
본 글은 제가 이해한 것을 기반으로 작성되었기 때문에 논리적오류 및 비약이 존재할 수 있습니다. Reference
📊Likelihood(우도, 가능도)
확률 vs 우도
- 우도와 확률은 다음과 같은 notation으로 정의됩니다. 그러나 실제로 이 정의는 굉장히 위험한 논리적 비약을 포함하고 있습니다.
- 확률(probability)은 분포의 파라미터 가 정해진 상태에서 Data가 목격될 정도를 의미합니다.
- 가능도(Likelihood)는 Data가 관측된 상태에서 특정 확률분포(Gaussian, Bernoull,etc..)에 대한 믿음의 강도를 나타내는 값이며 Data가 관측되었을 때 어떤 확률분포의 가 unknown인 것을 의미합니다. 즉, Likelihood function은 이므로 x는 고정된 상수값이고 에 대한 함수인 것 입니다.

그렇다면 우도는 어떻게 계산할까?
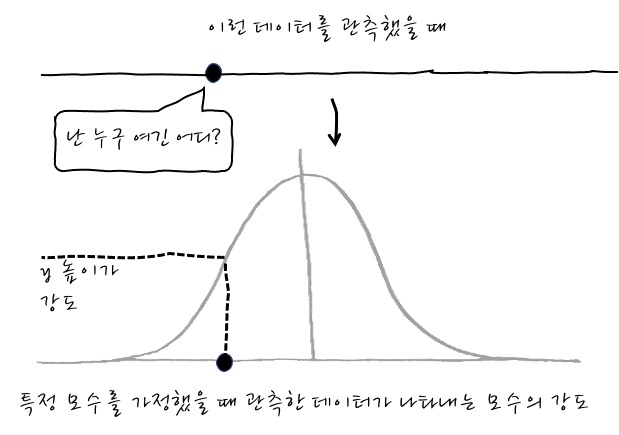
- 만약 가 특정한 값으로 주어진다면, Likelihood function은 함수가 아니라 상수가 되어 어떤 Strength를 나타내게 됩니다. 즉, 모수를 가정해서 를 특정하게 되면 관측한 데이터에서의 strength을 구할 수 있게 되는 것이죠.
- 따라서 다음과 같은 정리가 가능합니다. 우리가 가정한 분포에서 관측한 데이터에 대한 y에 해당하는 높이는 Strength, Likelihood와 동치가 됩니다.
관측한 데이터 대한 y에 해당하는 높이 = 분포에 대한 Strength = Likelihood
너무나도 햇갈리는 notation..그러나 생각보다 간단!
- Likelihood는 condition이 분명히 observed data가 있을 때, 에 대한 strength라고 했는데 막상 notation은 반대로 정의 되어있어서 혼란을 불러일으킵니다. 이는 계산을 위해서는 어쩔 수 없이 우리가 알고 있는 확률분포를 이용해야 하기 때문이라고 이해했습니다.
즉, 를 가지고 가 known일때는 확률, unknown일때는 Likelihood라고 한다.
