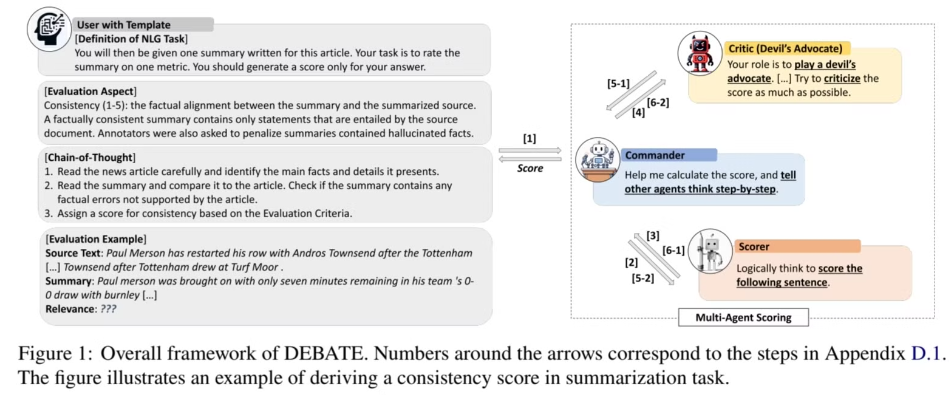

- Figure 1에 있는것처럼, DEBATE는 세 주요 구성으로 이루어져있다.
- NLG task에 대해서, 사전 정의된 template 과 evaluation aspect
- agent간 debate 포함된 scoring framework
- Scorer 비평을 위한, Devil’s Advocate prompt
사전 정의된 template

Liu et al. “G-EVAL: NLG Evaluation using GPT-4 with Better Human Alignment”
- GPT-4를 사용하여 자연어 생성(NLG) 모델 평가를 수행하는 새로운 방법을 제안한 연구
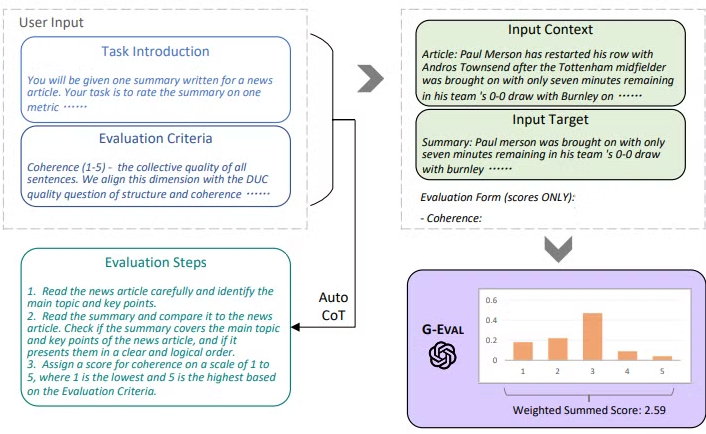
- 위의 prompt를 작업 설명과 평가 측면 정의의 기반으로 참조
- 모든 agent마다 동일한 debate 표준으로 판단할 수 있게
- zero-shot (LLM에 예시를 주지않음)
- chain-of-thought (LLM에 thought의 순서 가르쳐줌)
Multi- Agent간 debate 포함된 scoring framework


MacDougall and Baum The devil’s
advocate: A strategy to avoid groupthink and stimulate discussion in focus groups.
- focus groups을 위해서 devil’s advocate를 건설적으로 상상했다.
- focus group과 다른 관점을 가진다.
- 다른 방법으로 질문을 한다.
- focus group이 미성숙한 결론에 도달하는 것을 막는다.

- 세 agent가 다른 역할 수행
- Commander
- 이전 토론의 정보를 전달해 Critic과 Scorer의 대화를 촉진함.
- agent가 이전 대화 회상하는 능력 부족해 필요함.
- 집합적 기억의 역할 수행
- Scorer
- 특정 지시에 따라 text를 평가
- Critic
- Scorer와 토론하며 건설적인 비판 제공
- Devil’s Advocate 역할 수행
- Commander
Devil's Advocate
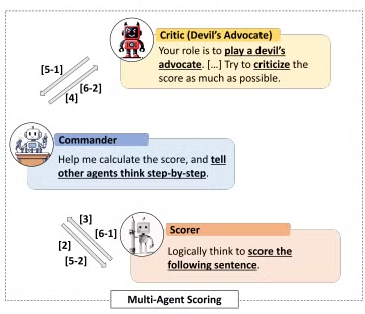
Devil’s Advocate prompt
Your role is to play a Devil’s Advocate. Your
logic has to be step-by-step. Critically review
the score provided and assess whether the
score is accurate. If you don’t think that the
score is accurate, criticize the score. Try to
criticize the score as much as possible.
- Devil’s Advocate의 prompt는 위와 같다.
Experiment result


