
오늘은 그래프에 대해 개념을 짚고 방향 그래프의 알고리즘인 위상 정렬에 대해서도 알아봅시다.
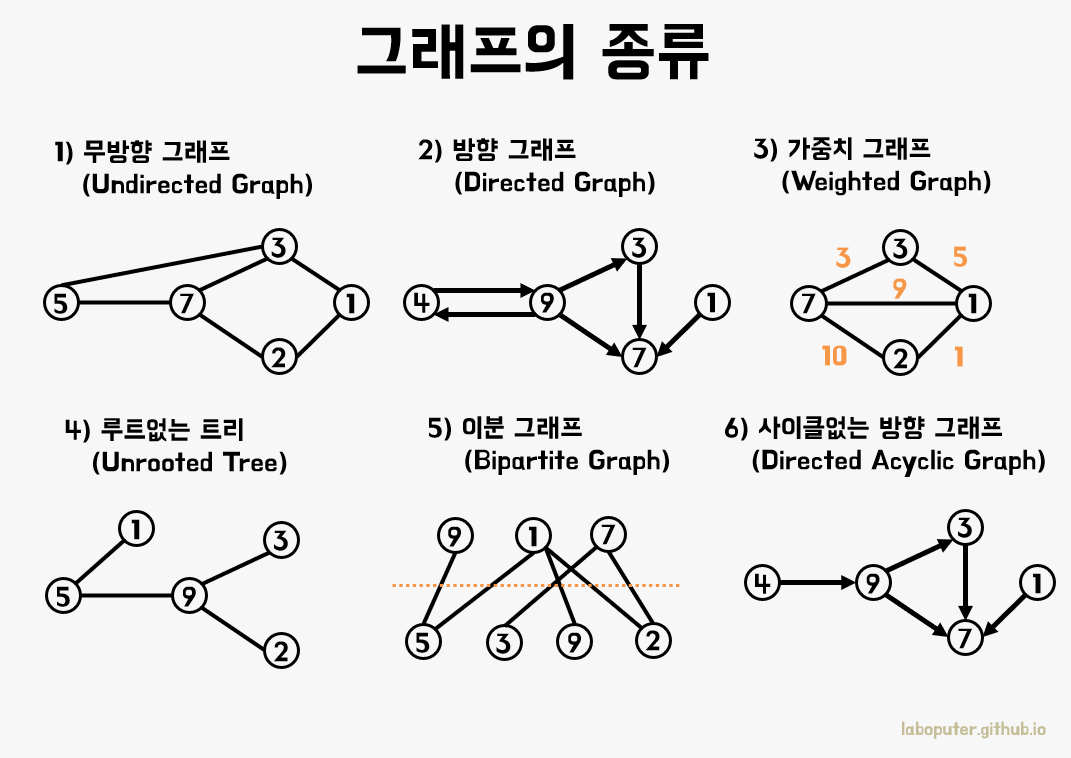
그래프
그래프는 단순히 노드(Node)와 간선(Edge)로 이루어진 자료구조입니다. 그래프 자료구조는 객체 간의 서로 연결되어있는 구조를 의미합니다. 예를 들면, 여러 개의 도시로 연결되어 있는 경우, 선수 과목, 지도 등의 문제에서 많이 출제됩니다.
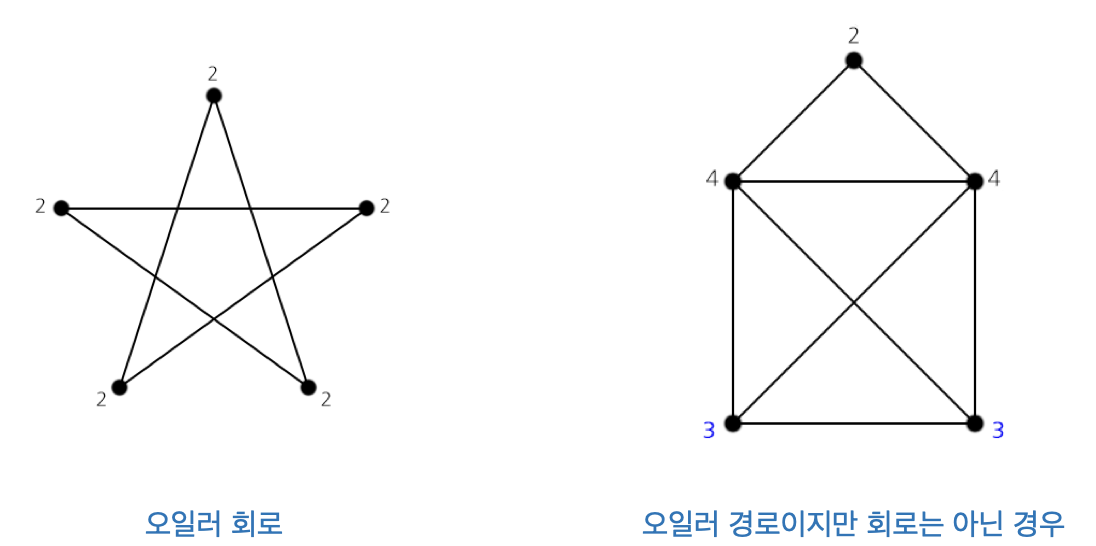
💡 오일러 경로와 오일러 회로(Eulerian Tour)
오일러 경로는 그래프에 존재하는 모든 간선을 한번씩 통과하는 경로를 의미합니다. 이때, 출발점과 도착점이 같으면 회로라고 합니다. 아래 그림을 보면 그래프의 모든 정점에 연결된 간선의 개수가 짝수 일때만 오일러 회로가 존재합니다.(모든 노드가 짝수 차수를 가질때)
- 모든 정점의 차수가 짝수 인가?
