오늘은 트리구조에 대해 알아보고 이에 관련하여 수열의 구간합을 빠르게 구할 수 있는 펜윅 트리(Fenwick Tree, Binary Indexed Tree, BIT)에 대해서도 알아보도록 하겠습니다.
트리(tree)
기본적으로 트리 구조는 사이클이 존재하지 않은 그래프라고 생각하시면 됩니다.
주로 탐색을 할때 많이 사용되는 자료구조인데요. 이 자료구조는 한번의 실행으로 명령이 분리 되기 때문에 의 시간 복잡도를 가지고 있습니다. 이렇게 때문에 탐색하는데 적합한 자료구조입니다.
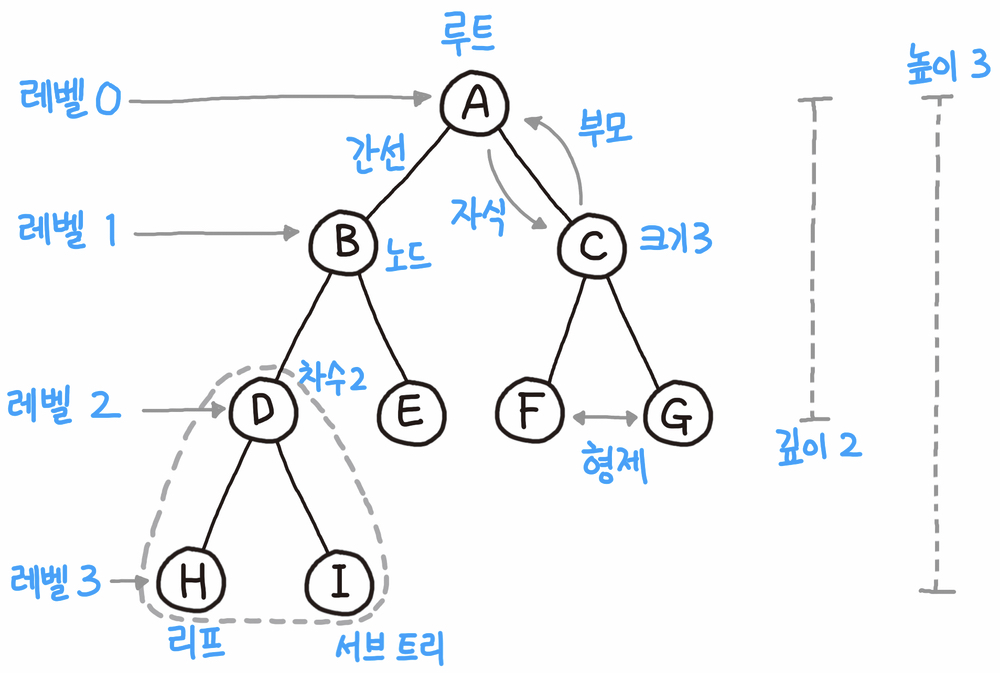
- 노드가 N개인 트리는 항상 N-1개의 엣지를 갖습니다.
- 트리는 DAG(Directed Acyclic Graphs)의 한 종류입니다. (즉, 사이클이 없다는 얘기)
- 루트 노드에서 어떠한 노드로 가는 경로는 유일합니다.
💡 그래프와 트리의 차이점
그래프 트리 정의 노드와 노드를 연결하는 간선으로 표현되는 자료 구조 그래프의 한 종류, 방향성이 있는 비순환 그래프 방향성 방향 그래프, 무방향 그래프 둘다 존재함 방향 그래프만 존재함 사이클 사이클 가능함, 순환 및 비순환 그래프 모두 존재함 비순환 그래프로 사이클이 존재하지 않음 루트 노드 루트 노드 존재하지 않음 루트 노드 존재함 부모/자식 관계 부모 자식 개념이 존재하지 않음 부모 자식 관계가 존재함
트리 순회
그렇다면, 트리 구조는 어떻게 순회하는 것일까요?
트리구조는 전위 순회, 중위 순회, 후위 순회 방식으로 출발 순서에 따라 달라지게 됩니다.
