
이번 포스트에서는 머신러닝 분야에 관심을 가지고 있는 구직자분들에게 제가 평소에 자주 해왔고 또 해드리고 싶었던 조언과 가이드라인들을 정리해 드리려고 합니다! 저는 현재 머신러닝 엔지니어로 근무중이기도 하고, 평소에도 교육과 멘토링과 같은 활동을 하다 보니 많은 구직자분들을 만나고 또 다양한 질문들을 받게 되는데요. 이 때 가장 많이 받는 질문이 바로 이겁니다
머신러닝 기초는 공부했는데, 뭘 더 해야 할지 모르겠어요 ㅠㅠ
그리고 이 글과 영상은 그런 질문에 답해드리기 위해 제작되었어요
글을 읽으시기 전, 벨로그 Like와 유튜브 구독 및 좋아요는 큰 힘이 됩니다.
예제만 반복하는 포트폴리오, 뭐가 문제일까

인공지능, 딥러닝과 관련된 많은 교육과정과 콘텐츠들에는 비슷한 예제들을 주고는 합니다 이미 잘 준비된 학습 데이터를 주고, 유명한 모델을 한 번 학습을 돌려보는 거죠. 그리고 나서는 이를 간단히 로드해서 서버나 클라이언트에서 실행은 가능하게 만들어 보는 것 정도죠. 그래서 대부분의 포트폴리오도 이런 과정을 반복하는 데에서 멈춰있고는 합니다
데이터? 유명한거 써
모델? 남이 만든 것 쓰자
학습? 적당히 하자
검증? 잘 됬겠지
개발? 돌아는 가네
자동화? 손맛이지
당연히, 이런 프로젝트를 한 번 하면서 전체적인 과정을 한 번 경험하는 건 상당히 좋습니다. 문제는 그 이후죠, 직무적인 조사가 선행되지 않으면 여기서 뭐를 더 공부해 볼지 막히는 순간이 오게 됩니다.
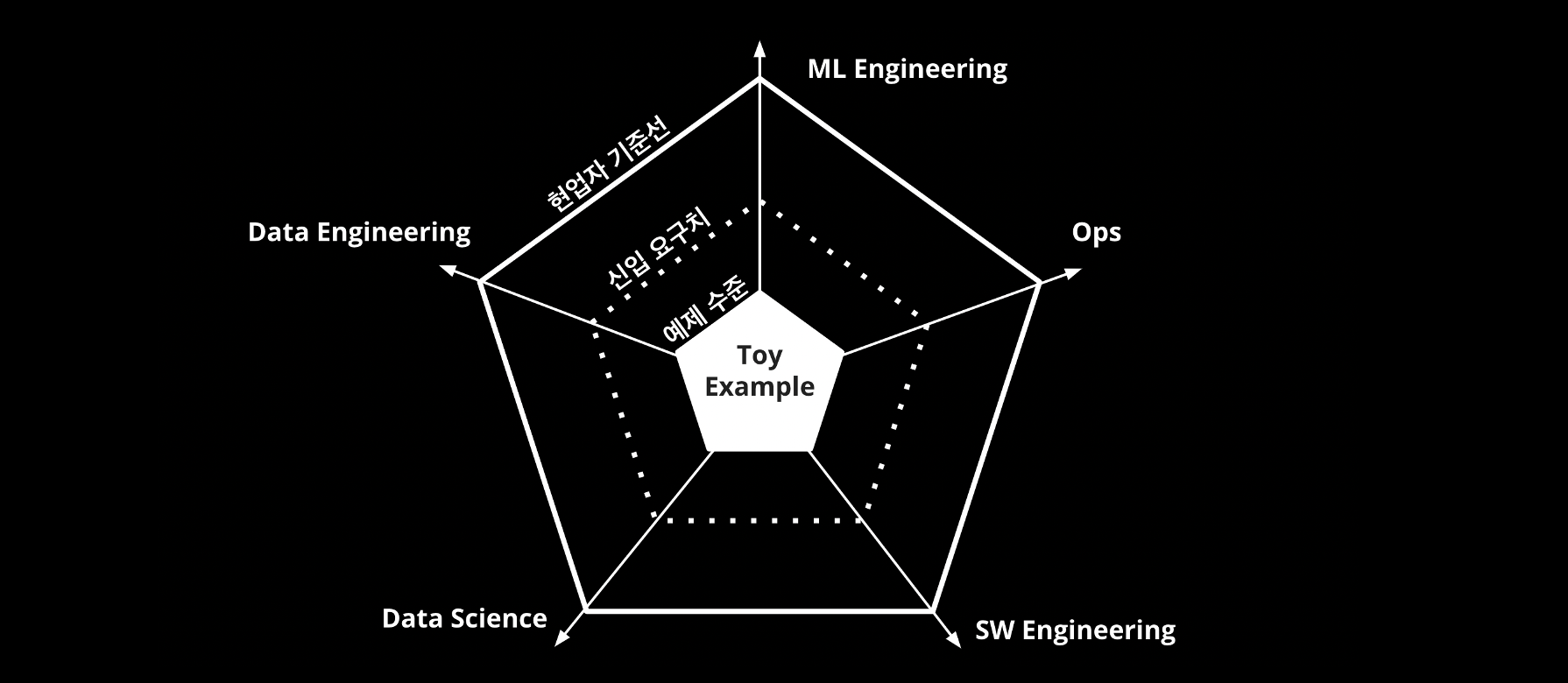
저는 항상 여러 개의 토이 프로젝트를 하는 것보다 하나의 프로젝트에서 새로운 문제들을 설정하고 이걸 본인이 풀어가면서 성장 로그를 남기는 게 신입으로서 최고의 포트폴리오가 된다고 말을 합니다.잘 준비된 데이터, 간단한 문제, 이미 구현된 모델, 내 눈에만 만족하면 되는 서비스 정도는 당연히 내가 챌린지 하게 다가오는 부분이 없기 때문에 포트폴리오에 자랑할 만한 멘트가 내가 생각해도 떠오르지 않는 거죠.
