아래 첨부 이미지들은 사내 API 서버 중 스케줄러 서버의 개발환경 모니터링 시스템 이미지를 첨부하였고,
Jetty Statistics 카테고리의 이미지들은 API Gateway 서버의 이미지입니다.
프로메테우스 데이터 보존 기간 설정
아래에서 현재 값을 나타내는 지표(ex. Uptime, Heap Used)를 제외한 나머지들은 프로메테우스에서 기본적으로 15일간의 데이터만 저장합니다.
Retention 기한을 수정하고 싶을 경우 Docker 실행 시 아래와 같은 옵션을 추가해야 합니다.
docker run
-v /{docker로 구동중인 프로메테우스&그라파나 위치}/config:/etc/prometheus
-v /{docker로 구동중인 프로메테우스&그라파나 위치}/volume:/prometheus
-d --name prometheus -p 9090:9090 prom/prometheus
--storage.tsdb.retention.time=20d // <------------ 이 부분 추가. 20일로 기한을 연장시킬 경우의 예시 이때, 저장 공간을 효율적으로 관리하기 위해 이전 데이터를 삭제할 뿐, 기존에 수집된 데이터 값 자체를 0으로 초기화하지는 않습니다.
따라서 특정 시간 동안의 증가량 등을 측정하는 데에 적합한 용도이므로, 전체 카운트에서 추가로 변화된 부분이 없는지를 확인하는게 적합합니다.
만약 강제로 특정 메트릭 값을 삭제하고 싶다면, 아래와 같이 curl 명령어로 Admin API를 호출할 수 있습니다. (Connection Timeout Count 대시보드의 값을 0으로 초기화하는 예시)
curl -X POST -g 'http://{서버주소}:{포트}/api/v1/admin/tsdb/delete_series?match[]={__name__="Connection Timeout Count"}'프로메테우스 쿼리 로그 파일 삭제
/{docker로 구동중인 프로메테우스&그라파나 위치}/config로 들어가면 query_log_file.log 파일이 존재합니다.
프로메테우스 도큐먼트에서는 자체적으로 쿼리 로그에 대한 관리 기능은 제공하지 않는다고 하여, Linux에 기본적으로 들어가있는 log rotate 명령어를 사용하라고 권장되고 있습니다.
/etc/logrotate.d 에 prometheus 라는 이름으로 아래와 같이 작성하면, 일주일치 로그만 유지하고 나머지는 삭제한다고 합니다.
/{docker로 구동중인 프로메테우스&그라파나 위치}/config/query_log_file.log {
daily # 로그 파일을 일별로 rotate
rotate 7 # 주기가 7
compress # 압축
delaycompress # 압축 전, 잠시 delay
postrotate # script 시작 명시
killall -HUP prometheus # script (prometheus 프로세스에게 HUP 신호를 보내서 로그 파일을 다시 열도록)
endscript # script 종료 명시
}💡 Basic Statistics
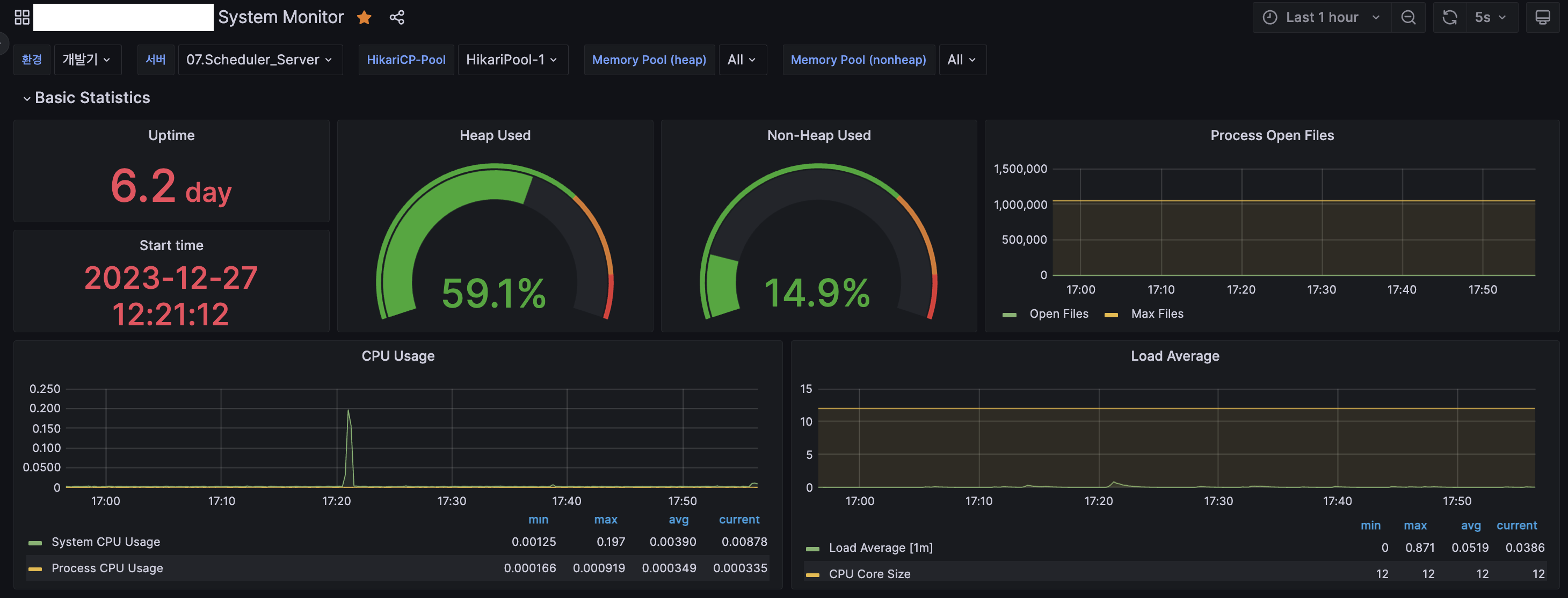

