
01. Numpy
- 다차원 배열을 쉽고 효율적으로 사용할 수 있도록 지원하는 파이썬 라이브러리
- 데이터 분석 라이브러리에 많이 사용됨
1-1. ndarray
- numpy의 핵심 데이터 구조
- 동일한 자료형의 다차원 배열
import numpy as np
ndarray의 생성
a = np.array([[1, 2, 3], [4, 5, 6]])
b = np.array([1.0, 3.14, 1.24])배열의 구조
print(f"배열의 구조: {a.shape}")
print(f"배열의 구조: {b.shape}")배열의 차원 수
print(f"배열의 차원 수: {a.ndim}")
print(f"배열의 차원 수: {b.ndim}")데이터 타입
print(f"배열의 데이터 타입: {a.dtype}")
print(f"배열의 데이터 타입: {b.dtype}")형변환
new_a = a.astype(np.float64)
print(f"수정한 배열의 데이터 타입: {new_a.dtype}")
# 3차원 행렬
a = np.array([[[1, 2, 3], [4, 5, 6]],
[[1, 2, 3], [4, 5, 6]],
[[1, 2, 3], [4, 5, 6]]])배열의 구조
print(f"배열의 구조: {a.shape}")배열의 차원 수
print(f"배열의 차원 수: {a.ndim}")4차원 행렬
a = np.array([[[[1, 2, 3], [4, 5, 6]]],
[[[1, 2, 3], [4, 5, 6]]],
[[[1, 2, 3], [4, 5, 6]]],
[[[1, 2, 3], [4, 5, 6]]]])
# 배열의 구조
print(f"배열의 구조: {a.shape}")
# 배열의 차원 수
print(f"배열의 차원 수: {a.ndim}")1-2. 배열 초기화
- 모든 요소가 0인 배열 생성
- np.zeros()에 넣는건 행렬의 구조를 넣는 것이다.
np.zeros((3, 4)) # 2차원 행렬
np.zeros((2, 3, 4), dtype = np.int64) # 3차원 행렬모든 요소가 1인 배열 생성
np.ones((5, 6))(원소의 값이) 초기화 되지 않는 배열 생성
np.empty((2, 3))주어진 값으로 채운 배열
np.full((3, 3), 7)단위 행렬
np.eye(3, 3)
np.eye(3, 5, 1)1-3. 범위 기반 배열 생성
- arrange: range()와 유사한 기능 제공
- 시작 이상 끝 미만의 정수 배열을 지정한 간격으로 생성
np.arange(0, 10)
np.arange(0, 10, 2)linspace: 시작부터 끝까지 균일 간격으로 지정한 개수만큼 숫자를 생성
- 끝을 포함함
np.linspace(0.1, 1, 10)1-4. 랜덤 배열 생성
random.rand(m, n): 0 ~ 1 사이의 난수로 초기화
np.random.rand(4, 5)random.randn(m, n): 표준정규분포를 따를 난수로 초기화
- 표준정규분포: 평균 0, 분산 1인 정규분포
np.random.randn(2, 4, 5)random.randint(low, high, size)
np.random.randint(10, 20, (2, 4))random.seed(): 난수 생성시 시작값 제공
np.random.seed(58)
np.random.randn(2, 3)RNG(Random Number Generator): 최근 Numpy 사용에서 권장되는 방식
from numpy.random import default_rng
rng1 = default_rng(seed = 42)
rng2 = default_rng(seed = 10)
print(rng1.random((3, 2)))
print(rng2.random((3, 2)))실습 1-1
