
📌정의
재귀함수란? 함수에서 자기 자신을 다시 호출해 작업을 수행하는 함수이다. 재귀함수는 일정 조건이 충족되면, 함수를 이탈해 결과를 도출한다.
def function(input):
if input==1:
return input
else:
return function(n-1)주로 재귀함수를 종료시키는 기저사례가 코드의 최상단에 위치한다. 메인로직은 모두 같고, 전달인자만 변하는 것이기 때문에, 반복적인 수행과정에서 주로 사용한다.
ex) 피보나치 수열
def fibonacci(n):
if n==0 or n==1:
return n
return fibonacci(n-1)+fibonacci(n-2)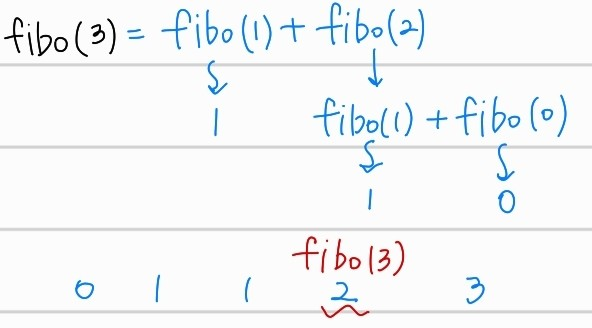 이처럼 그림으로 나타내면 더 쉽게 재귀함수의 호출과정에 대해서 이해할 수 있다.
이처럼 그림으로 나타내면 더 쉽게 재귀함수의 호출과정에 대해서 이해할 수 있다.
📌재귀함수에 대한 접근
1. 재귀함수의 필요성
재귀함수는 사실 반복문으로도 구현이 가능하다. 오히려, 일반적으로 성능은 반복문이 더 좋은편이다. 재귀함수는 스택에 함수와 관련된 정보가 쌓이게 된다. 선언 지점으로 점프하는 반복문보다 더 복잡한 편이다. 함수가 끝나지않는 상태에선 계속 스택에 쌓이기 때문에 메모리를 많이 차지하는 재귀함수의 필요성에 대해서 먼저 생각하고 접근해야한다.
꼬리 재귀 최적화
재귀함수에서 메모리에 대한 성능을 높이기 위한 방법이다.
1) 반환값이 재귀 호출 결과값일 때
2) 컴파일러가 꼬리 재귀 최적화를 지원할 때
위 두 가지 조건을 만족할 때 사용 가능하다. 쉽게 생각해 꼬리 재귀는, 재귀함수의 호출이 끝난 후에, 추가적인 연산을 요구하지 않도록 구현하는 형태이다. 메모리 성능이 높아지는 이유는, 값이 변할 여지가 없기 때문에, 스택을 재사용하기 때문이다.
ex) 팩토리얼 연산
일반적인 재귀함수
def Factorial(int n):
if (n == 1):
return 1
return n * Factorial(n-1)
꼬리 재귀함수
def FactorialTail(int n,int acc):
if (n == 1):
return acc
return FactorialTail(n-1,acc*n)
def Factorial(int n):
return FactorialTail(n,1)둘의 차이는 아래와 같다. 바로 반환하면서 추가적인 연산이 필요하지 않다는 점이다.
<일반적인 재귀함수>
호출 : Factorial(3)
3 * Factorial(2)
3 * ( 2 * Factorial(1) )
3 * (2 * 1)
3 * 2
6<꼬리 재귀함수>
호출 : Factorial(3,1)
FactorialTail(2,3)
FactorialTail(1,6)
6
6
6꼬리재귀 최적화를 하거나, 실행횟수가 엄청 많은 경우가 아니라면 재귀함수로 구현하는 것에 큰 문제는 없지만, 반복문은 아예 그런 문제가 없으니 성능쪽으론 반복문이 우세하다.
하지만 재귀문을 써야하는 이유가 두개 있다.
1. 재귀적인 자료구조나 풀이 공식이 있음
재귀적인 자료구조
어떤 자료 구조안에 자료구조가 중첩되어있는 형태를 다룰때는 재귀함수가 필요하다.
재귀적인 풀이공식
팩토리얼, 피보나치 수열, 순열/조합 등 답을 구하는 공식이 재귀적인 경우 사용한다.
ex) f(n)=f(n-1)+f(n-2) 피보나치 수열재귀적인 자료구조 혹은 풀이공식이 있는 경우 재귀로 구현시 코드가 훨씬 더 깔끔해지고, 방법이 명료하게 나타나게 된다.