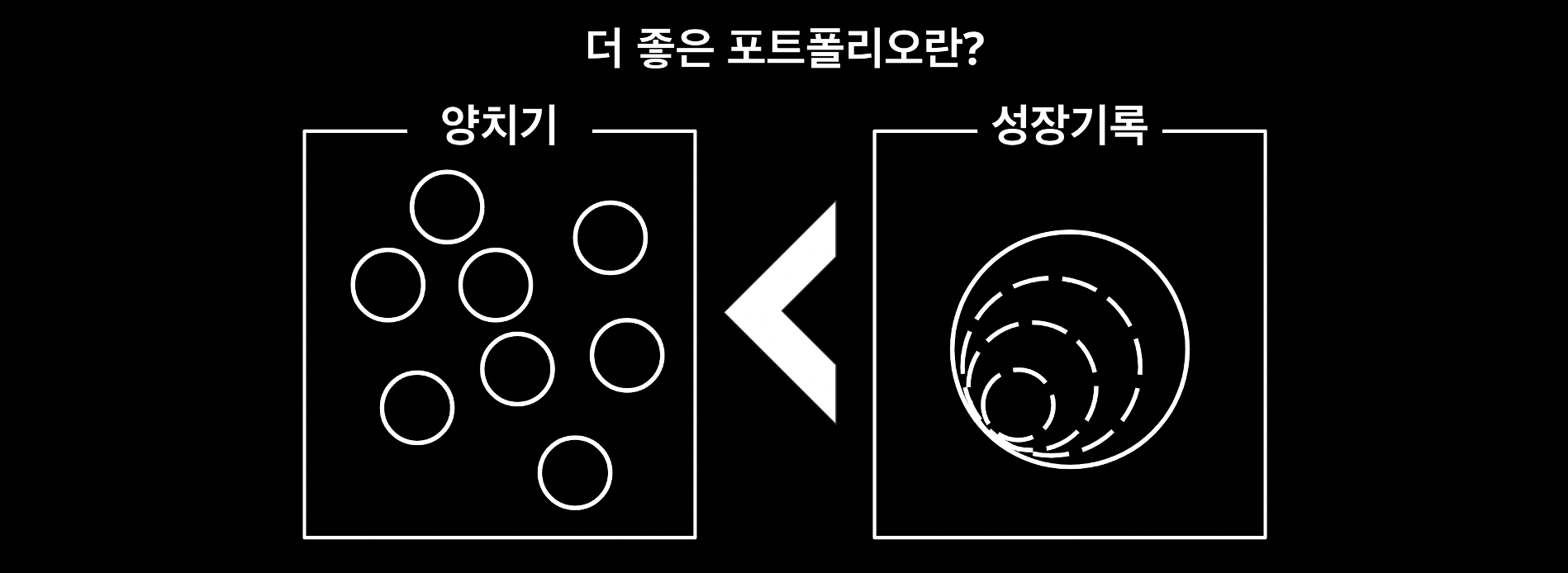
그럼 뭘 공부하지?
그렇다면, 다들 똑같이 하는 Toy Example을 넘어서 어떤 것들을 해보면 좀 새로운 시도들을 해볼 수 있을까요? 그래서 여러분들께 몇 가지 해봄직한 시도들이나 몇 가지 키워드들을 짚어드리려고 합니다.