np.zeros((3, 4))
np.full((3, 4), 5)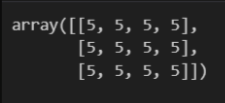
실습 1-2
np.arange(0, 21, 2)
실습 1-3
np.random.rand(2, 3)
실습 1-4
m, sigma = 100, 20
m + sigma * np.random.randn(1, 6)
실습 1-5
A = np.random.randint(1, 20, (1, 20))
B = np.reshape(A, (4, 5))
B결과
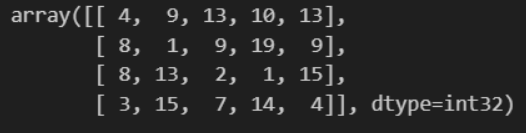
실습 1-6
A = np.linspace(0, 1, 12)
B = np.reshape(A, (3,4))
B결과

실습 1-7
A = np.random.randint(0, 100, (10, 10))
B = np.eye(10, 10)
C = A + B
print(A)
print(C)
A = np.random.randint(0, 10, (2, 3, 4))
A결과
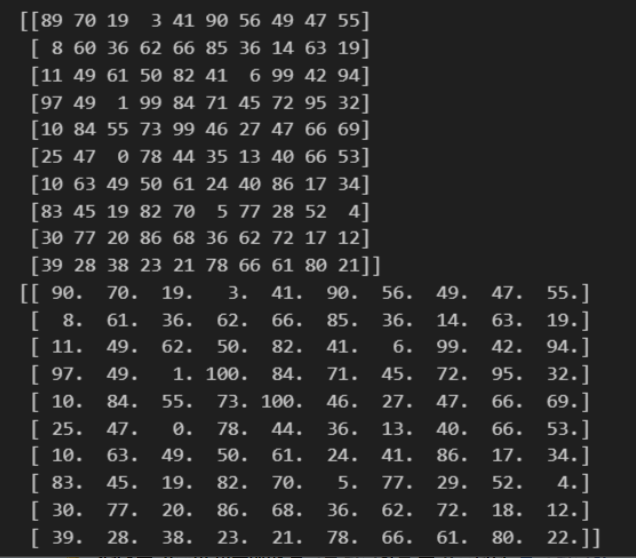
1-5. 인덱싱과 슬라이싱
- 다차원 배열을 다루는 편의 기능 제공
- Python의 시퀀스보다 빠름
인덱싱
a = np.array([10, 20 , 30, 40, 50])
print(a[2])
print(a[-1])다차원 인덱싱
- 파이썬 리스트
matrix =[[1, 2, 4], [4, 5, 6]]
print("파이썬 인덱싱: ", matrix[1][1])- numpy 배열
a = np.array([[1, 2 , 4], [4, 5, 6]])
print("numpy 인덱싱: ", a[1, 1])3차원 배열 인덱싱
b = np.arange(24).reshape(2, 3, 4)
print(b)
print("3차원 인덱싱: ", b[1, 1, 1])
# 슬라이싱
# arr[행_슬라이스, 열_슬라이스]
# arr[..., 4차원 슬라이스, 3차원 슬라이스, 2차원 슬라이스, 1차원 슬라이스]
a = np.array([10, 20, 30, 40, 50])
print(a[1:3])
print(a[2:])
print(a[:2])
print(a[::2])
print(a[::-1])파이썬 리스트와의 차이
- 파이썬 리스트
py_list = [10, 20 , 30 , 40, 50]
sliced = py_list[1:4]
sliced[1] = 100
print("py원본: ", py_list)
print("py슬라이싱: ", sliced)
print()
a = [10, 20 , 30 , 40, 50]
a_sliced = a[1:4]
a_sliced[1] = 100
print("py원본: ", a)
print("py슬라이싱: ", a_sliced)실습 2-1
arr = np.arange(10, 30, 2)
arr[1:6:2]결과

실습 2-2
arr = np.arange(1, 10).reshape(3, 3)
print(arr)
print(arr[0, 0])
print(arr[1, 1])
print(arr[2, 2])
# print(arr[[0, 1, 2], [0, 1, 2]])결과
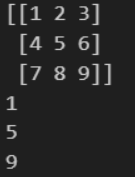
실습 2-3
arr = np.arange(1, 13).reshape(3, 4)
# arr[0, 3] = -1
# arr[1, 3] = -1
# arr[2, 3] = -1
rows, columns = arr.shape
for i in range(rows):
arr[i, 3] = -1
arr
# arr[:, -1] = -1결과
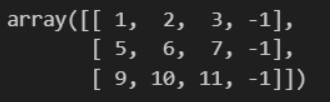
실습 2-4