Heap Used

: JVM의 Heap 메모리 영역에서 현재 사용 중인 메모리 양을 표시
→ Heap 영역은 주로 객체 인스턴스나 배열 등을 저장하는 데에 사용
Non-Heap Used
: JVM의 Heap 영역 이외의 메모리 영역에서 현재 사용 중인 메모리 양을 표시
→ 주로 JVM 자체의 동작에 필요한 메타데이터, 스레드 관련 정보를 저장한다.
Non-Heap 영역이란?
Non-Heap 영역은 JVM이 시작될 때 미리 할당되며, 주로 클래스와 메타데이터 관리 등을 담당.
→ 메모리 사용량이 높은 경우 성능 저하 또는 OutOfMemoryError 와 같은 메모리 관련 문제가 발생할 수 있다.
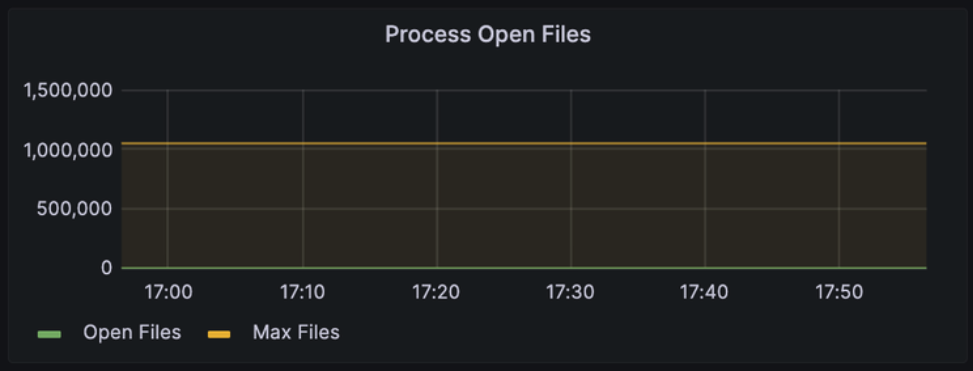
Process Open Files
: 프로세스가 현재 열어놓은 파일의 수를 표시
→ 시스템 또는 애플리케이션에서 파일 리소스를 얼마나 많이 사용하고 있는 지를 파악하는데 사용되며,
→ 이때 파일은 텍스트 파일, 로그 파일 등과 같이 애플리케이션이 읽거나 쓰는 데 사용되는 모든 파일을 의미.
이 값이 높게 나타날 경우
- 파일을 지속적으로 열고 닫는 작업이 많이 발생하거나
- 파일을 닫지 않아 핸들링이 계속 유지되는 상황일 수 있음
→ 이는 리소스 누수로 이어져 시스템의 성능 저하나 안정성 문제로 이어짐.
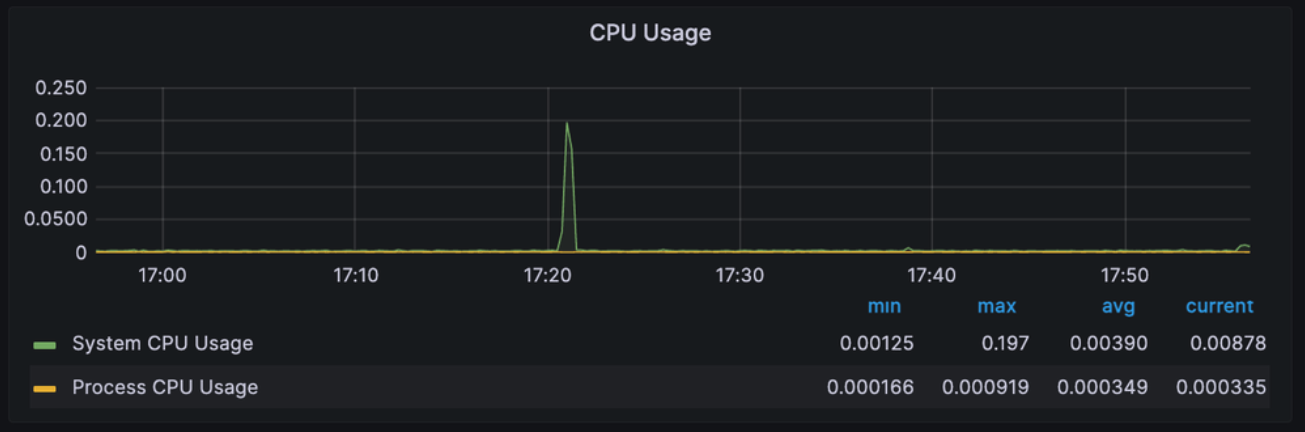
CPU Usages

: 이는 CPU 사용량을 백분율로 표시하며, 시스템의 CPU가 현재 작업을 처리하는 데 사용 중인 비율을 표시
높은 CPU 사용량은 아래와 같은 상황을 초래한다.
- 과부하(Overload) : 시스템에 대한 요청이 많아서 CPU가 작업을 처리하지 못하는 상황이 발생
- 성능 문제 : 애플리케이션이나 프로세스의 비효율성으로 인해 CPU가 지속적으로 과도하게 사용
- 디버깅 필요 : 예상치 못한 고비용 연산, 무한 루프, 불필요한 계산 등으로 인해 CPU의 사용량이 높아질 경우 코드의 문제를 파악하고 수정할 필요가 있음.
Load Average

5분 간격의 시스템 부하 평균을 표시하는 대시보드
: 부하 평균을 나타내는 지표로 보통 1분, 5분, 15분의 세 가지 간격으로 표시
제공하는 정보
- CPU 및 I/O 작업 등 시스템 자원을 얼마나 많이 사용하는 지(= 시스템이 얼마나 바쁜지) 를 표시
- 이 값이 높을 수록 시스템이 더 많은 작업을 처리하고 있거나 부하가 높은 상태임을 의미
💡 JVM Statistics - Heap

번외 : Heap 영역 내 세부 영역들 사전 설명


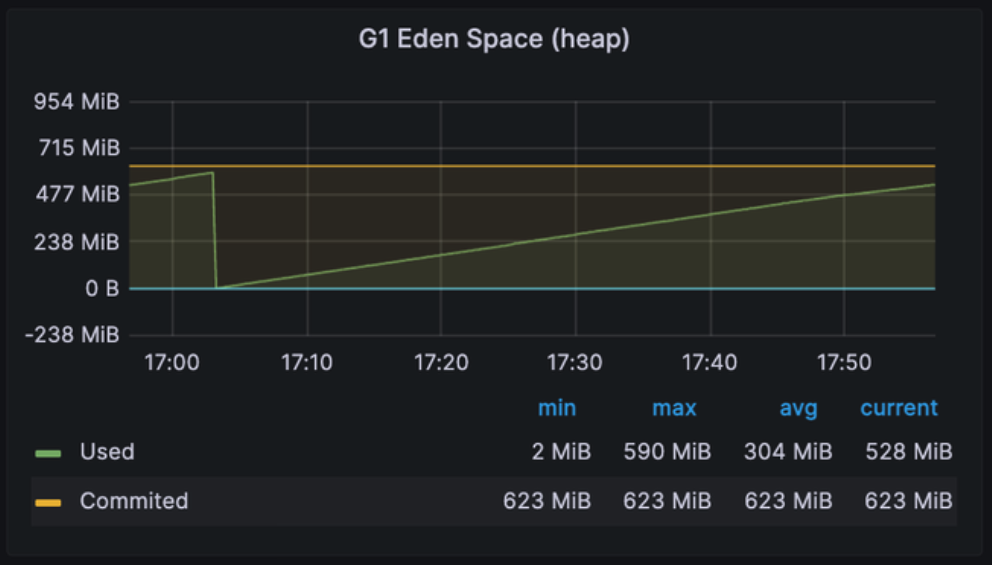
G1 Eden Space (heap)
: Eden 영역이 얼마나 빠르게 가득 차는지, 얼마나 자주 가비지 컬렉션이 발생하는지를 표시
→ 메모리 사용 패턴을 분석하고 애플리케이션의 성능을 평가 가능
Eden 영역이란?
- Heap 메모리 영역 중 Young 영역 내에 있는 영역으로, 새로 생성된 객체들이 할당되는 곳
- Eden 영역의 크기 조정이나 GC 주기를 조절하여 성능 튜닝도 가능
번외 : GC 성능 튜닝에 대한 이야기
JVM의 힙 메모리는 크기에 따라 GC 발생 횟수와 수행 시간에 영향을 끼친다.
⇒ 따라서 옵션을 통해 조절하면 어플리케이션 성능 향상 효과를 가질 수 있음
메모리 크기가 클 경우
- GC 발생 횟수 감소
- GC 수행 시간 증가
메모리 크기가 작을 경우
- GC 발생 횟수 증가
- GC 수행 시간 감소
레거시 API Server 에서 프로젝트 실행시 제공한 VM Option 예시
- 힙 시작 크기와 최대 크기를 2048로 설정
-XX:PermSize&-XX:MaxPermSize: 현재는 사라진 Permanent 영역에 대한 크기 설정 값
java -jar -Dspring.profiles.active=dev
-Xms2048m
-Xmx2048m
-XX:PermSize=256m
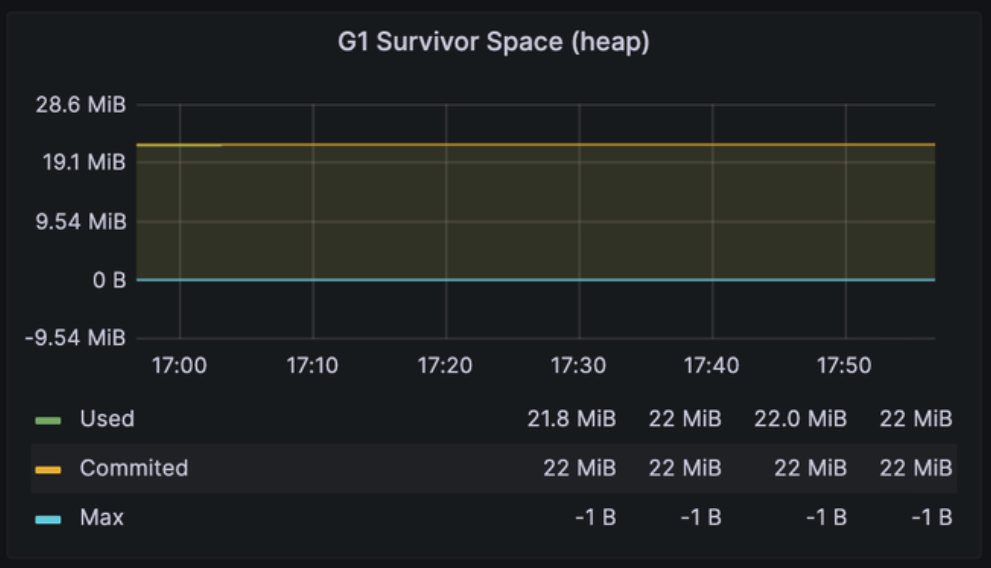
-XX:MaxPermSize=512m "jar 파일명"G1 Survivor Space (heap)