이걸 전부 하시라는 것도, 현업자 수준으로 익히라는 것도 아닙니다
(그럼 이 글을 안 보고 있을껄요?)
이 중에 본인이 재밌어 보이는 것들을 하나씩 골라서
- 현업에서는 이런 문제들 겪고 이렇게 해결하고 있구나
- 이런 직무들이 있고 이런 역량을 요구하는구나
이런 것들을 조사하면서, 본인의 포트폴리오와 직무적인 방향을 완성해나가라는 뜻입니다. 이런 것들을 인식하고 공부해 보는 것만으로도 정말 상위 10%의 신입이 될 수 있다고 보장합니다
어떤 프로젝트를 하면 좋을지 설명을 위해서, 머신러닝이 하나의 제품/서비스로서 완성되기 위해 필요한 단계를 다음과 같이 구분해 볼게요
- 데이터의 수집과 분석
- 문제와 모델 설계
- 모델 학습과 실험
- 모델의 최적화와 배포
- 서비스 개발
1. 데이터의 수집과 분석 단계
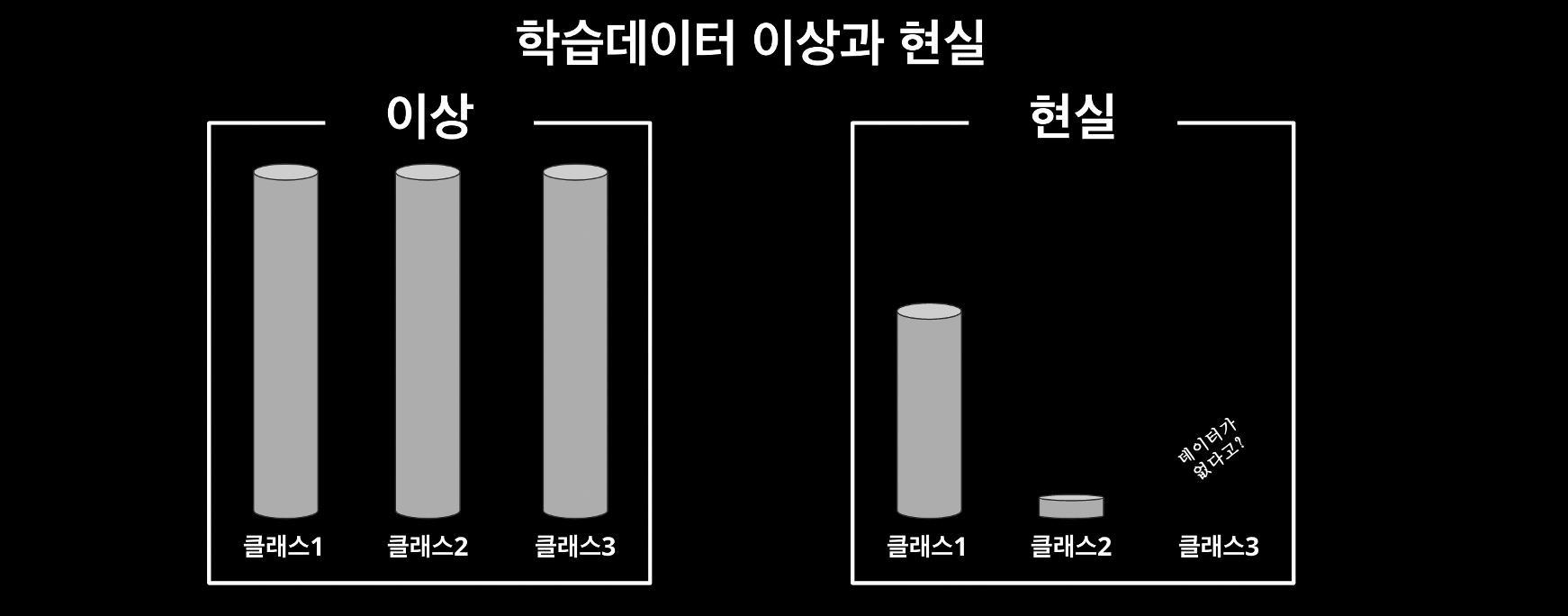
현업에서 여러분이 마주치는 데이터들은 여러분이 다루었던 토이 프로젝트에서 다루었던 예시들과는 다르게
수집에서조차 어려움이 많을 것이고, 기껏 수집하더라도 그 데이터 수가 부족하거나 클래스 불균형(Class Imbalance) 같은 문제를 마주치게 될 겁니다.