- 전위 순회(Pre-order, 깊이 우선 순위) :
Root→ 왼쪽 자식 → 오른쪽 자식 - 중위 순회(in-order, 대칭 순회) :왼쪽 자식 →
Root→ 오른쪽 자식 - 후위 순회(Post-order) : 왼쪽 자식 → 오른쪽 자식 →
Root
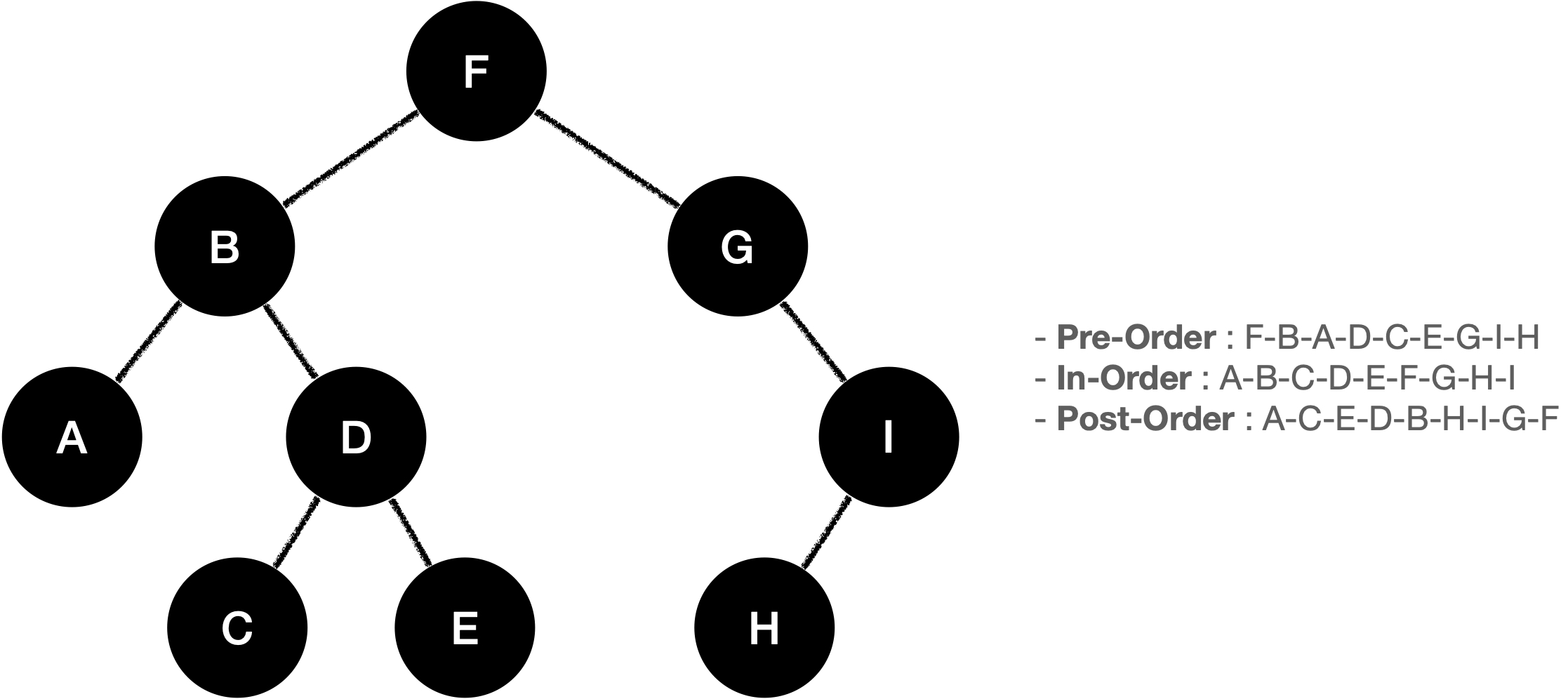
트리 순회는 재귀 함수를 이용해서 쉽게 구현할 수 있습니다.
# 전위 순회
def preorder(node):
if node is None:
return
print(node.value)
preorder(node.left)
preorder(node.right)
# 중위 순회
def inorder(node):
if node is None:
return
preorder(node.left)
print(node.value)
preorder(node.right)
# 후위 순회
def postorder(node):
if node is None:
return
preorder(node.left)
preorder(node.right)
print(node.value)이진 탐색 트리(BST)
이진 탐색 트리는 이진 탐색 + 연결리스트와 같은 장점을 더했다고 생각하시면 됩니다. (이진 탐색 + 연결리스트)
이진 트리
이진 트리는 자식의 노드가 최대 2개까지인 트리를 이진트리(Binary Tree)라고 합니다. 최대 2개까지의 노드를 갖기 때문에 자식 노드가 1개일 수도 있고 없을 수도 있습니다. 그만큼 이진 트리의 종류도 다양합니다.

이진 탐색 트리(BST)
대표적으로 이진 탐색 트리가 있습니다. 기존 이진 트리의 조건에 루트 노드보다 작으면 왼쪽 크면 오른쪽으로 이동해 검색에 용이하게 만들어진 트리를 말합니다. 이진 탐색 트리의 탐색 방법은 중위 순회를 통해 탐색하게 됩니다.