: Survivor 영역에서 얼마나 빠르게 가득 차는지, 얼마나 자주 가비지 컬렉션이 발생하는지를 표시
Survivor 영역이란?
- Eden 영역과 마찬가지로 Young Generation 영역 내에 있는 영역으로, 2개가 존재
- Eden 영역에서 가비지 컬렉션을 거쳐 살아남은 객체들이 이동
- 이후에도 계속해서 가비지 컬렉션이 발생하면서 살아남은 객체들은 다른 Survivor 영역으로 이동
주의 깊게 봐야 할 점
- Survivor 영역의 공간의 크기를 적절하게 조정해야 한다.
- Survivor 영역의 크기가 너무 작을 경우
- 빈번한 객체 이동과 가비지 컬렉션으로 인한 성능 저하
- 영역이 가득 찰 경우 새로운 객체들이 이동할 공간이 부족해지는 문제가 발생
G1 Old Gen (heap)
: Old 영역에서 얼마나 빠르게 가득 차는지, 얼마나 자주 가비지 컬렉션이 발생하는지를 표시
Old 영역이란?
Heap 메모리 영역 중 Young 영역에 있는 객체 중 일정 시간 동안 살아남은 객체들이 이동하는 영역
⇒ 장기간에 걸쳐 메모리를 점유하고 있는 객체들이 저장되어 있다.
주의깊게 봐야 할 점
- 일반적으로 오랜 기간 사용되는 객체들이 위치 → 메모리 공간을 효율적으로 사용해야 함.
- 이 영역의 메모리가 가득 차거나 가비지 컬렉션이 자주 발생한다면 성능 저하의 원인이 된다.
CodeHeap 'non-nmethods' (non-heap)

non-nmenthods 영역이란?
Java의 HotSpot JVM에서는 코드를 저장하고 실행하기 위해 메모리를 할당하는 CodeHeap의 영역 중 하나다.
→ Heap 영역이 아닌 non-heap 영역에 속하여 Garbage Collector가 직접 관리하지 않아, JVM 실행 중 메모리 할당 및 해제가 일어나지만 가비지 컬렉션의 대상이 되지는 않는다.
제공되는 정보
- JVM 내부에서의 동작과 관련된 데이터를 저장하는 데 활용되기 때문에
- 이 영역의 크기 및 사용량을 모니터링하면 메모리 사용 패턴을 파악하여 이슈를 식별하는 데 도움이 된다.
CodeHeap 'non-profiled-nmethods' (non-heap)
non-profiled-nmethods 영역이란?
'non-heap' 메모리에 속하며, JIT(Just-In-Time) 컴파일러의 메타데이터와 관련된 정보를 저장하는 곳
→ 주로 프로파일링을 하지 않은 메서드들의 코드를 저장하고, 이때 JIT 컴파일러는 저장된 메서드들을 컴파일하여 기계 코드를 저장한다.
CodeHeap 'profiled nmethods' (non-heap)

profiled-nmethods 영역이란?
'non-heap' 메모리에 속하며, JIT(Just-In-Time) 컴파일러의 메타데이터와 관련된 정보를 저장하는 곳
→ 프로파일링된 메서드들의 코드를 저장하는 것이 non-profiled-nmethods 영역과의 차이점이다.
→ 이외 동작은 동일.
Compressed Class Space (non-heap)
: ‘non-heap’ 메모리 영역 중 하나로, 클래스의 메타데이터를 저장하는 곳
Java 8 이후에는 클래스 메타데이터의 저장 공간을 줄이기 위한 압축 기술이 적용되었고,
→ 이 압축된 클래스 메타데이터를 저장하는 곳이 바로 이 공간이다.
제공되는 정보
- 클래스 로딩 및 메타데이터 관리를 위해 필요한 공간으로 모니터링을 통해 메모리 효율성을 높일 수 있다.
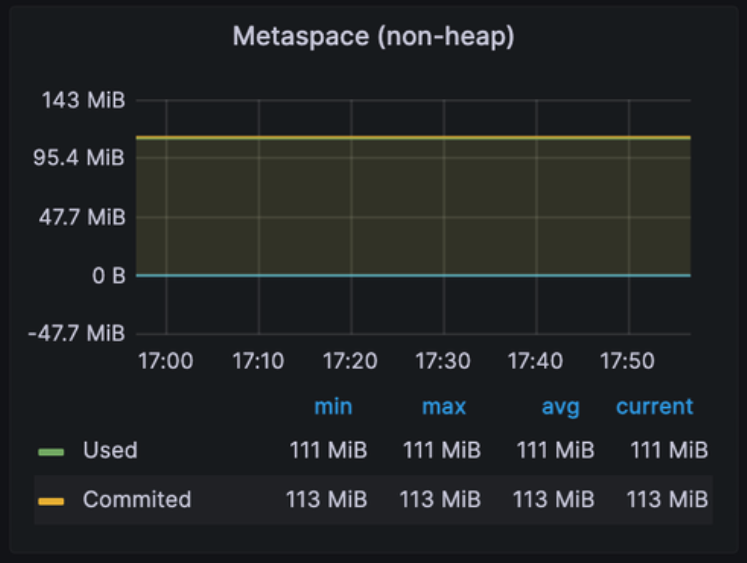
Metaspace (non-heap)