그러면 이 상황부터 재현을 해보세요! 여러분들이 사용한 이미 잘 축적된 데이터들을 일부러 덜 사용하고, 불균형하게 사용해 보는 겁니다. 그리고 이런 상황에서는 실제로 어떤 식으로 성능을 최대한 개선해 내는지에 대해 고민해 보고 하나씩 탐색해 보는 겁니다. 내 데이터를 시각화해서 분석해 보고, 어떤 데이터가 얼마큼 부족할지 분석해 본다던가 augmentation, one-class learning, data synthesize 같은 기법들을 찾아보고 실제로 데이터가 불균형한 사례들을 스스로 비교 정리를 하거나 재현해 보는 것도 좋은 포트폴리오가 되겠죠.
여러분의 오해와는 다르게 대부분의 현업 문제는 쉽게 재현이 가능합니다. 이 예시만 보아도 그렇죠?
그리고 아마 여러분들은 레이블링이 다 되어 있는 데이터를 다루거나, 레이블링이 아주 쉬운 Classification 정도의 문제만을 시도해보고는 할 겁니다. 여러분들도 본능적으로 잘 아시는 거죠. 데이터 레이블링은 아주 귀찮고 비용이 큰 작업이라는 사실을, 특히나 단순히 분류가 아닌 Segmentation, NLP, 음성인식과 같은 문제는 더더욱 눈앞이 깜깜할 건데요. 내가 생각해도 귀찮아서 하기 싫은 일들이 바로 산업에서는 피해 갈 수 없는 문제가 됩니다.

공부 특 : 귀찮은 것은 피함
업무 특 : 귀찮아도 못 피함
그럼 여기에 도전해 보시는 거예요. 데이터가 많거나 레이블링이 힘든 데이터일 때, 이를 어떻게 레이블링하고 관리할지 고민해 보고 이를 하나의 GUI 툴로서 만들어 보는 겁니다. 본인이 관심 있는 서비스 개발 스택이 있다면 이 기회에 한 번 활용해 보는 거죠. 그리고 이런 주제를 정하면 비슷한 사례도 상당히 많이 있기 때문에 참고해서 클론 코딩하기도 좋을 겁니다.
이쯤 왔으면 데이터 자체도 비싸고 레이블링도 힘든 데이터도 분명히 현업에 존재할 것이라는 사실을 알 것이고 여러분들은 ‘레이블링의 효율성'에 대한 의문도 드셔야 해요. 그렇다면 자연스럽게 최소한의 레이블링으로 최대한의 효용을 내는 경제적인 방법이 없나에 대한 궁금증이 생기실 수 있고 자연스럽게 Activate Learning, Semi-Supervised Learning 같은 키워드를 찾아보실 수 있습니다.
2. 문제와 모델 설계 단계
사실 이 단계에서는 여러분들이 완전 연구 쪽을 지향하지 않는다면 뭔가 새로운 것들을 해보기는 쉽지 않을 거예요. 그렇기 때문에 기존에 잘 구현되어 있는 모델들이나 설계 테크닉들을 정리해 보고, 이를 재현해 보는 훈련이 가장 좋습니다.
모델 재현이 가능하다는 것 자체가, "하나의 논문을 분석할 수 있고 이를 직접 구현할 정도로 기반 지식이 갖춰져 있다"는 걸 나타내기 때문에, 내가 관심 있는 분야의 모델들을 정리해 보고 구현해 보는 훈련만으로도 좋은 포트폴리오가 됩니다. 그리고 새로운 문제들을 접하는 방법 중 하나는 kaggle competition 등을 활용하는 건데요. 새로운 데이터랑 문제들을 다루는 훈련을 할 수 있습니다.
3. 모델 학습/실험 단계

가장 간단하게는 어떻게 하면 조금이라도 더 모델을 빠르게 학습할 수 있을지, 아니면 같은 시간을 투자해도 더 나은 성능을 보이는 모델을 만들 수 있을지에 대해서 고민해 보세요.
단순히 파라미터를 바꿔가며 노가다를 하는 것이 아니라, 내 노가다를 대신해 줄 수 있는 학습 스크립트를 짜보고 나아가서 Parameter Search나 AutoML에 대해서 찾아보거나, 아니라면 학습 속도를 가속화할 수 있는 Quantization이나 효율적인 Transfer Learning, Incremental Learning 같은 학습 기법 등을 찾아볼 수 있겠죠.
그리고 여러분이 이런 시도들을 반복하면 분명히 현업과 마찬가지의 문제를 겪게 됩니다. 데이터는 계속 변하고, 모델 구조는 변하고, 내 실험 결과들은 쌓여만 갈 텐데요.

그럼 대체 이런 것들을 어떻게 관리, 검증, 기록할지 그리고 사람 손이 덜 들게 자동화할지에 대한 고민으로 이어나가보세요. 이렇게 많은 모델들을 다 어떻게 평가하고, 테스트하고, 히스토리를 관리할지. 서비스적으로 ‘좋은 모델'이란 무엇인지 고민하면서요.