- 방문한 모든 노드가 연결되어 있는가?
그래프를 구현하는 방법
그래프를 구현하는 방법에는 두가지가 있습니다.
인접 리스트(Adjacency List)
인접 리스트는 모든 정점을 인덱스로 지정하여 인덱스(노드)에 연결된 인접 노드들을 리스트로 표현한 것입니다. 보통 배열이나 연결리스트를 통해 인접리스트를 표현합니다.
adj_list = {}
adj_list[node] = []
adj_lost[node1].append(node2)
# 무방향일 때,
# adj_lost[node2].append(node1)- 각 정점의 리스트에 쉽게 접근할 수 있습니다.(인접 노드를 찾을 때)
- 무방향 그래프는 간선이 두번 저장됩니다.
- 간선이 적은 희소 그래프에 용이
인접 행렬 (Adjacency Matrix)
인접 행렬은 형식으로 이루어져 있습니다. 노드의 개수가 N인 그래프를 행렬로 표현해야하다보니 의 메모리 공간이 필요합니다.
adj_matrix = [[0 for _ in range(num_nodes)] for _ in range(num_nodes)] # 2차원 행렬
# 노드 간 간선이 존재하는 경우
adj_matrix[node1][node2] = 1
adj_matrix[node2][node1] = 1- 인접행렬은 탐색하는 알고리즘에는 모든 노드를 순회해야 하다보니 효율성이 떨어집니다.
- 두 정점의 간선 여부를 확인할 때는 빠르게 알 수 있습니다.
- 간선이 많은 밀집 그래프에 용이
그래프 알고리즘
그래프 알고리즘의 종류로는 많습니다. 아래 정리한 알고리즘은 자주 사용하는 알고리즘으로 이번 포스팅에서 다룰 알고리즘은 방향 그래프 알고리즘입니다.
노드 순회 알고리즘
- 깊이 우선 탐색
- 너비 우선 탐색
최단 경로 탐색 알고리즘
- 다익스트라 알고리즘
- 플로이드 워셜 알고리즘 (모든 정점의 최단 경로를 구하고자 할때)
- 벨만 포드 알고리즘 (음의 가중치를 포함하는 경우)
- A 알고리즘(휴리스틱 탐색)
최소 비용 알고리즘
- 크루스칼 알고리즘
- 프림 알고리즘
방향 그래프 알고리즘
- 위상정렬 알고리즘
- 강한 연결 요소(SCC)
방향 그래프 알고리즘
위상 정렬 알고리즘
위상 정렬 알고리즘(Topology Sort)는 정렬 알고리즘의 일정으로 순서가 있는 그래프가 차례대로 수행할 수 있게하기 위해 사용하는 알고리즘입니다.
여기서 중요한 점은 위상 정렬은 방향 그래프이기 때문에 모든 노드가 순서대로 나열되어야 하며, 사이클이 발생할 수 없는 DAG에만 적용이 가능합니다.

위 그림 처럼, 딥러닝 과목을 듣기위해 데이터 사이언스 과목을 들어야 하고 머신러닝 과목을 들어야 한다고 합니다. 이렇게 선후 관계를 지키면서 순서대로 정렬하는 알고리즘을 위상 정렬이라고 합니다. 여기서 진입차수라는 개념이 나오는데 진입차수(indegree) 는 특정 노드에 들어오는 간선의 개수를 말합니다. 그렇다면 딥러닝 과목의 진입 차수는 2개인거죠.