: Java 8 이후로 PermGen(Permanent Generation) 영역 대신에 Metaspace에서 클래스 메타데이터를 저장
Permanent Generation 과의 차이
- 기존의 PermGen
- 고정된 크기를 가지며, 클래스 로딩 및 언로딩에 따라 메모리 부족 문제가 발생할 수 있음.
- Metaspace
- 클래스 구조, 상속 관계, 메서드, 필드 등의 클래스 메타데이터를 저장 & non-heap 영역에 동적 할당
- 기존의 PermGen과 다르게 힙 크기에 제한되지 않고 동적으로 확장 가능
💡 JVM Statistics Threads/Buffers
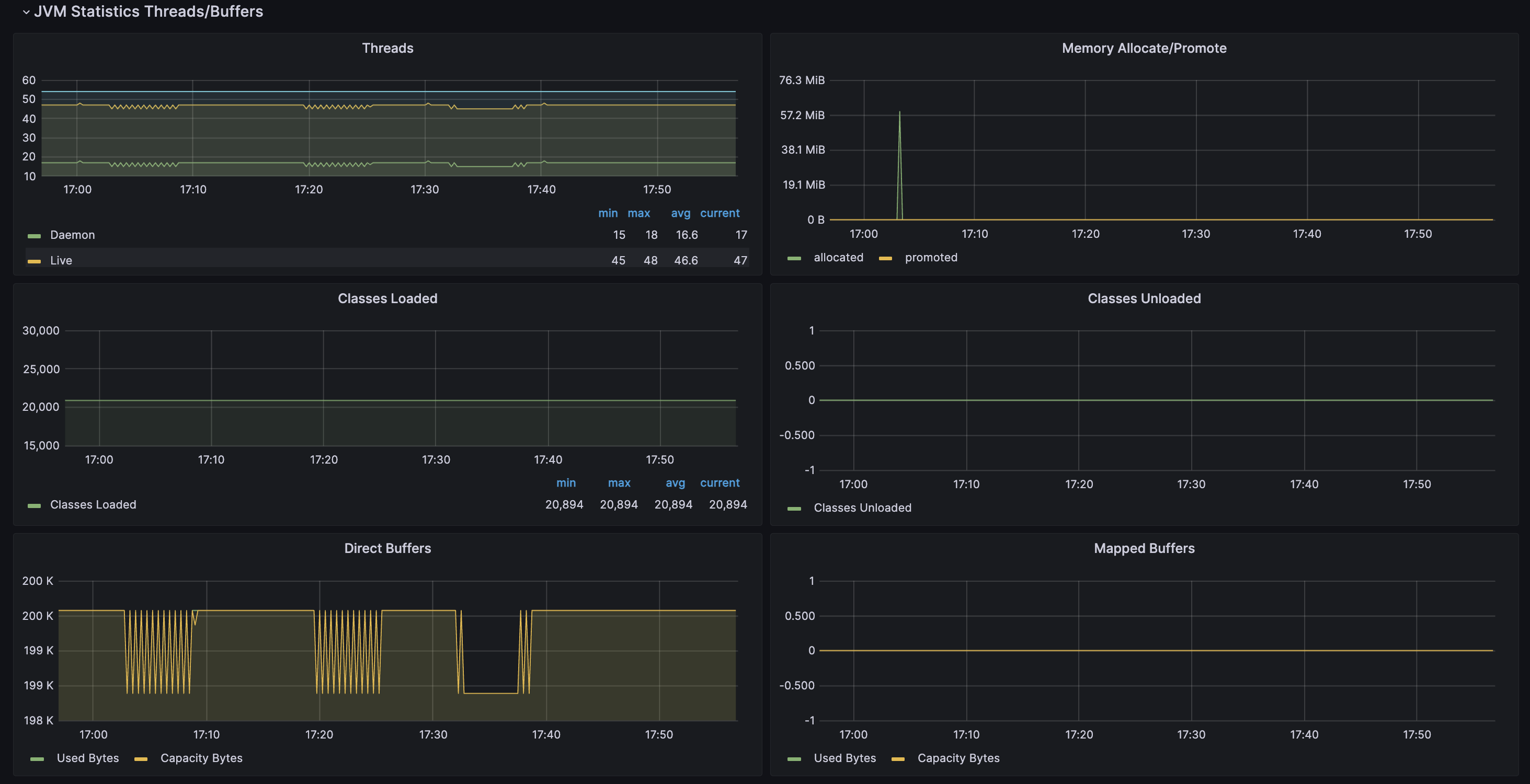
Threads
: JVM 내부적으로 실행되는 스레드와 Java 애플리케이션에서 생성된 모든 스레드에 대한 통계를 표시
제공하는 정보
- 스레드 수 (Thread Count)
- 현재 JVM에서 실행 중인 스레드의 총 수로, JVM이 처리하고 있는 작업의 양을 알 수 있음.
- 데몬 스레드 수 (Daemon Thread Count)
- 데몬 스레드는 백그라운드에서 실행되는 스레드로, 일반적으로 JVM이나 가비지 컬렉터 등과 같은 보조적인 작업을 처리하는 데 사용
- 데드락 감지 (Deadlock Detection)
- 때때로 데드락(Deadlock)을 감지할 수 있는 기능을 제공
- 데드락은 두 개 이상의 스레드가 서로의 작업을 기다리며 무한히 멈춰 있는 상태를 의미
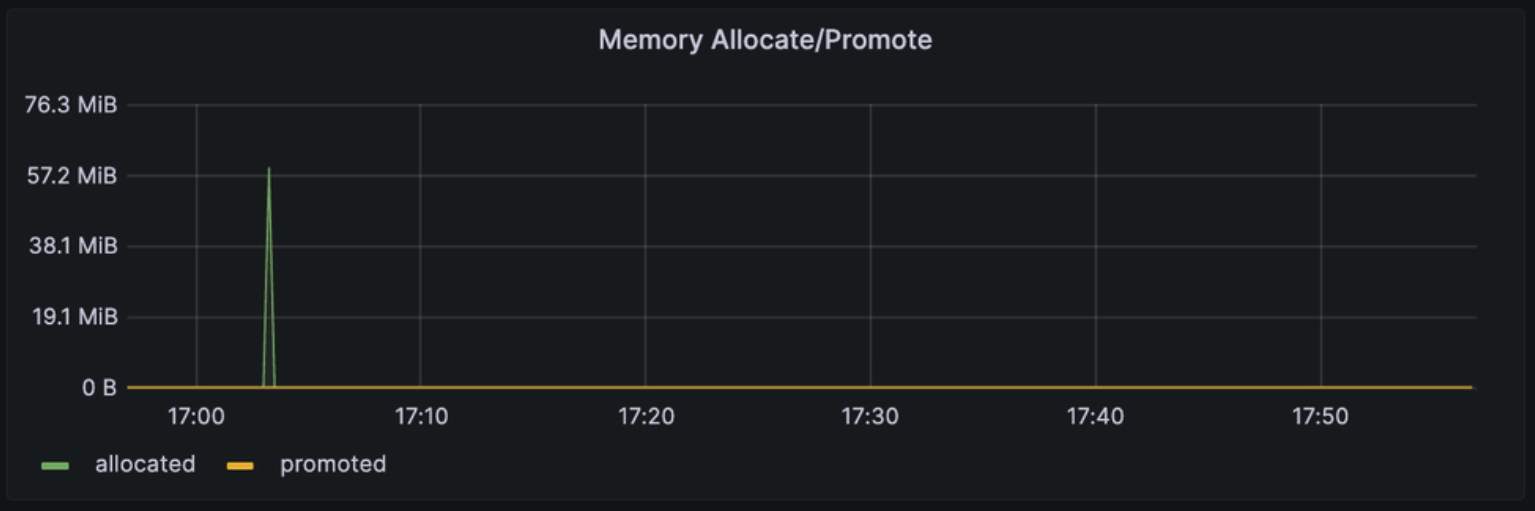
Memory Allocate
: Java 애플리케이션에서 메모리를 할당하는 작업에 대한 통계를 제공
- Allocated : JVM이 현재까지의 총 메모리 할당량을 나타냄
- Promoted : Young Generation에서 Old Generation으로 객체가 이동한 양을 나타냄
추가로 메모리 할당 횟수, 할당된 메모리 량, 메모리 할당 속도를 이용해 메모리 소비량을 파악할 수 있음.
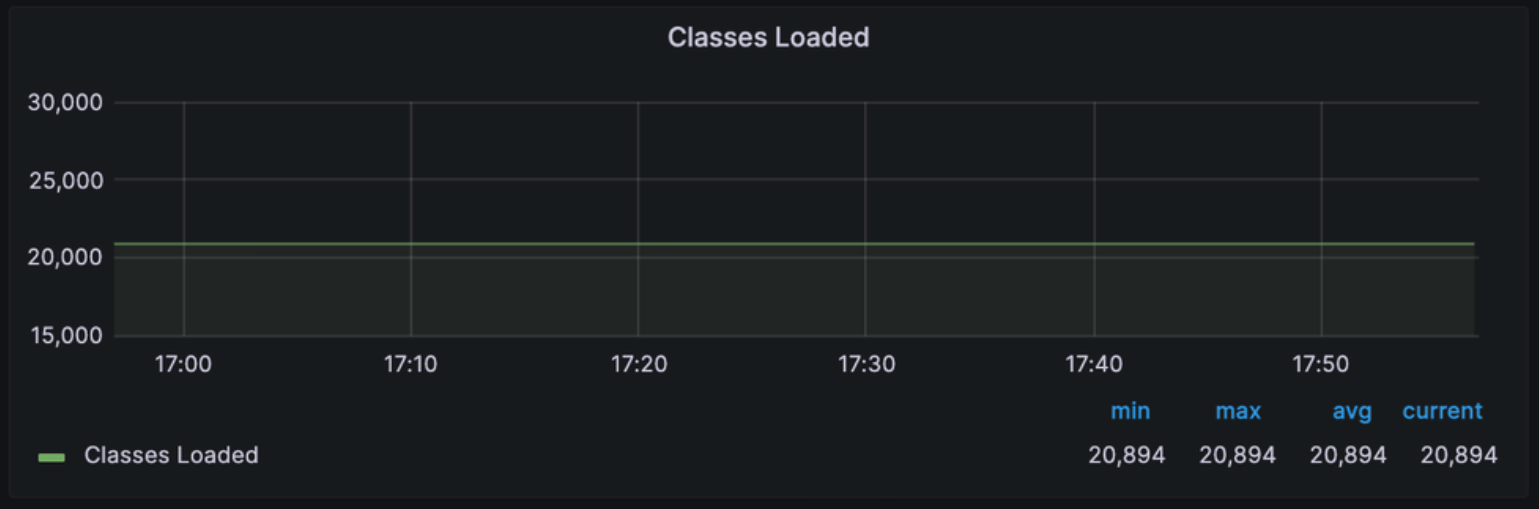
Class Loaded
: JVM이 실행 중에 클래스 로더에 의해 로드되고 초기화된 클래스들의 총 수를 표시
Class Unloaded
: JVM이 실행 중에 더 이상 사용하지않아 메모리에서 제거된 클래스의 총 수를 표시
Direct Buffers