예를 들어서, 일부러 데이터들을 나누어서 조금씩 스토리지에 추가되게 자동화 스크립트로 만들어서 데이터가 쌓여가는 상황을 재현해봅니다. 그리고 이런 이벤트들에 벌어져야 할 일들을 하나의 자동화된 플랫폼으로 만들어보자는 식으로 뻗어나가면 자연스럽게 MLOps와 같은 키워드에 봉착하게 될 겁니다.
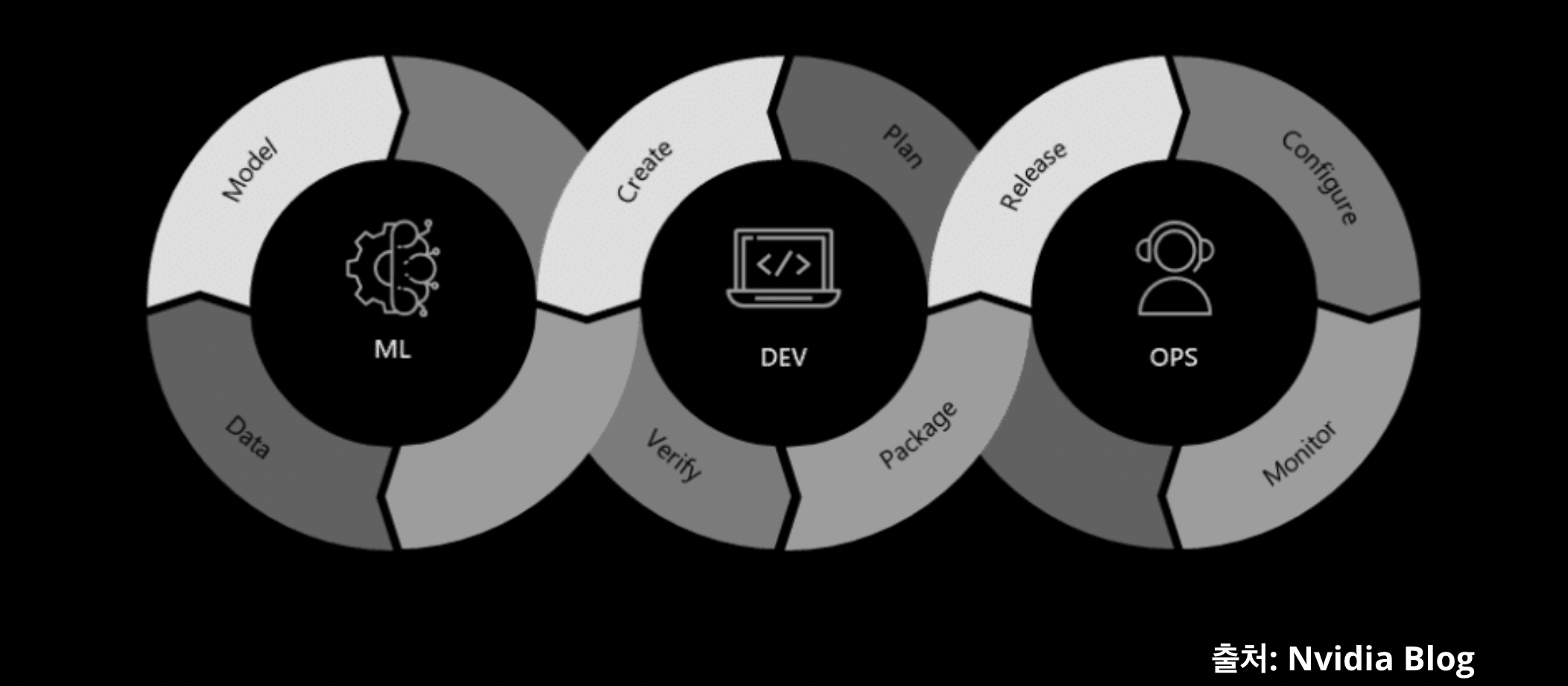
4. 모델의 배포와 최적화

앞서의 과정들을 통해서 드디어 내가 원하는 모델이 선택이 되었습니다! 하지만 우리는 결과적으로 하나의 소프트웨어로서 제공을 해야겠죠? 모델만 고객에게 던져주고 마는 비즈니스를 할 게 아니라면요. 그렇다면 어떤 환경으로 제공을 할 수 있을까요? 백앤드 서버에 서빙을 할 수도 있을 것이고, 직접 유저의 PC, 모바일 같은 클라이언트 환경에 배포를 할 수도 있을 겁니다.