💡 DAG(Directed Acyclic Graph)
사이클이 없는 단방향 그래프(비순환 그래프)라고 합니다. 데이터 오케스트레이션 airflow 라는 프레임 워크에서 Task들의 의존성을 가지고 수행하려 할때, 작성하는 방법에 사용되기도 합니다.
with DAG( dag_id = "airflow_id", start_date= days_ago(1) ) as dag: t1 = () t2 = () t1 >> t2
- 위상 정렬의 시간 복잡도 : 으로 굉장히 빠른 알고리즘입니다. 노드를 하나씩 확인하면서 간선도 하나씩 제거를 하니 위와 같은 시간 복잡도가 발생합니다.
위상 정렬 구현하기
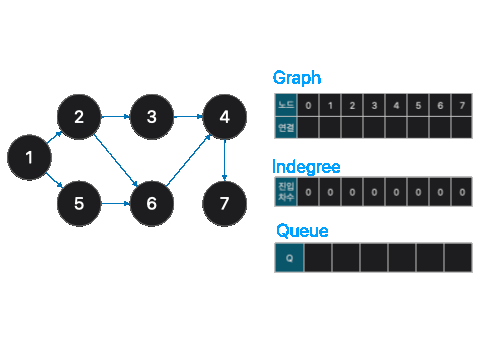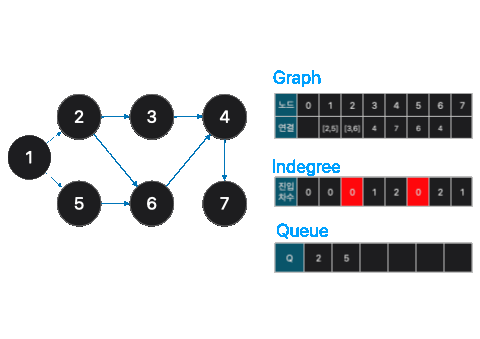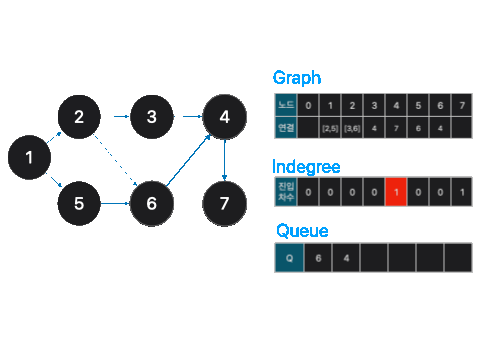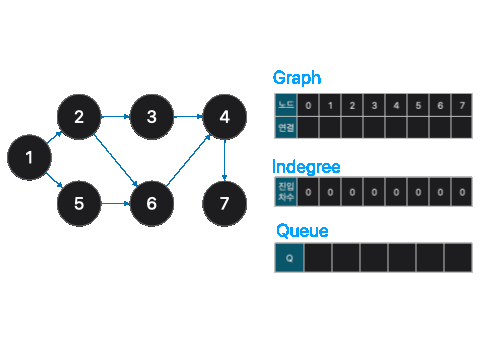
위와 같은 비순환 그래프가 존재했을 때, 어떻게 하면 노드를 순서대로 정렬할 수 있을까요?
인접 리스트 구현하기
먼저 탐색에 유용한 인접 리스트를 통해 그래프를 구현해봅시다.
그래프에 정점에 연결된 간선에 정보를 입력 받을 때, 간선 마다 진입 차수를 증가시킵니다.
# v : 정점의 개수, e : 간선의 개수
# 각 노드에 대한 간선 정보를 담습니다.
graph = [[] for _ in range(v+1)]