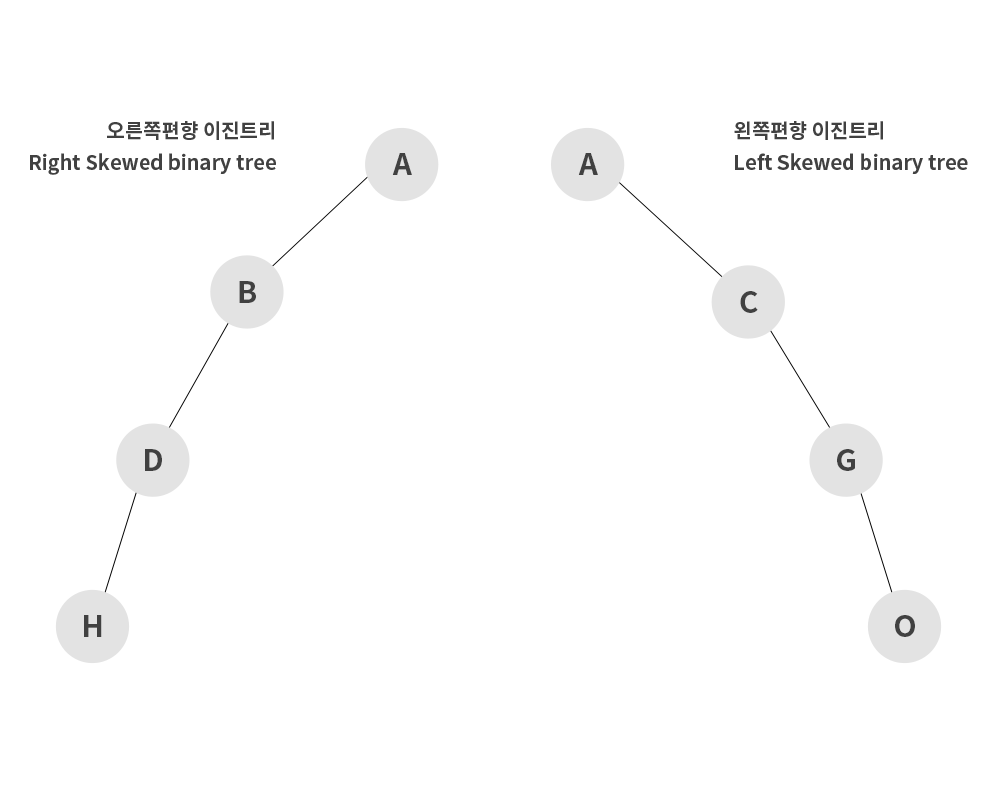
이진 탐색 트리가 탐색에 있어 효율성을 갖고 있습니다. 하지만 장점만 있는 것이 아닙니다.
위 그림처럼 데이터를 삽입했을 때는 선형적으로 탐색을 해야하기 때문에 최악의 시간 복잡도인 이 발생하게 됩니다. 이런 경우에는 AVL 이나 레드블랙 트리와 같은 균형 이진 트리를 사용합니다. 균형이진트리는 데이터가 삽입되거나 삭제될때마다 균형을 맞추기위해 회전하는 트리를 말합니다. 또, 레드블랙 트리는 각 노드에 검정, 빨강의 색상을 나타내는 추가비트를 저장해 균형을 유지하는 트리입니다.
이진 탐색 트리 동작 과정


세그먼트 트리
트리에 대한 기본 개념을 이해하셨다면 세그먼트 트리에 대해 알아보도록 하겠습니다. 세그먼트 트리는 데이터들의 특정 구간 합을 구하는데 사용되는 자료구조입니다. 세그먼트를 사용하는 이유는 속도입니다. 기존 구간합을 구하는 것은 의 시간복잡도이기 때문에 이진 탐색 트리를 이용해 구하면 이며 빠르기 때문입니다. 세그먼트 트리도 이진 탐색 트리에 속합니다.

위 그림을 보시면 인덱스 3부터 7까지의 합을 구한다고 가정했습니다. 세그먼트 트리로 구간합을 구하면 범위안에 있는 경우에서만 값을 구하면 됩니다.
- 세그먼트 트리의 루트는 인덱스 0부터 11까지 값들의 합을 의미합니다.
- 자식 노드부터 분할하면서 진행합니다.
- 위 세그먼트 트리의 노드 갯수는 32개입니다.
- 이유는 미리 배열의 크기를 만들어야 하기 때문입니다. 위 케이스에서도 12개의 데이터를 세그먼트 트리로 구현하기 위해 N(12)개보다 크고 가장 가까운 N의 제곱수를 구하고 2배를 해주어야 만들 수 있습니다. (16 * 2 = 32)
- 인덱스가 1부터 시작하는 이유는 재귀함수의 편의성 때문입니다.
arr = [5, 8, 7, 3, 2, 5, 1, 8, 9, 8, 7, 3]
tree = [0] * len(arr) * 4) # 여유 있게..