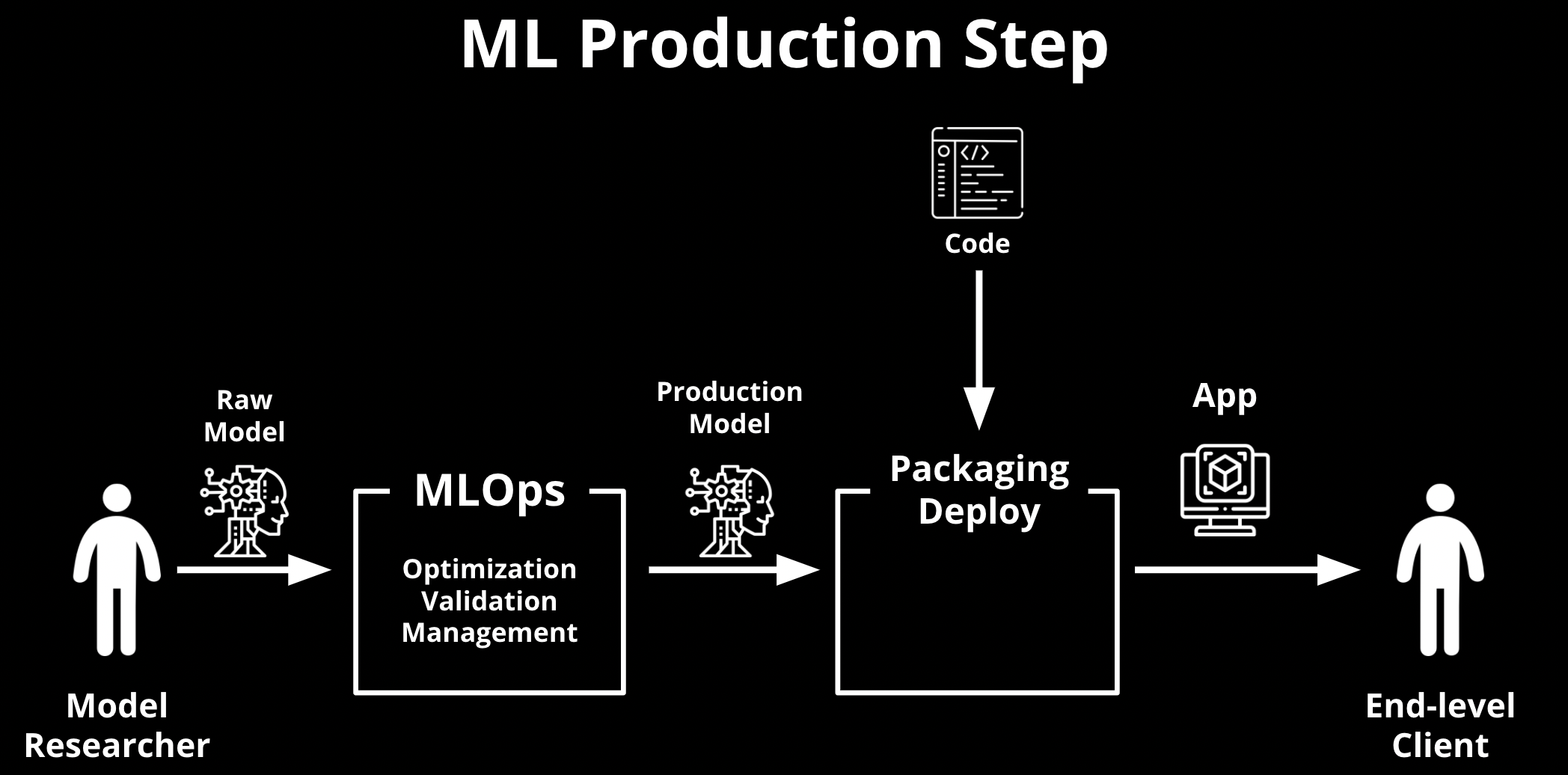
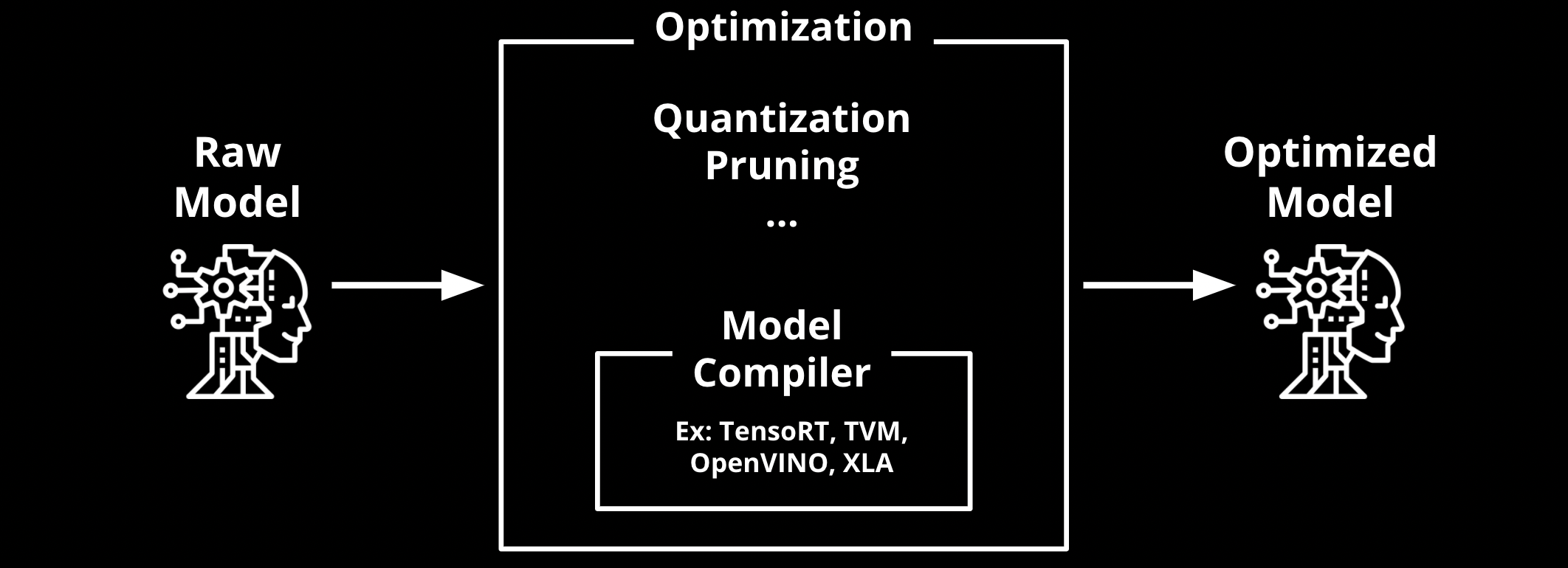
그렇다면 이러한 환경에서 어떻게 잘 배포를 할 수 있을지 보안과 패키징에 대한 고민을 하게 될 것이고, 각각의 로컬에서 조금 더 효율적인 추론을 할 수 있게 Model Compiling이나 Quantization 같은 성능적인 고민도 하게 되겠죠. 그 환경이 유저의 API 요청을 받는 백앤드라 면 동시에 여러 유저가 많이 요청하면 어쩌지?라는 물음을 던지고, 비동기 메시징큐나 캐싱 같은 키워드를 찾아보게 될 겁니다.
5. 서비스 개발 단계
앞서에서의 배포된 모델을 어떻게 활용해야 유저가 느끼기에 느리거나 불편하지 않은 서비스가 만들어질지 고민해 볼 수 있을 거고요. 모델의 크기가 크다면 언제 로드하고 릴리즈해야 할지, 어떻게 업데이트 받을지 와 같은 성능적인 고민도 해볼 수 있겠죠. 만약에 사용하는 유저의 패턴에 따라서 개인화된 서비스를 만들어보고 싶다? 이렇게 개인화된 로컬 학습은 어떻게 이루어지는지라는 키워드도 찾아볼 수 있겠죠.