arr = np.arange(1, 17).reshape(4, 4)
print(arr)
rows, columns = arr.shape
# 행 역순
for i in range(rows):
print(arr[rows -1 -i])
# print(arr[::-1])
# 열 역순
for i in range(rows):
arr[i] = arr[i][::-1]
print(arr)
# print(arr[:, ::-1])결과
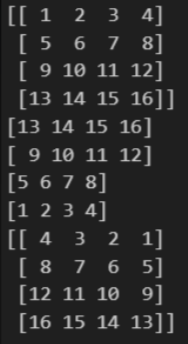
2차원 배열 슬라이싱
a = np.arange(1, 21).reshape(4, 5)
print(a)- 행 슬라이싱
print(a[0])
print(a[1])
print(a[1:3])
print(a[2:])
print()- 열 슬라이싱
print(a[:, 2])
print(a[:, -1])
print(a[:, 1:3])
print()- 행과 열 슬라이싱
print(a[1:3, 2:4])
print(a[2:, 3:])
print(a[::2, ::2])- 3차원 슬라이싱
a2 = np.arange(36).reshape(3, 3, 4)
print(a2)
print(a2[1, 1, 1:3])얕은 복사: 복사본이 원본과 메모리를 공유 -> 변경사항이 서로에게 영향을 줌
a1 = np.array([1, 2, 3])
a1_viewed = a1.view()
a1_viewed[1] = 10
print("원본", a1)
print("복사본", a1_viewed)깊은 복사: 복사본이 원본과 독립적으로 복사됨. -> 서로 영향을 주지 않는다.
a2 = np.array([1, 2, 3])
a2_copied = a2.copy()
a2_copied[1] = 10
print("원본2", a2)
print("복사본2", a2_copied)Fancy Indexing
- 정수 배영을 사용하여 여러 인덱스로 여러 요소를 한 번에 선택
af = np.arange(1, 21)
print(af)
print(af[[4, 7, 11]])
af2 = np.arange(1, 21).reshape(4, 5)
print(af2[[1, 3], [2, 4]])Boolean Indexing
ab = np.linspace(10, 100, 10)
print(ab)
print(ab[ab > 40])
print()Boolean masking
ab2 = np.arange(0, 21)
print(ab2)
mask = ab2 % 2 == 0
print(mask)
print(ab2[mask])실습 2-5
arr = np.arange(1, 21).reshape(4, 5)
sliced_arr = arr[1:3, 1:4]
copied_arr = sliced_arr.copy()
print(copied_arr)결과
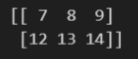
실습 2-6
arr = np.array([[4, 9, 12, 7], [10, 15, 18, 3], [2, 14, 6, 20]])
condition = (arr % 2 == 0) & (arr >= 10)
print(arr[condition])결과
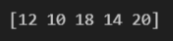
실습 2-7
arr = np.arange(1, 26).reshape(5, 5)
take_arr = arr[[1, 3], :][:, [4, 0, 2]]
print(take_arr)결과
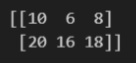
실습 2-8
arr = np.array([[10, 20, 30], [55, 65, 75], [40, 45, 50], [70, 80, 90], [15, 25, 35]])
rows, columns = arr.shape