index = 1
def segement(start, end, index):
# start : 배열의 시작 인덱스(0), end : 배열의 마지막 인덱스(11)
if start == end:
# 종료조건 : 인덱스가 마지막인 경우
tree[index] = arr[start]
return tree[index]
mid = (start + end) // 2
tree[index] = segement(start, mid, index * 2) + segement(mid+1, end, index * 2+1)
return tree[index]
segement(0, len(arr)-1, 1)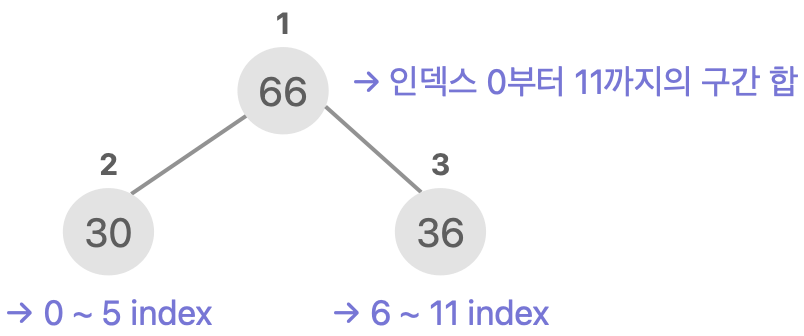
# start : 배열의 시작 인덱스(0), end : 배열의 마지막 인덱스(11)
# left ~ right : 구간합의 범위 인덱스
def interval_sum(start, end, index, left, right):
# 범위에 벗어나는 경우
if left > end or right < start:
return 0
# 범위 안에 있는 경우
if left <= start and right >= end:
return tree[index]
# 그렇지 않다면 두 부분으로 나누어 합을 구하기
mid = (start + end) // 2
return interval_sum(start, mid, index * 2, left, right) + interval_sum(mid + 1, end, index * 2 + 1, left, right)
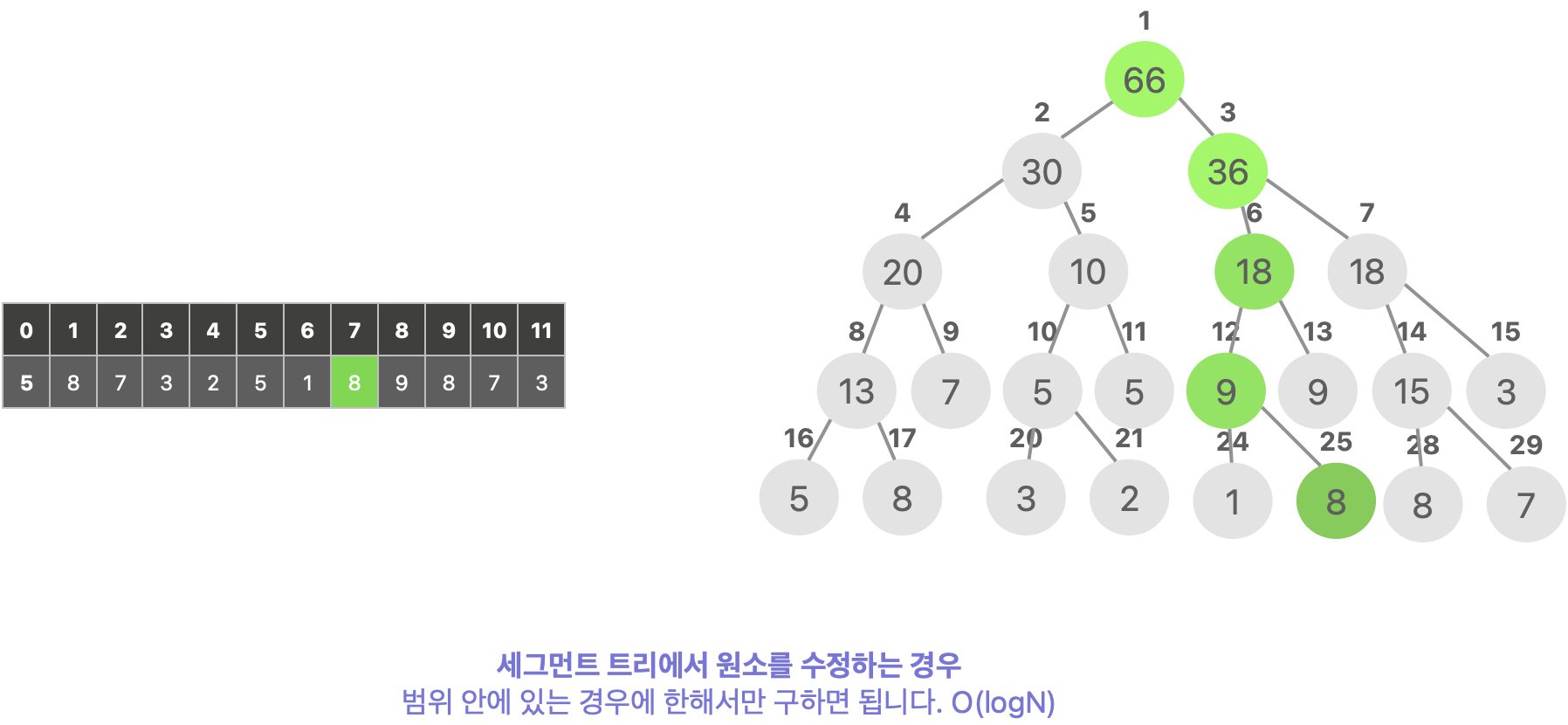
특정 값을 수정하는 경우에는 원소를 포함하고 있는 모든 구간 합 노드들을 갱신해주면 됩니다. 만약 아래 그림처럼, 7번 인덱스arr[7]를 수정한다고 했을 때 다음과 같이 수정합니다.