결국은 소프트웨어 엔지니어링
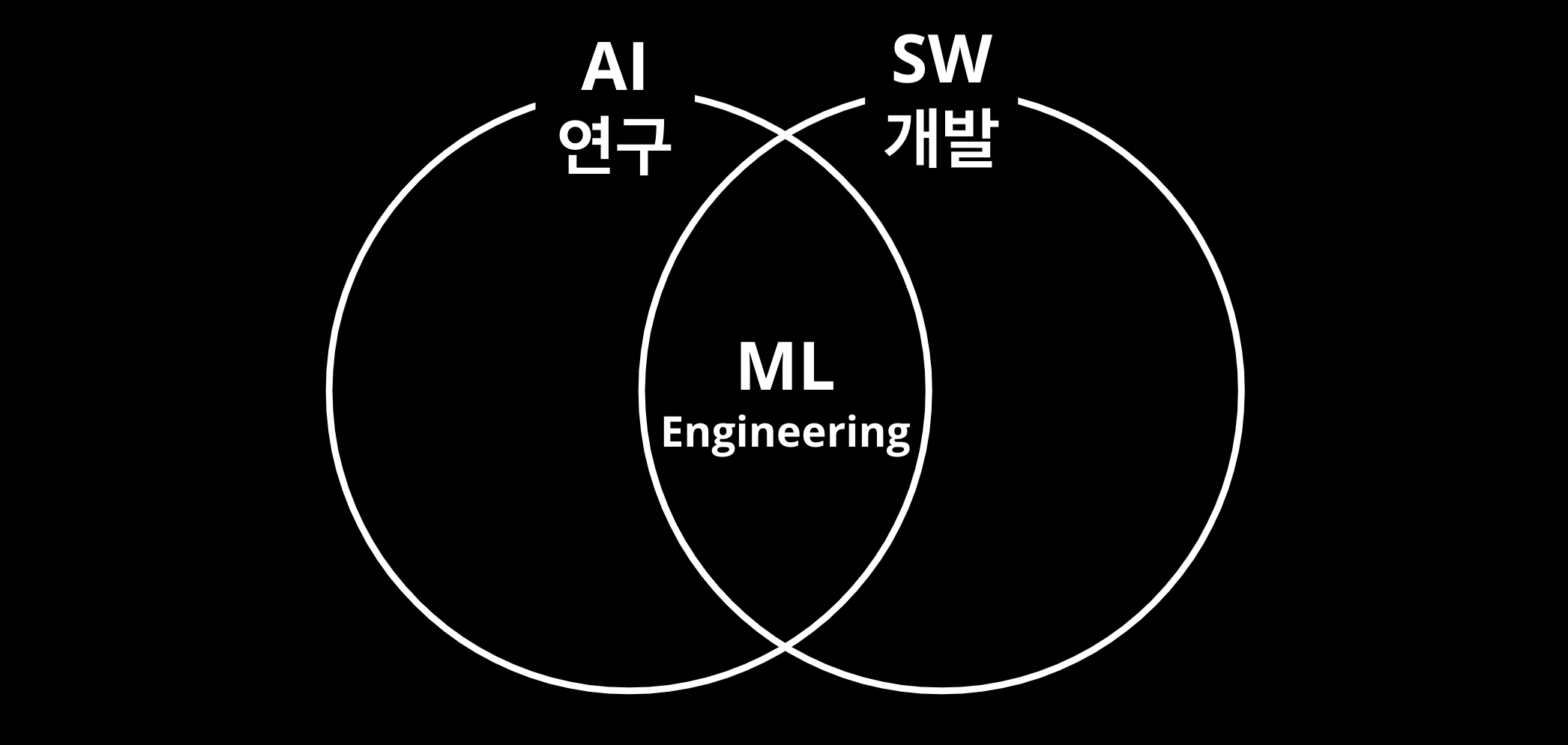
많은 분들에 데이터쪽 직군들이 수학적인 연구나 분석만 중요할 것이라고 오해를 하고는 합니다
하지만 여러분들의 생각과는 다르게, 대부분의 종사자들은 소프트웨어 엔지니어링을 때려야 땔 수 없는 환경에 놓여 있습니다. 뭐 분석이나 연구만 하더라도, 대용량 데이터를 다루는 기술이나 알고리즘의 재현을 위한 프로그래밍을 필요로 합니다. 결국 소프트웨어 형태의 제품을 만드는 이상 소프트웨어 엔지니어링은 필수불가결한 요소입니다.
현실적으로, 신입 채용에서 Computer Science지식에 대한 테스트나 코딩테스트 그리고 과제 전형 등은 빠지지 않는 요소죠. 그리고 신입에게 가장 중요한 취업 루트 중 하나인 공채에서는 이런 경향이 더더욱 강해지고요.
대부분의 분들은 결국 ML/DL에 대해 잘 이해하고 있는 소프트웨어 엔지니어가 될 확률이 높습니다
그러니 서비스 개발 직군과 벽을 두지 마시고, 공유되는 CS 지식이나 코딩 테스트에 대한 공부는 꼭 해두셔야 합니다
이렇게 총 세 가지 여러분들이 준비해야 할 관점을 요약해 드렸습니다
- 구체적인 직무 탐색과 커리어 목표 설정하기
- 새로운 문제 설정, 해결과정을 포트폴리오 만들기
- 소프트웨어 엔지니어링과 컴퓨터공학 기본기 공부하기
구독과 좋아요는 힘이 된답니다 :)

9개의 댓글


머신러닝/AI 뿐 아니라 모든 SW분야에 통용되는 말이라고 생각해요
애초에 SW는 기존의 불편을 효율적으로 해결하기 위해 나왔으니까요 😀
좋은글 잘 읽고갑니다 ㅎㅎ




Security should come first and at the moment I don't feel completely safe when I trade on a crypto exchange. This is one of the reasons why I am afraid to trade.
그림들이 이쁜데 무슨툴로 작업하셨나요