- SummEval
- 요약 평가 데이터셋
- 유창성,일관성,일치성,관련성 에 대한 인간 평가 점수를 제공
- Topical-Chat
- 지식기반 인간 간 대화 데이터셋
- 자연스러움,일관성,흥미도,근거성 을 평가
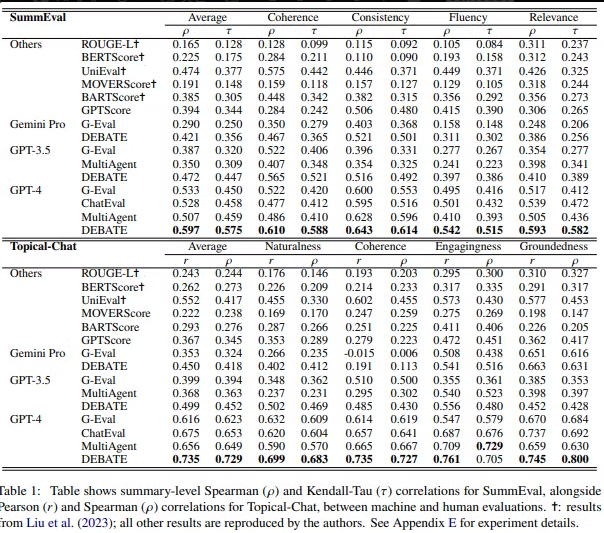
- 피어슨 상관계수 :
두 연속형 변수간 선형적 관계를 나타내는 지표
- 켄달 타우 상관계수 :
두 순위 변수 간의 일관성 나타내는 지표
concordant pair → A가 키고 크고 A가 몸무게도 더 나간다. (키와 몸무게의 상관계수 비교시)
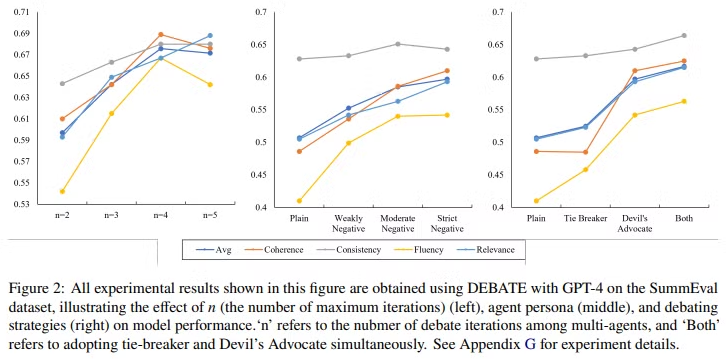
- n (토론한 횟수) 가 증가하면 전반적으로 성능이 증가하지만, 하락하는 부분도 있음 → 최적의 n이 존재
- Critic의 페르소나 비판의 강도를 조절하여 매우 부정적 부터 중립적까지 테스트해본결과, 부정적으로 바라볼수록 성능이 좋았음
- 토론이 결론에 이르지 못했을 때, tie-breaker와 devil’s advocate 동시 사용시 성능이 좋음
Tie-breaker



- NLG task와 aspect prompt로 system에 입력
- Commander → Scorer 점수와 이론적 해석 요구
- Scorer 계산 → Commander
- Commander → Critic
- Critic 피드백 사용해 Scorer에 점수조절 지시
- Critic에게 다시 검증 요청, NO ISSUE 선언까지 loop
- 위의 과정을 진행하다가 NO ISSUE가 끝까지 나오지 않을 때(Scorer와 Critic 합의 실패시 ), Tie Breaker를 통해 점수 결정
Tie-breaker prompt>
Tie-breaker: You are a Tiebreaker. You will be
given a news article. You will then be given one
summary written for this article. You will also be
given a debate log of other agents, about the rate of
the summary.Your role is to take a side between the
Scorer and the Critic when they disagree about the
quality of a summary, and to give the final score.
Scorer’s role is to logically think to score the quality
of a summary. Critic’s role is to check if the score is
justified, and give feedbacks to Scorer. You should
read the Debate Log of Other Agents and decide the
final score according to the following Evaluation
Criteria and the Evaluation Steps.
- 기사에 대한 토론 내용과 점수를 받을거야
- Scorer와 Critic중에 편을 골라
- Scorer와 Critic 의 역할은 ~~야
- 평가 기준과 평가 단계 따라서, 최종 점수를 골라
Conclusion
단일 agent가 편향된 평가를 내리는 것을 어느정도 완화하기 위해서, LLM을 활용해 debate방법을 적용한 metric이다. 여기서, 실제로 LLAMA와 같은 8B 모델로 진행해본 결과는 아직 meta 평가는 진행하기 쉽지않았다고 한다. 과거의 비용을 기준으로는 매우 비싼 LLM을 사용해서 평가하기 쉽지않았지만 현재 가격이 매우 싸지면서 완화된 상태라고 볼 수 있다고 한다.
Reference
DEBATE: Devil’s Advocate-Based Assessment and Text Evaluation
MacDougall and Baum The devil’s
advocate: A strategy to avoid groupthink and stimulate discussion in focus groups.
Liu et al. “G-EVAL: NLG Evaluation using GPT-4 with Better Human Alignment”