def update(start, end, index, what, value):
# 범위 밖에 있는 경우
if what < start or what > end:
return
# 범위 안에 있으면 내려가면서 다른 원소도 갱신
tree[index] += value
if start == end:
return
mid = (start + end) // 2
update(start, mid, index * 2, what, value)
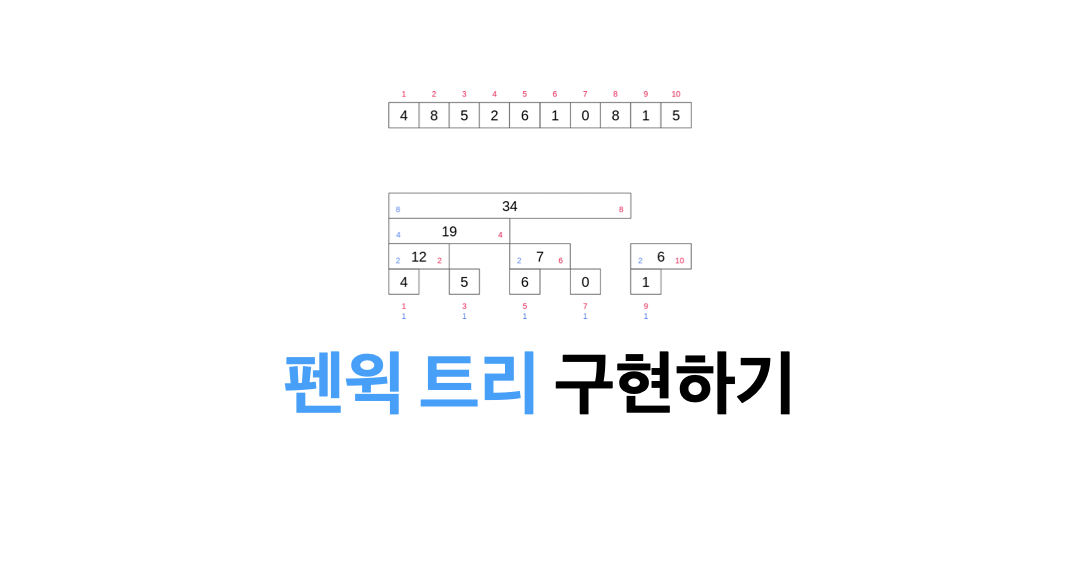
update(mid + 1, end, index * 2 + 1, what, value)펜윅 트리
펜윅 트리는 세그먼트 트리의 변형으로 수열의 구간합을 빠르고 쉽게 구할 수 있는 자료구조입니다. 세그먼트 트리에 비해 적은 메모리 공간을 사용할 수 있다는 장점을 가지고 있습니다.
사전 지식
펜윅트리는 비트 연산을 통해 값을 구할 수 있는 자료구조입니다. 그러므로 비트 연산에 대한 간단한 지식을 알고 갈 필요 있습니다.
- 정수 n을 2진수로 표현 했을 때, 1이 존재하는 최하위 비트 삭제하기.(0으로 만들기)
예를 들어, 1011에 반복 적용하면 1010, 1000, 0000 이 된다.
n &= (n-1)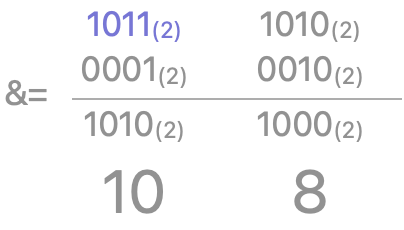
- 정수 n을 2진수로 표현 했을 때, 1이 존재하는 최하위 비트에 1을 더하기
예를 들어, 1011에 반복 적용하면 1100, 10000, 100000 이 된다.
n += (n & -n)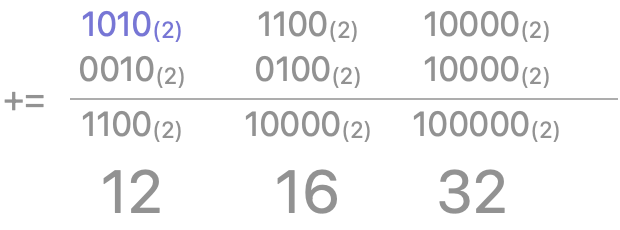
구조
펜윅 트리는 홀수 번째 인덱스를 배열 값에 저장하고 짝수번쨰는 블록 만큼 구간 합 정보를 저장하게 되기 때문에 각 층의 짝수 인덱스를 무시하면 펜윅트리를 얻을 수 있습니다.