: Direct Buffers는 Java NIO(Non-Blocking I/O)에서 사용되는 직접 버퍼의 정보를 표시
이는 JVM이 직접 관리하는 메모리 영역으로, 일반적인 힙 메모리 대신에 운영체제의 네이티브 메모리를 사용하여 데이터를 저장한다. 이로 인해 입출력 성능이 향상될 수 있다.
제공하는 정보
- Used Bytes (사용된 바이트) : 현재 JVM에서 사용 중인 버퍼의 실제 메모리 사용량
- Capacity Bytes (용량 바이트) : 현재 JVM에서 할당된 직접 버퍼 총 용량
- 직접 버퍼의 전체적인 용량을 나타내며, 버퍼가 최대로 저장할 수 있는 메모리의 양
→ 일반적으로 Used Bytes가 Capacity Bytes보다 작거나 같으며, 큰 차이가 있을 경우 메모리가 낭비되거나 버퍼가 부족함을 알 수 있음.
Mapped Buffers
: 이 대시보드는 JVM에서 사용되는 매핑된 버퍼의 정보를 제공
→ 매핑된 버퍼는 파일 I/O 작업에서 사용되며, 파일의 내용을 메모리에 직접 매핑하여 입출력 작업을 수행할 때 사용
제공하는 정보
- Used Bytes (사용된 바이트) :
- 매핑된 파일의 일부 또는 전체를 메모리에 매핑한 상태에서 실제로 사용중인 메모리 양
- 즉, 파일의 일부 또는 전체를 메모리에 매핑하여 읽거나 쓴 메모리 양임
- Capacity Bytes (용량 바이트) :
- 매핑된 버퍼의 전체적인 용량
- 매핑된 버퍼의 최대 용량 또는 메모리에 매핑할 때 사용 가능한 메모리의 양
💡 JVM Statistics - GC
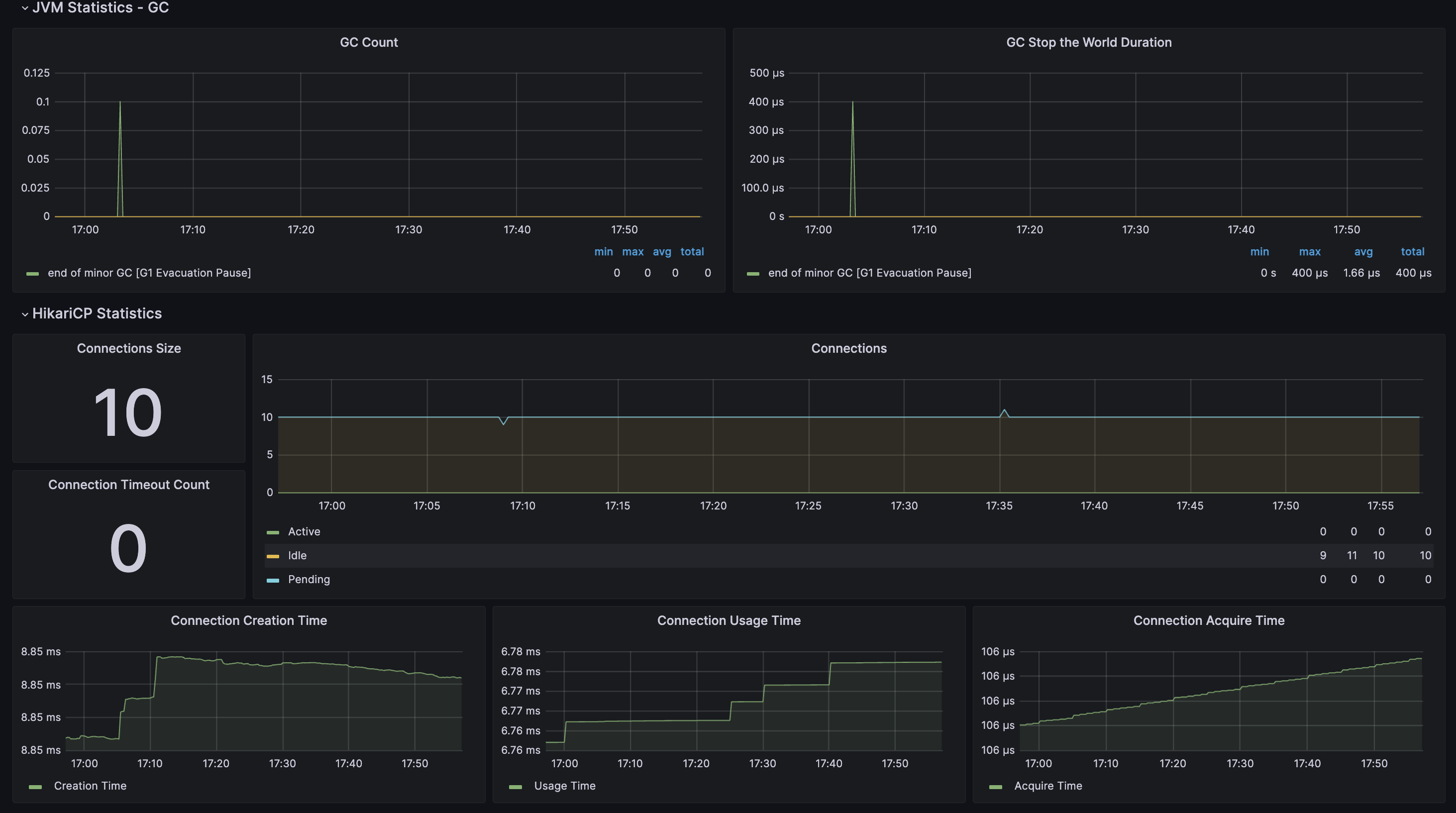
GC Count
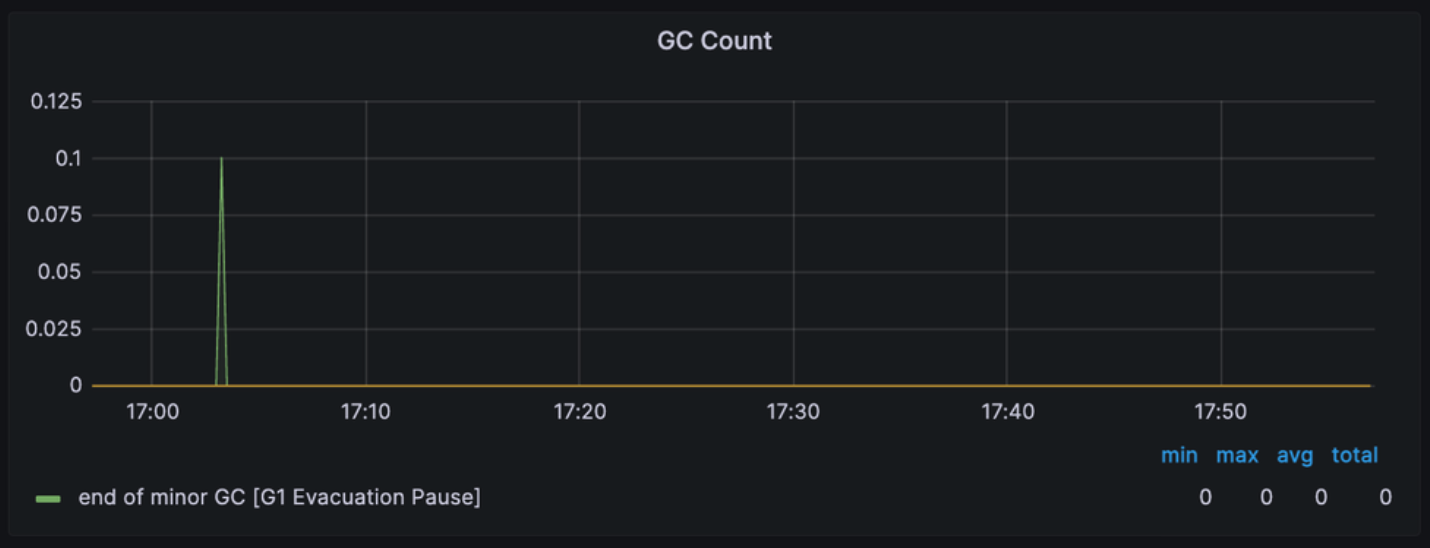
: JVM에서 가비지 컬렉션 실행 횟수와 관련된 정보를 표시
→ GC가 너무 자주 발생하면 애플리케이션 성능에 영향을 미칠 수 있어 빈도와 유형을 확인하는 데에 사용
제공하는 정보
- end of minor GC [G1 Evacuation Pause] :
- G1 가비지 컬렉션 중 마이너 GC가 완료되고 해당 영역의 객체들이 다른 영역으로 옮겨질 때 발생하는 일시적인 정지를 의미
번외 : GC의 Stop-the-world & Mark and Sweep

