
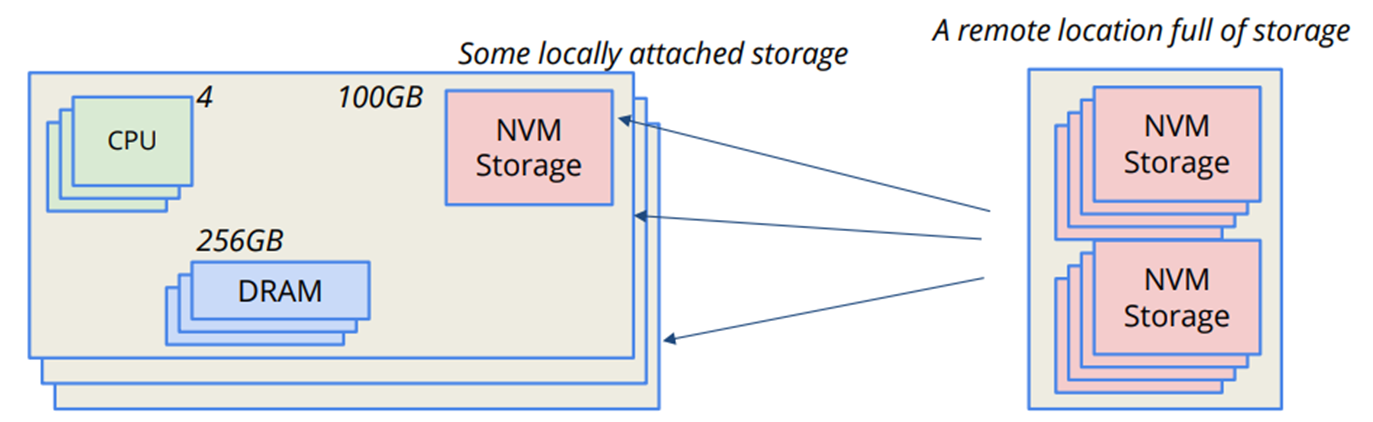
위 이미지처럼 연산 노드와 스토리지 노드를 분리하는 구조는 모던 컴퓨팅에서 아주 흔한 아키텍처이다. 필요한 하드웨어만 확장하면 되는 효율적인 구조이다. 그러나 I/O 스택에서 문제가 발생한다고 한다.
특히 네트워크와 디스크 I/O가 빨라질수록 커널 스택이 비효율을 초래한다.
Faster I/O ≠ Faster Application
이런 문제때문에 I/O가 빨라지더라도 애플리케이션이 반드시 빨라지지 않는다는 문제가 발생한다. 또한 얻을 수 있는 이점이 제한되는데 이것은 다양한 요인때문이다.
다양한 요인
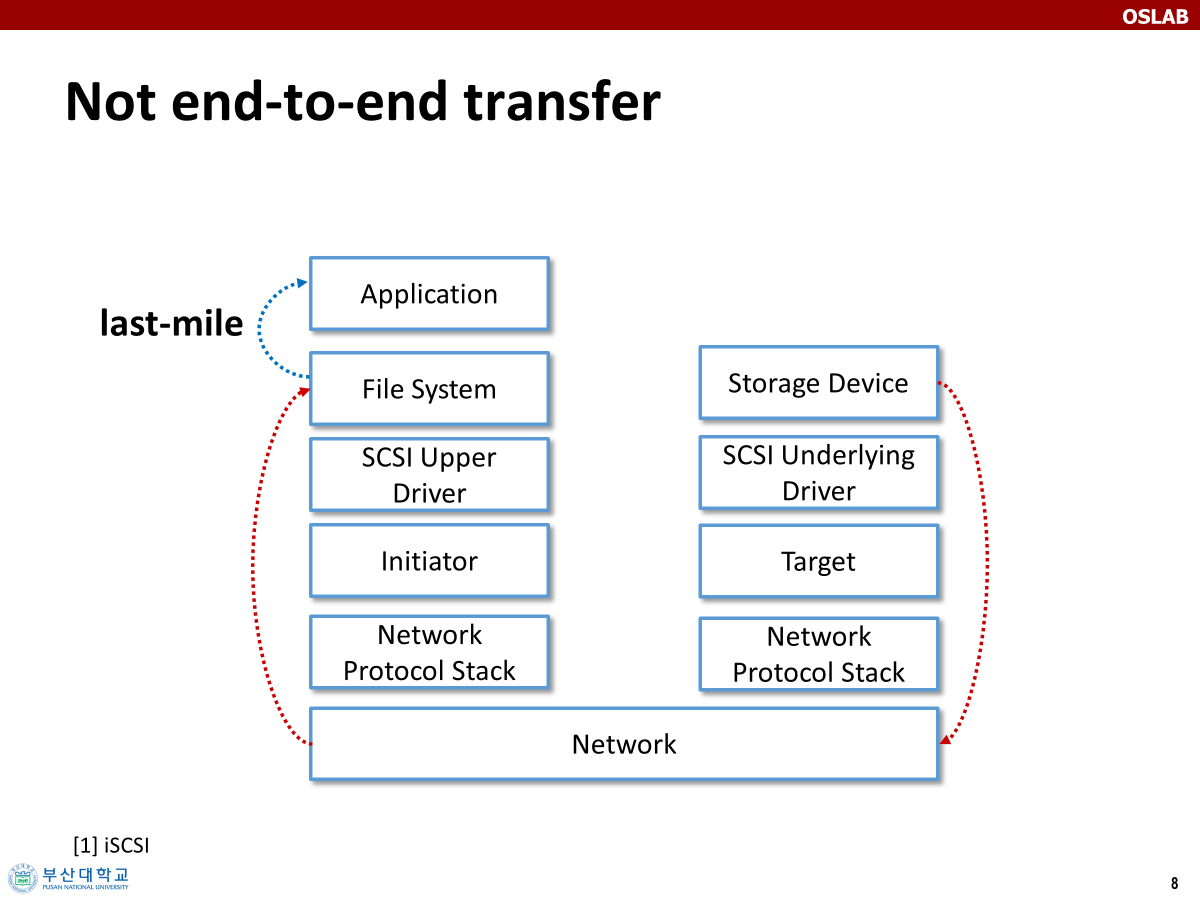