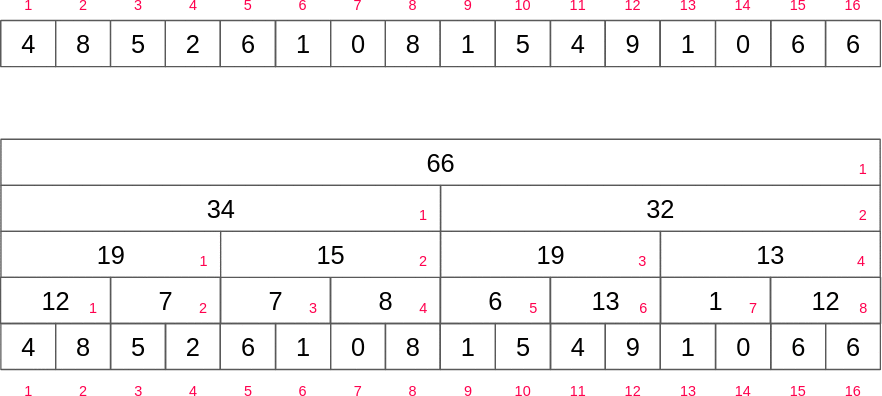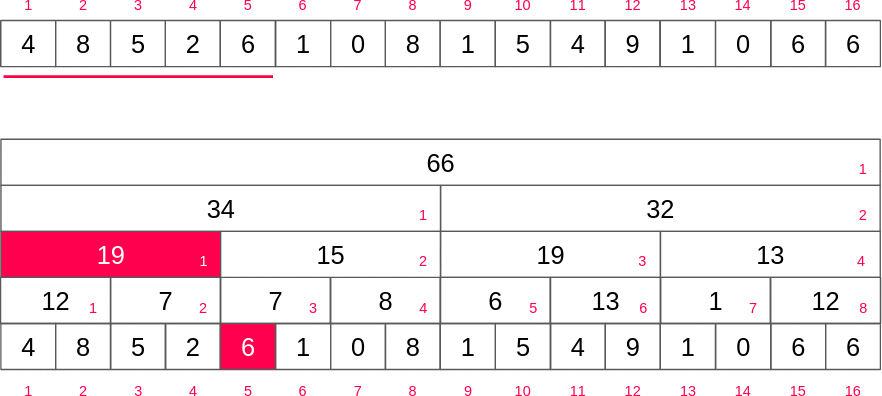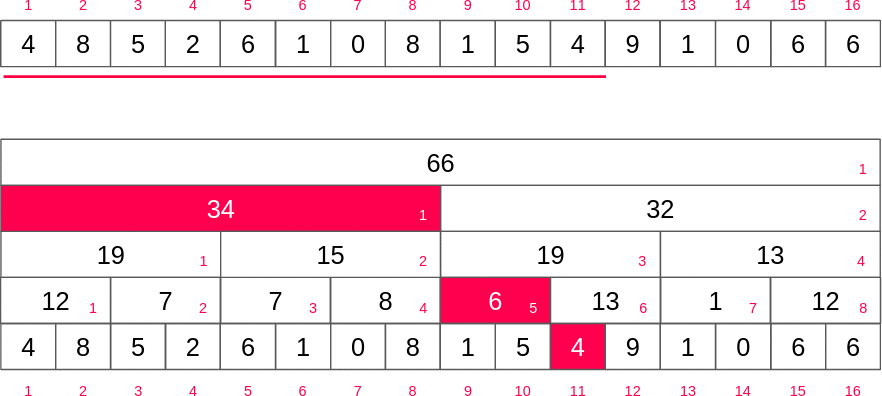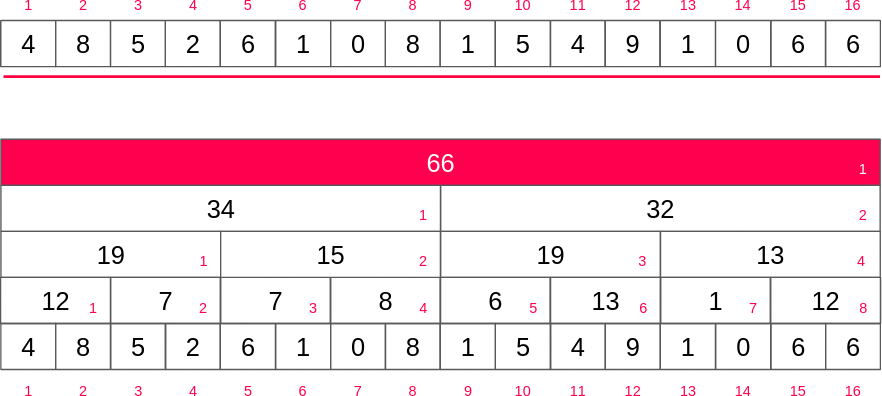
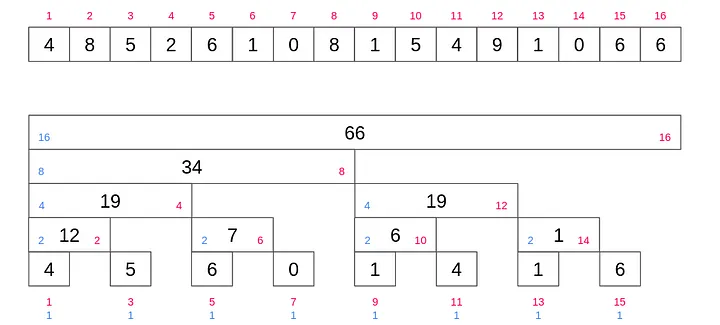
부분합 구하기
만약 10번째 인덱스까지의 구간합을 구한다고 가정하면 10의 이진수는 1010이기 때문에 여기서 최하위 비트(0010)를 빼면 8(1000)이 될 것입니다. 그러면 아래와 같은 식으로 1부터 10까지의 합을 쉽게 구할 수 있습니다.