GC Stop the World Duration
: 가비지 컬렉션 중 발생한 각각의 정지 시간(stop the world)의 지속 시간(duration)을 표시
정지 시간은 일반적으로 짧은 시간이며 대부분의 경우에는 사용자가 느끼지 못할 정도로 짧게 발생하지만,
GC의 빈도나 메모리 부족 등의 이유로 정지 시간이 길어지면 애플리케이션의 성능이 떨어질 수 있어 모니터링이 필요하다.
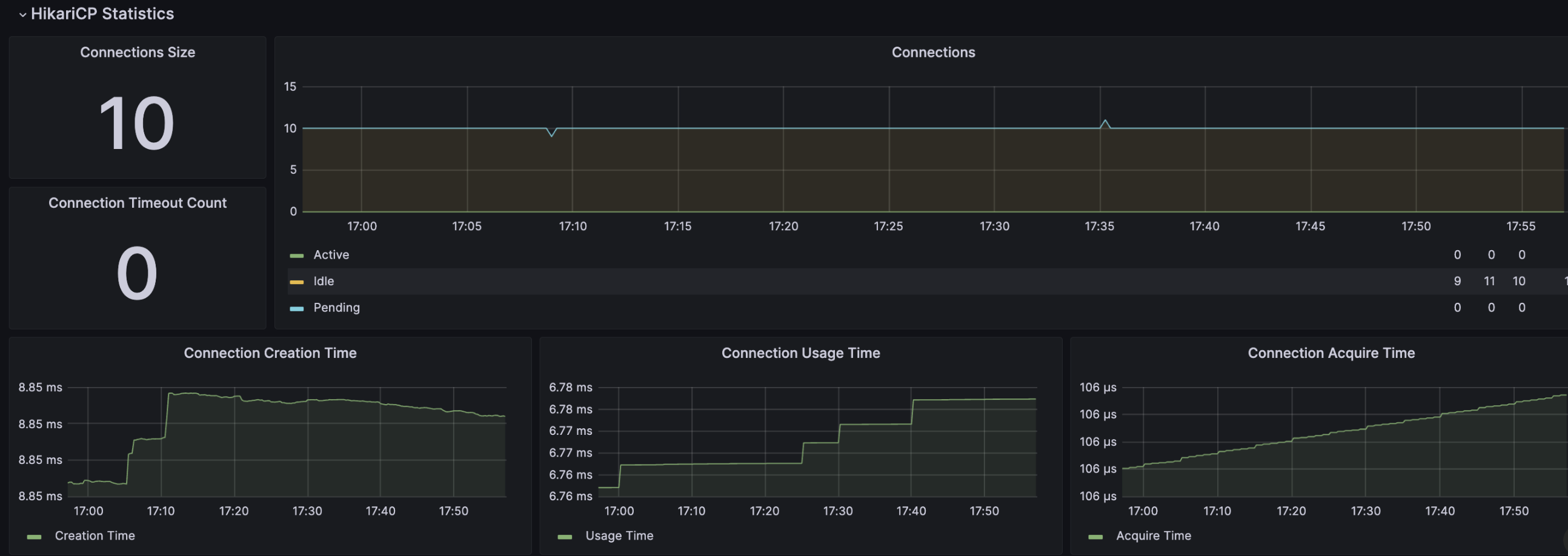
💡 HikariCP Statistics

Connections Size

: HikariCP 커넥션 풀에서의 현재 사용 가능한 커넥션의 개수를 표시
Connection Timeout Count

: HikariCP 커넥션 풀에서 발생한 연결 초과 시간(Timeout) 이벤트의 횟수를 표시
→ Timeout 이벤트의 경우에는 애플리케이션 성능과 안정성에 직접적인 영향을 줄 수 있으므로 대응이 필요
Connections

: HikariCP 커넥션 풀에서 현재 사용 중인 커넥션에 대한 정보를 표시
제공하는 정보
- Active : 현재 데이터베이스에 대한 요청을 처리하고 있는 커넥션 개수
- Idle : 현재 비활성화된 상태의 커넥션 개수
- Pending : 연결 대기 요청 중인 커넥션의 수
- 이 값이 높게 유지될 경우 커넥션 풀의 크기가 현재 애플리케이션의 요구를 충족시키지 못하고 있는 것을 나타낸다.
- 이러한 경우 커넥션 풀의 최대 크기를 증가시키거나, 커넥션을 더 효율적으로 관리하여 대기 중인 연결 요청을 최소화해야 한다.
Connection Creation Time