위 이미지를 살펴보면 iSCSI의 계층을 확인할 수 있는데, 스토리지 디바이스부터 애플리케이션까지 즉,End-to-End Point에서 거쳐야 할 계층이 아주 많다.
또한 파일 시스템과 애플리케이션 사이에 존재하는 라스트 마일로 인해 오버헤드가 발생한다.
라스트 마일
해당 경로를 이동하는 과정에서 컨텍스트 스위칭, 커널 복사, 캐시 미스와 같은 오버헤드가 발생한다.
베이스라인
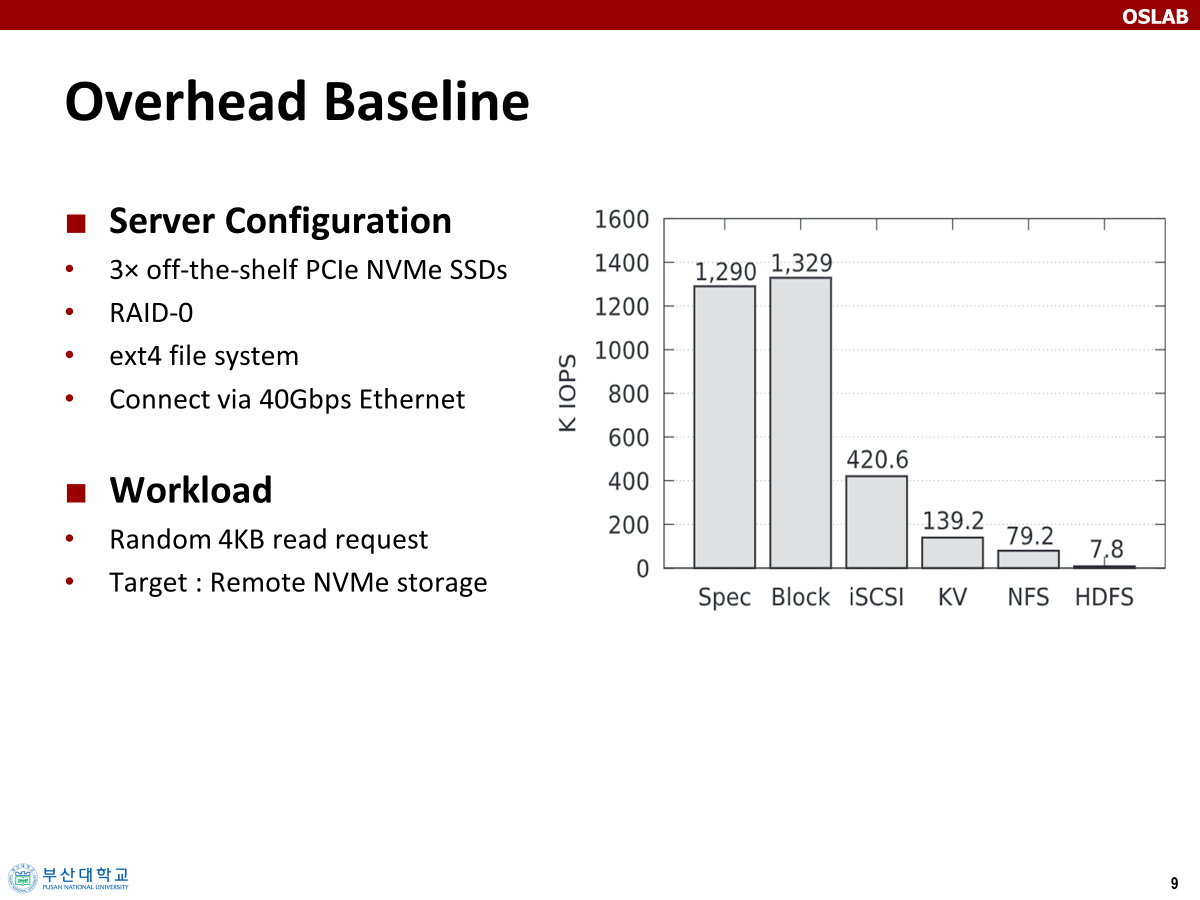
저자는 이를 위해 오버헤드를 정량화했는데, 의도적으로 작은 I/O 랜덤 읽기를 발생시켜서 부하를 발생시켰고, 그에 따른 애플리케이션들의 성능을 측정했다. 간접적으로 알 수 있는 것은 우측으로 갈수록 거치는 계층이 많아진다는 것이다.