🪄 정리하자면,
- 링크드 리스트, 트리, 글드, 중첩배열 등 자료구조가 재귀적일때
- 규칙성을 찾아보니 재귀적일때
2. 변수 선언이 없이 코딩
함수형 프로그래밍에서 값을 변하지않는 상수(immutability)로 선언하는데, 이때 재귀가 유용하다. 재귀는 함수 호출마다 새로 스코프를 생성해서 따로 변수없이 구현이 가능하다.
2. 베이스 조건
더 이상 자기 자신을 호출하지않는, 기저 사례에 대해서 먼저 생각해야한다. 가장 단순한 작업으로, 바로 답을 구할 수 있는 쉬운 상황을 우선적으로 생각해야한다.
-
바로 답 구할 수 있는 단순한 input 생각하기
가장 간단한 0,1인 경우가 많다.
배열 인자라면, 배열의 길이가 0인경우, 1인경우
트리 인자라면, 잎노드가 인력될 경우, 자식노드가 잎노드일경우
2차원(mxn 그리드)라면, (0,0)인경우 / (1,0) (0,1)인 경우 / (1,1)인 경우
위의 예시와 같은 input값이 들어올때 바로 답이 구할 수 있다면 베이스 조건에서의 결과값이다. -
문제에서 요구하는 데이터 타입 생각하기
문제에서 요구하는 데이터 타입을 생각해서 베이스 조건의 결과값이 데이터 타입과 같아야 한다는 걸 생각하면 더 쉽게 다가갈 수 있다.
트리 안 경로의 노드값 총합 : 정수
트리 의 경로 자체 : 트리의 노드 타입
3. 분해
베이스 조건에 가까워지도록 input인자 조절하는것이 필요하다. 결국 최초의 문제를 더 작게 만드는 과정이기 때문에, 베이스 조건에 가까워지도록 구현해야한다. 재귀 호출시, input인자를 한단계 작게 만드는 것으로 조작한다. n이라는 정수를 받은 함수가 재귀 호출시, n-1을 input인자로 넣는 식으로 해야 input값이 간단해진다. 어떤 식으로 조작해야하는지 패턴이 어느정도 있다.
흔한 분해 패턴
정수 : 대체로 n-1 or n-2
배열 : 앞의 숫자를 하나 없애고 길이 줄이기, [0,1,2,3]→[1,2,3]
링크드 리스트 : 포인터가 가리키는 다음 노드 or 다다음 노드
트리 : 자식 노드 하나 (이진 트리는 재귀 호출 2번 하는 경우 多)
정확히 위의 예시와 같진 않다. 마지막 4단계에서 분해에 대한 힌트를 얻는 경우가 많다.
4. 조합
조합은 베이스 조건에 걸려서 멈춘뒤 일어나는 작업. 결과 값들을 차례로 반환하는 그 과정을 다 머릿속에 그릴 필요는 없다. 특정 단계만 미시적으로 봐서 생각하고 결과를 도출해내는 것이 편하다. '특정 단계에서 바로 이전 재귀호출의 답으로 현재 단계에서 어떤 값을 도출할 것인가' 를 생각하면 된다.
1.베이스 조건 바로 위 단계
베이스 조건에 도달했을때, 바로 위 단계의 함수를 생각하는 것이다.
n==1 의 베이스 조건 → 분해 func(n-1) 바로 윗단계의 함수는 n=2일때의 함수이다.
len(arr)==1 의 베이스 조건 → 분해 func(arr.remove(at:1)) 바로 윗단계의 함수는 arr길이가 2일때이다.
2.베이스 조건 3단계 위
어느정도 위의 단계면 된다 사실 3단계일 필요는 x
n==1 의 베이스 조건 → n=4일때가 3단계 위
3. 일단 믿기(Recursive leap of faith)
바로 아랫단계의 재귀호출에서 정답이 반환될거라고 가정하는 것이다. 3단계 위여도 재귀호출 2번 등장하는 트리, 4번 등장하는 그리드 탐색은 실행 순서가 복잡하기 때문에, 그냥 호출되는 아랫단계에서 정답이 나왔다고 가정하고 구현하는 것이다.
4. 1,2번의 케이스 공통점 찾기.
1,2에서의 조합을 똑같은 방식으로 일치하게 하고, 둘이 정확한 답이 나온다면, 재귀 설계는 끝이다. 공통적인 규칙을 가진 점들 중 두개를 찍고 연결하면 직선이 되고, 그 직선위에 점들이 모두 존재하는 것처럼, 자연스럽게 선형적으로 답이 도출된다.
🪄위 4단계의 접근이 유일한 풀이법은 아니지만, 해당 접근법으로 천천히 설계하면 재귀함수 관련된 구현에 어려움을 덜 수 있을 것이다