: HikariCP 커넥션 풀에서 커넥션을 생성하는 데 걸리는 시간에 대한 정보를 표시
→ 주로 새로운 커넥션을 생성하는 데 필요한 시간을 모니터링함으로써 데이터베이스 연결의 효율성을 평가
Connection Usage Time
: HikariCP 커넥션 풀에서 각 커넥션이 사용된 시간을 표시
→ 이는 커넥션을 획득(acquire)하여 반환(release)하는 시간 간격을 측정한 것으로,
→ 해당 커넥션이 실제로 데이터베이스 작업을 처리하는 동안의 시간을 반영한다.
Connection Usage Time이 높게 측정될 경우
- 커넥션 사용이 오래 걸리므로 작업이 느려지거나 다른 요청을 지연시킬 수 있다.
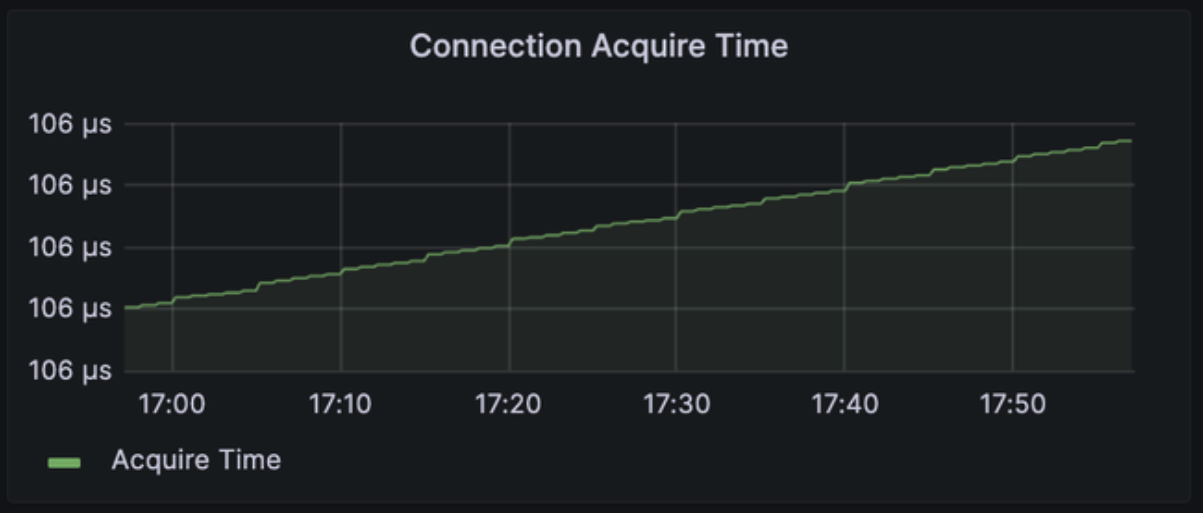
Connection Acquire Time

: HikariCP 커넥션 풀에서 커넥션을 획득하는 데 걸리는(= 대기하는) 시간을 표시
Connection Acquire Time이 높게 측정될 경우
- 새로운 연결을 얻는 데 시간이 오래 걸리는 것
- 서버의 응답 지연이나 네트워크 지연 등의 문제와 관련될 수 있어 모니터링이 필요
💡 Jetty Statistics
현재 사내 프로젝트에서 내장 WAS를 Jetty가 아닌 Undertow로 사용중이기에, 아래 그림에서는 값이 없음.

Thread Config Min

: WAS에서 항상 유지하려는 최소한의 스레드 수를 의미. (= 서버가 동시에 처리할 수 있는 최소한의 요청 수)
서버의 트래픽이나 요청량이 증가할 때 최소 스레드 수를 충분히 설정하여 과부하를 방지할 수 있도록 해야 한다.
Thread Config Max

: WAS에서 구성된 스레드 풀의 최대 스레드 수를 의미.
설정된 최대 스레드 수보다 많은 요청이 발생하는 경우, 요청을 대기시키거나 거부할 수 있다.
Thread Config Max 값 설정 시 고려 사항
- 서버가 허용할 수 있는 동시 요청 수와 서버 자원의 한계를 고려해야 한다.
- 너무 낮은 값을 설정할 경우 : 서버가 많은 요청을 처리하지 못함
- 너무 높은 값을 설정할 경우 : 서버의 자원을 과도하게 사용하여 성능 저하나 서버 부하를 초래
HTTP Codes
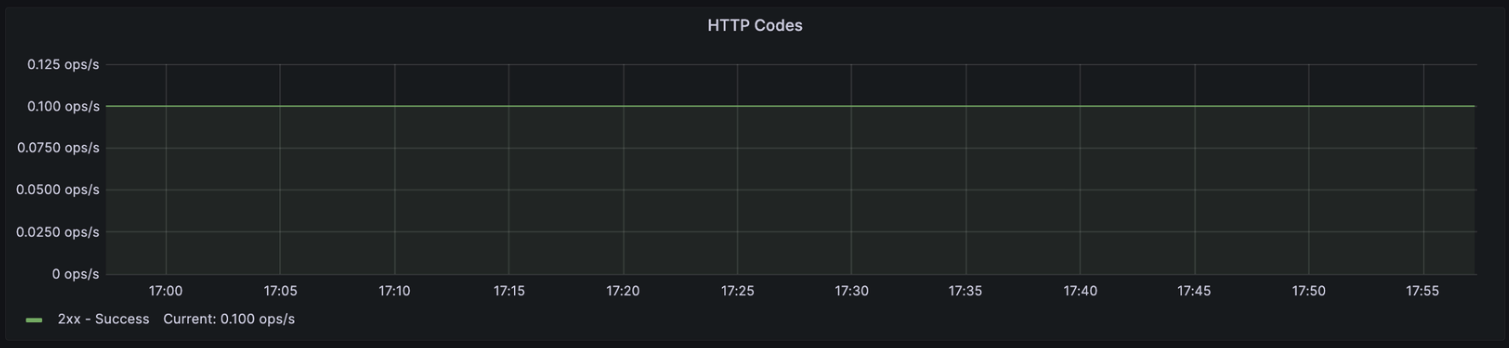
: WAS에서 처리된 HTTP 요청의 상태 코드별 발생 횟수를 보여줌.
HTTP Status Code
- 1xx (Informational): 정보 응답을 나타내며, 주로 요청이 수신되고 처리 중
- 2xx (Success): 성공적으로 처리된 요청을 나타내며, 주로 요청이 성공적으로 처리되었음
- 3xx (Redirection): 추가 조치가 필요한 경우를 나타내며, 주로 리다이렉션과 관련된 요청을 나타냄.
- 4xx (Client Error): 클라이언트 오류를 나타내며, 주로 잘못된 요청이나 권한이 없는 요청 등 클라이언트 측 오류를 나타냄.
- 5xx (Server Error): 서버 오류를 나타내며, 주로 서버 측에서 요청을 처리하는 동안 오류가 발생했음
Requests/second
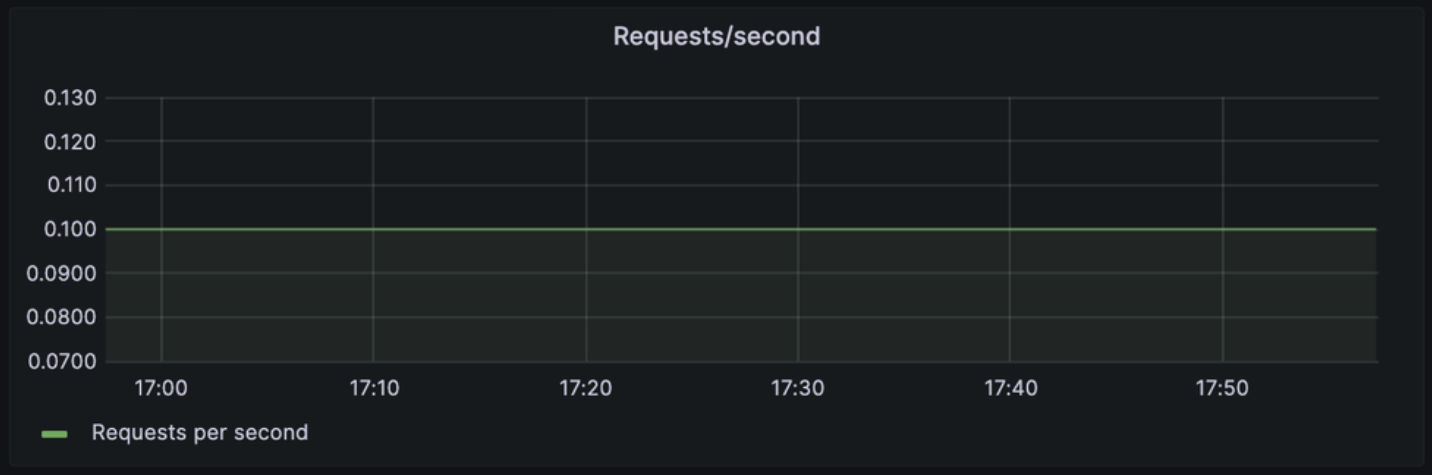
: WAS의 초당 요청 처리량을 보여주는 지표로, 서버의 부하 및 성능을 파악하는 데 사용
제공되는 정보
- 요청/초가 높을 수록 서버가 많은 요청을 처리함을 의미하지만, 이는 과부하로 이어질 수 있다.
- 이를 통해 서버의 트래픽 패턴을 이해하여 필요에 따라 서버 자원을 조정하거나 최적화하는 데에 사용
Requests duration
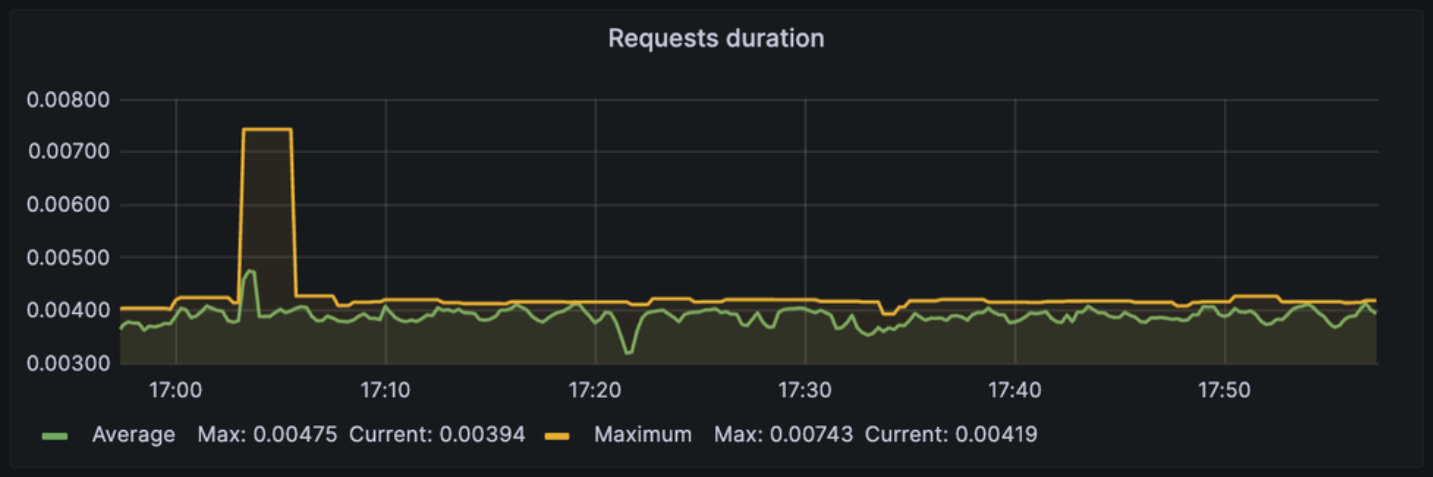
: WAS에서 처리된 각 요청의 지속 시간을 의미.
= 요청이 서버로부터 받아들여진 시간부터 요청이 완료되고, 응답이 클라이언트로 보내진 시간까지의 경과.
제공되는 정보
- 각 요청의 처리 속도 및 성능을 나타내는 지표로, 특정 요청이 처리되는데 오래 걸리는지 등을 확인 가능
- 처리 시간이 오래 걸릴 경우
- 코드 최적화, 데이터베이스 쿼리 성능 향상, 더 효율적인 캐싱 등의 도입으로 서버의 성능을 개선이 필요
- 특정 시간대에 처리 시간이 급격하게 증가하는 패턴을 발견 시
- 해당 시간대에 서버 부하를 분산시키거나 최적화를 진행할 수도 있다.
TOP 10