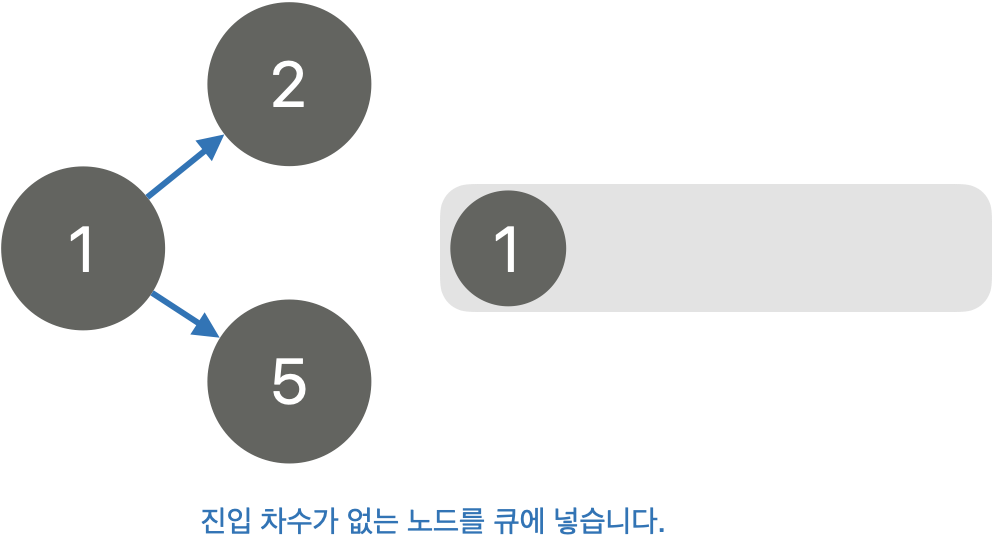
# 모든 노드의 진입 차수가 0인 노드를 큐에 넣습니다.
indegree = [0] * (v+1)
# Graph에서 간선 정보를 입력 받습니다.
for _ in range(e):
a, b = map(int, input().split())
graph[a].append(b) # A -> B
indegree[b] += 1 # 진입차수 1을 증가위상 정렬 구현
def topology_sort():
result = []
# 채울 예정
for i in result:
print(i, end=' ')이번엔, 진입차수(indegree)가 0인 노드를 큐에 넣습니다. 초기에는 1번 노드가 큐에 들어가는 초기 노드가 됩니다. 큐를 사용해도 되고 스택을 사용해도 상관없습니다.
from collections import deque
def topology_sort():
result = []
q = deque()
for i in range(1, v+1):
if indegree[i] == 0:
q.append(i)
# 채울 예정
for i in result:
print(i, end=' ')
그 다음은, 큐(q)에서 노드를 꺼내 해당 노드의 인접 노드에 해당하는 진입차수를 하나씩 제거 합니다. 그리고 만약 인접노드의 진입차수가 0이 된다면 다시 큐에 넣습니다.
이런식으로 큐를 반복합니다.
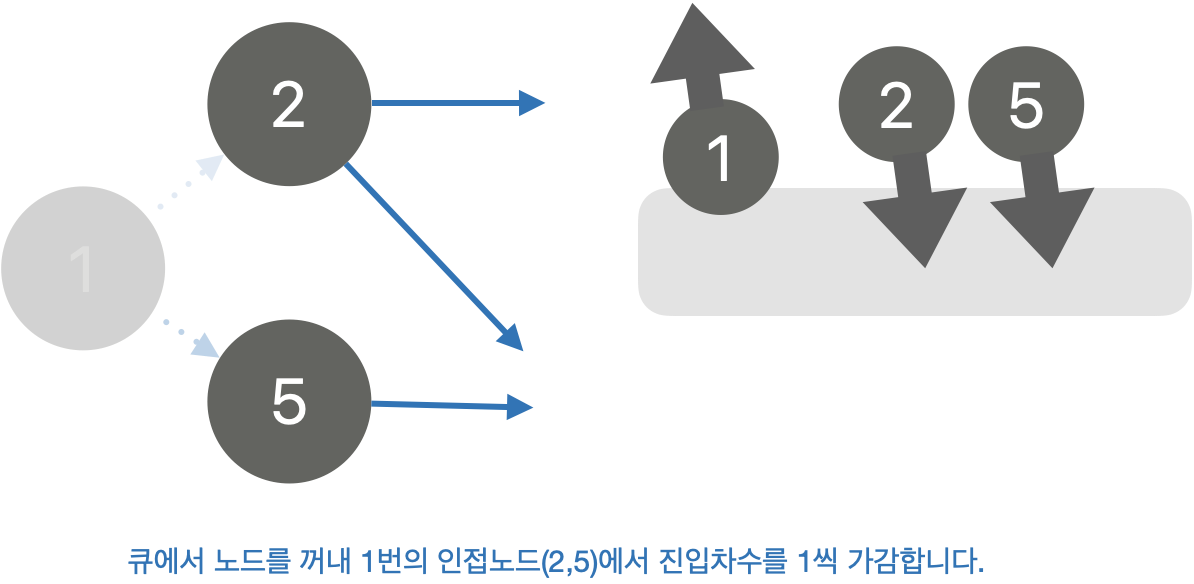
def topology_sort():
result = [] # 결과를 담을 리스트
q = deque()
for i in range(1, v+1):
if indegree[i] == 0: # 진입 차수가 0일 경우
q.append(i) # 큐에 해당 노드를 넣습니다.
while q:
# 큐가 빌때까지 반복
now = q.popleft()
result.append(now) # 결과 리스트에 담기
for i in graph[now]:
indegree[i] -= 1
if indegree[i] == 0: # 진입 차수가 0일 경우
q.append(i) # 큐에 해당 노드를 넣습니다.
for i in result:
print(i, end=' ')이런식으로 반복하다보면, 1,2,5,3,6,4,7 순으로 정렬됩니다.