- 6(
tree[10]+ 34(tree[6]) = 40
def sum(i):
ret = 0
while i > 0:
ret += tree[i]
i -= (i & -i) # 최하위 비트 빼기
return ret업데이트
만약 arr[3]의 원소의 값을 변경하게 된다면 어떻게 변경할 수 있을까? arr[3]과 연관된 값들을 모두 변경해주면 됩니다.
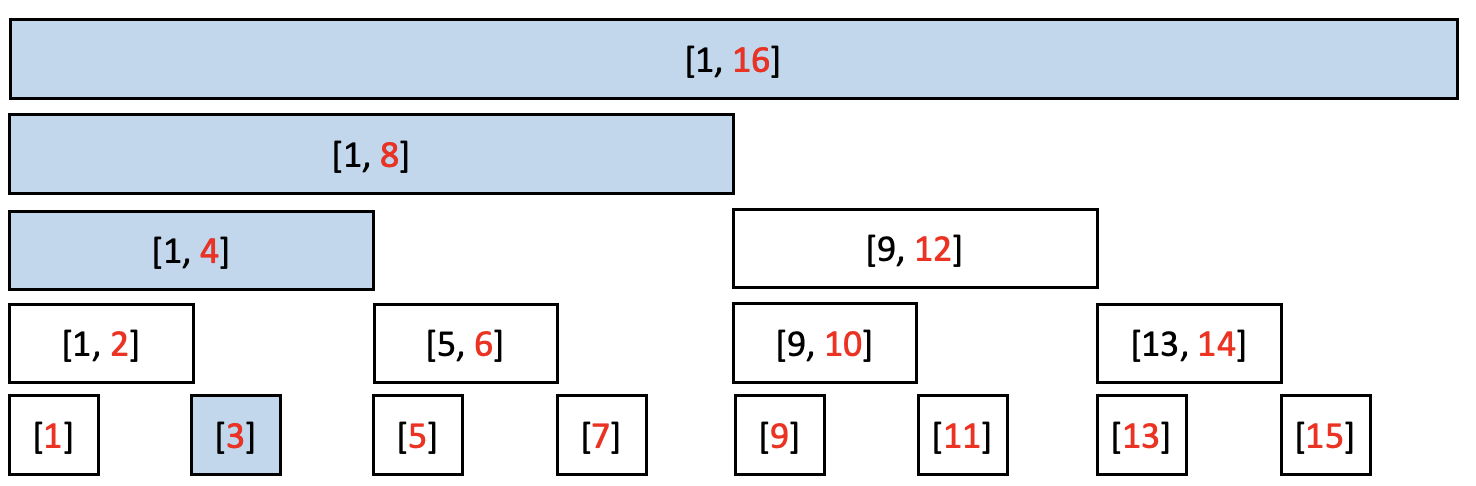
def add(i, num):
while i <= n:
tree[i] += num
i += (i&-i) # i가 마지막 인덱스(n) 올때까지 반복구간합 구하기
실제로 위 부분합과 업데이트를 이용해 구간합을 구해보도록 합시다.
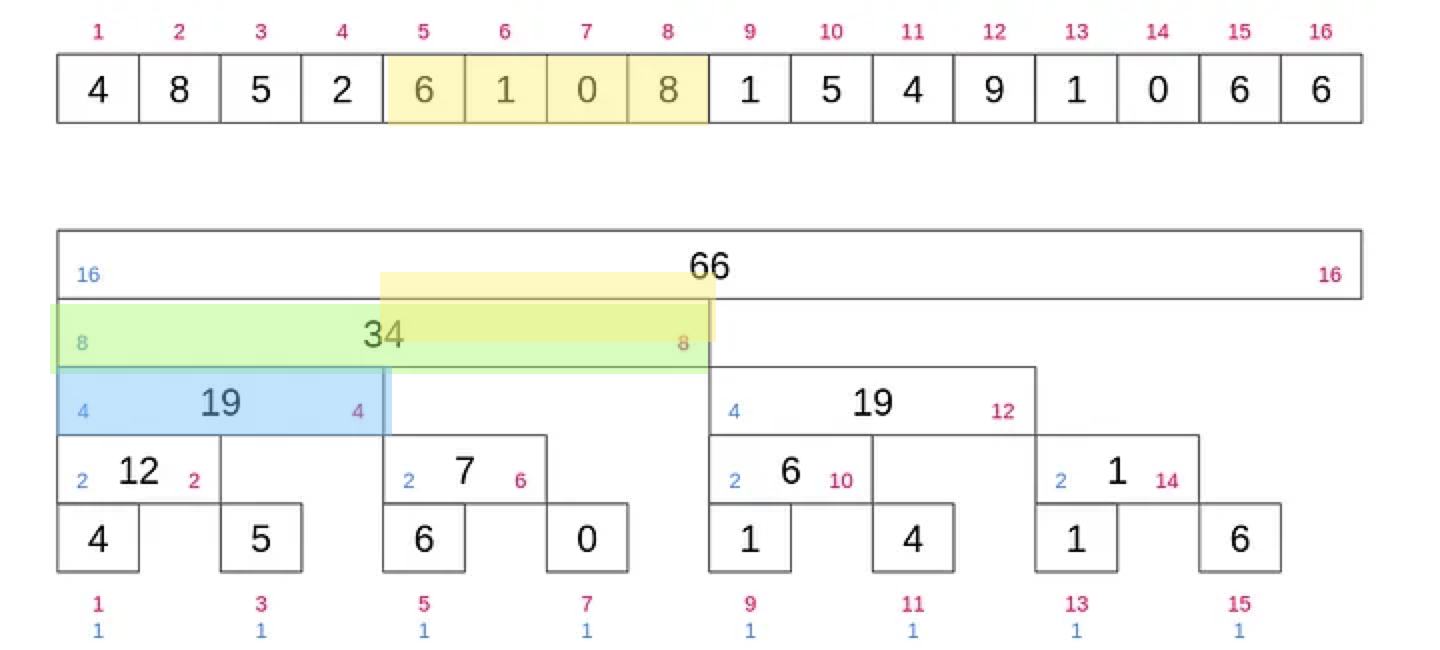
생각보다 쉽습니다.