: WAS에서 발생한 상위 10개의 특정 이벤트를 보여주는 대시보드로, 각각의 중요성과 성능을 파악할 수 있다.
제공되는 정보
- TOP 10 Requests: 가장 많은 트래픽을 발생시킨 상위 10개의 HTTP 요청 또는 URI.
- TOP 10 Response Time: 가장 오랜 시간이 소요된 상위 10개의 요청 또는 작업.
- TOP 10 Clients: 가장 많은 요청을 보낸 상위 10개의 클라이언트 IP 주소 또는 호스트.
- TOP 10 Errors: 가장 많이 발생한 상위 10개의 오류 코드 또는 오류 유형.
Threads

: WAS에서 사용되는 스레드 관련 정보를 표시
제공되는 정보
- Thread Count (스레드 개수) :
- 현재 Jetty 서버에서 활성화된 스레드의 총 개수를 나타냄
- Idle Threads (유휴 스레드) :
- 현재 유휴 상태에 있는(사용되지 않고 대기 중인) 스레드의 개수를 나타냄
- Active Threads (활성 스레드) :
- 현재 활성화되어 작업을 수행 중인 스레드의 개수를 나타냄
💡 Logback Statistics
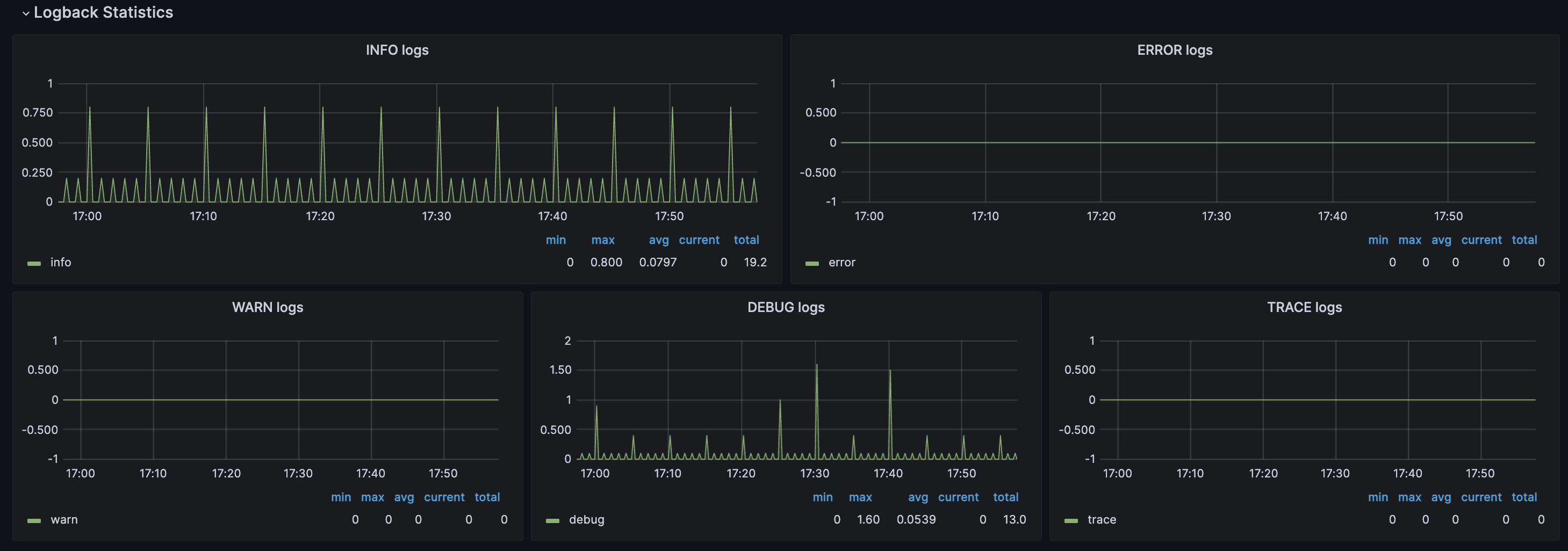
: 각 로그 레벨별로 발생 횟수를 표시
로그 레벨
- TRACE : 디버깅을 위한 매우 상세한 정보를 포함, 주로 성능 측정이나 디버깅에 활용
- DEBUG : 디버깅에 유용한 정보를 제공하는 레벨, 주로 개발 중에 활용
- INFO : 애플리케이션의 상태나 중요한 이벤트에 대한 정보를 기록
- WARN : 잠재적인 문제를 나타내는 경고 메시지에 사용
- ERROR : 오류나 예외 상황을 나타내는 레벨
참고자료