for i in range(rows):
if arr[i, 0] >= 50:
print(arr[i])
# arr[arr[:, 0] >= 50]결과
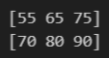
실습 2-9
arr = np.arange(1, 17).reshape(4, 4)
print(arr[[0, 1, 2, 3], [1, 3, 0, 2]])결과

실습 2-10
arr3d = np.arange(24).reshape(2, 3, 4)
arr3d_take = arr3d[0:, : , 1]
print(arr3d_take)결과
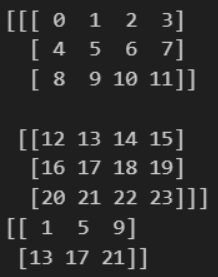
실습 3-1
arr = np.arange(0, 25).reshape(5, 5)
print("가운데 행", arr[2])
print("가운데 열", arr[:, 2])결과
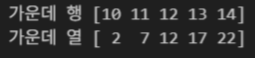
실습 3-2
arr = np.random.randint(0, 100, (10, 10))
print(arr)
print(arr[[1, 3, 5, 7, 9], :])결과
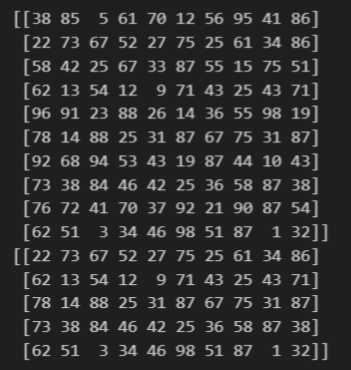
실습 3-3
arr = np.arange(0, 50).reshape(5, 10)
print(arr)
arr_sliced = arr[1: 4, 2:8]
print(arr_sliced)결과
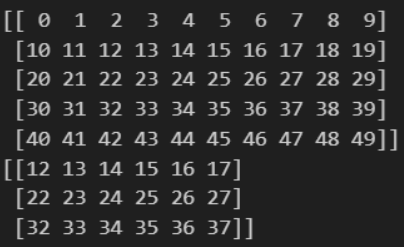
실습 3-4
arr = np.random.randint(0, 10, (4, 4))
rows, columns = arr.shape
print(arr)
for i in range(rows):
for j in range(columns):
if i == j:
print(arr[i, j])
for i in range(rows):
for j in range(columns):
if i + j == columns - 1:
print(arr[i, j])결과
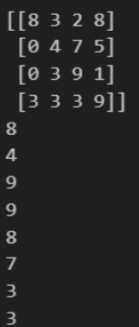
실습 3-5
arr = np.random.randint(0, 10, (3, 4, 5))
print(arr)
print(arr[1, 0, 4])결과
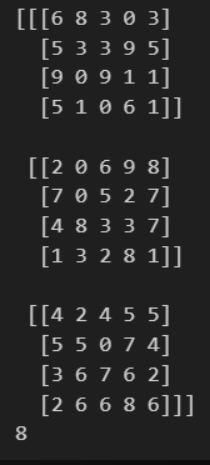
실습 3-6
arr = np.arange(35, 75)
print(arr)
arr_new = arr.reshape(10, 4)
print(arr_new)결과
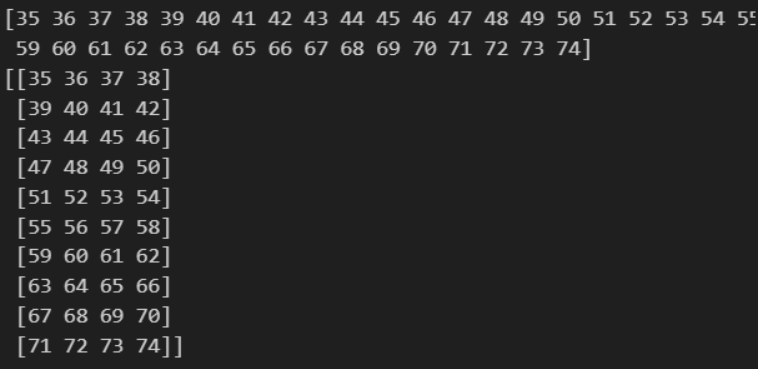
실습 3-7
reverse_arr_new = arr_new[::-1]
reverse_arr_new결과
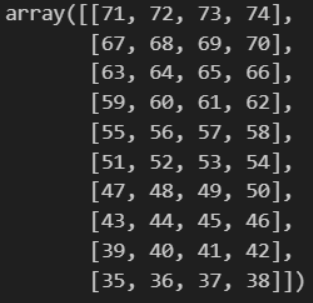
실습 3-8
slicing_arr = arr_new[1:9, 2: 4]
print(slicing_arr)결과
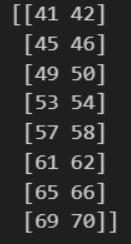
실습 3-9
matrix1 = np.random.randint(1, 51, (5, 6))
print(matrix1[matrix1 % 2 == 0])결과

실습 3-10
matrix2 = np.arange(0, 100).reshape(10, 10)
print(matrix2[0:5:2, 1:6:2])결과
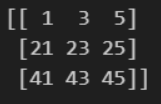
실습 3-11
arr = np.random.randint(0, 10, 15)
condition = (arr[::2] >= 5)
print(arr)
print(arr[::2][condition]) 
동윤2입니다.