위 8번까지의 부분합에서 4까지의 인덱스를 제거해주면 됩니다.
def range_query(l, r):
return sum(r) - sum(l-1)구간 업데이트
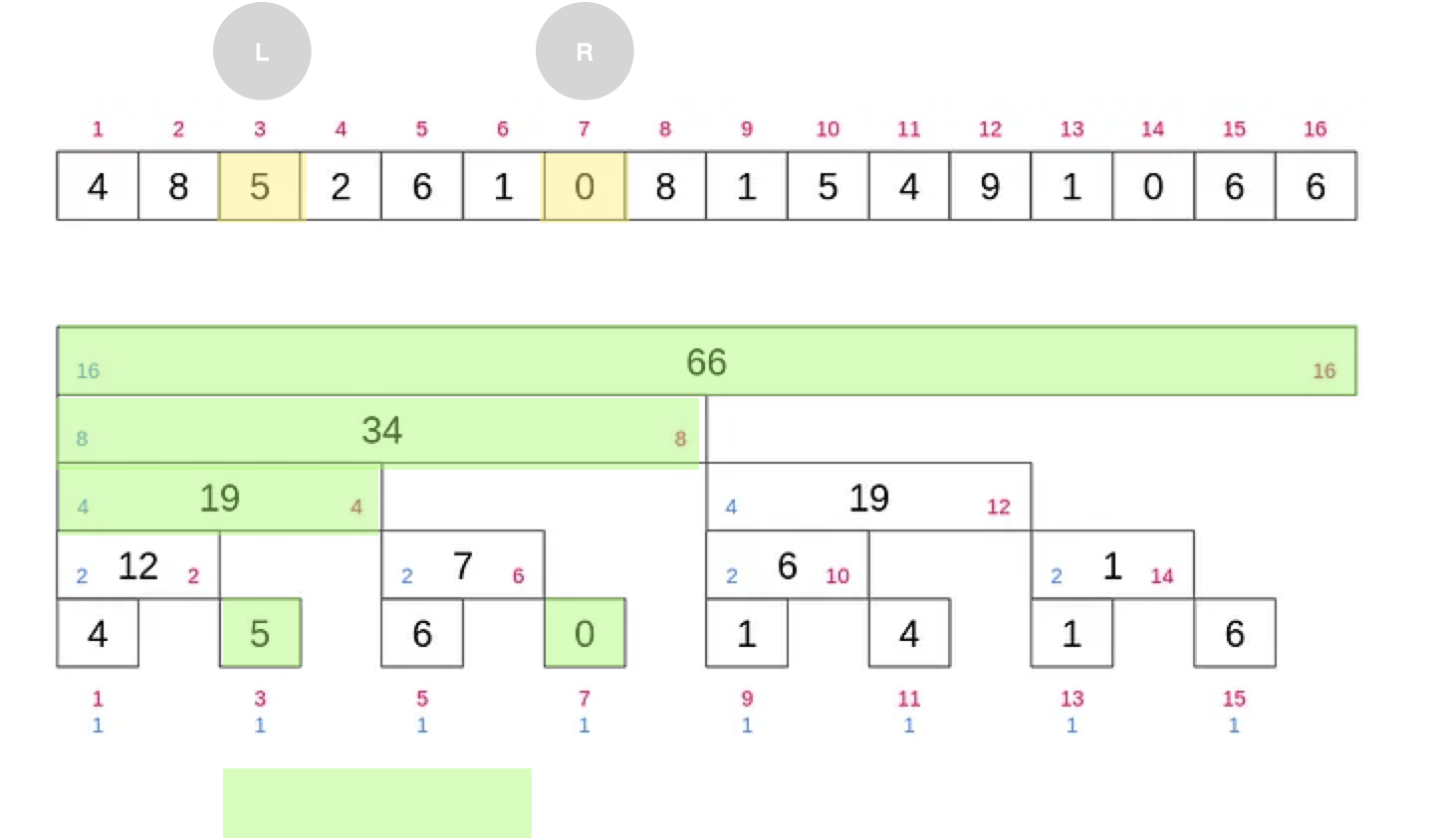
def range_update(l, r, x):
add(l, x)
add(r+1, -x)관련 문제
https://www.acmicpc.net/problem/2042