one-side RDMA
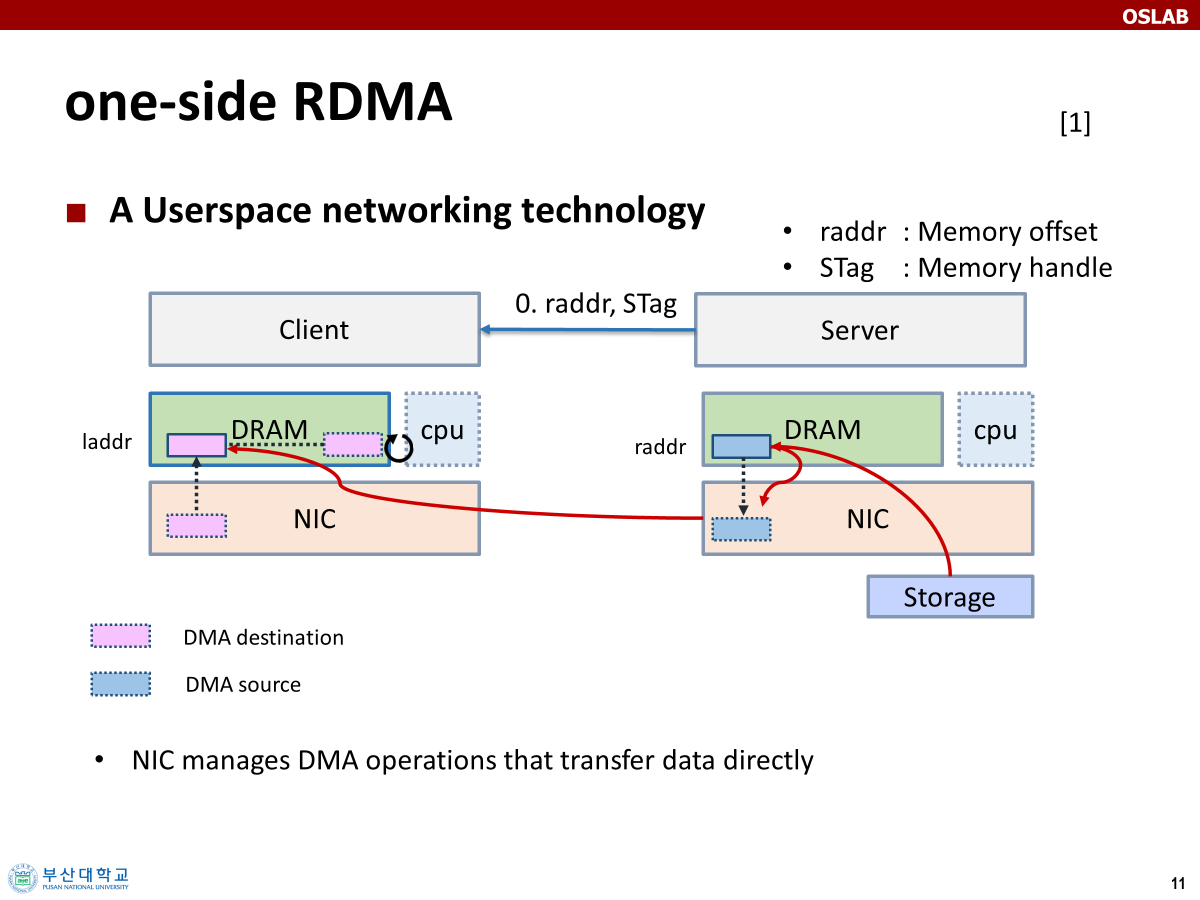
플래시넷의 디자인을 살펴보기 위해서는 one-side RDMA를 살펴보아야 한다. 버퍼를 통해 메모리 간 데이터 전송을 NIC가 중계하고, 해당 작업은 비동기적이기 때문에 실제로 완료되었는지 별도로 확인이 필요하다. 이 과정에서 CPU가 풀링을 통해 지속적으로 확인하는 방법이 있고, 혹은 NIC가 완료 이벤트를 발생시키는 방법이 있다.
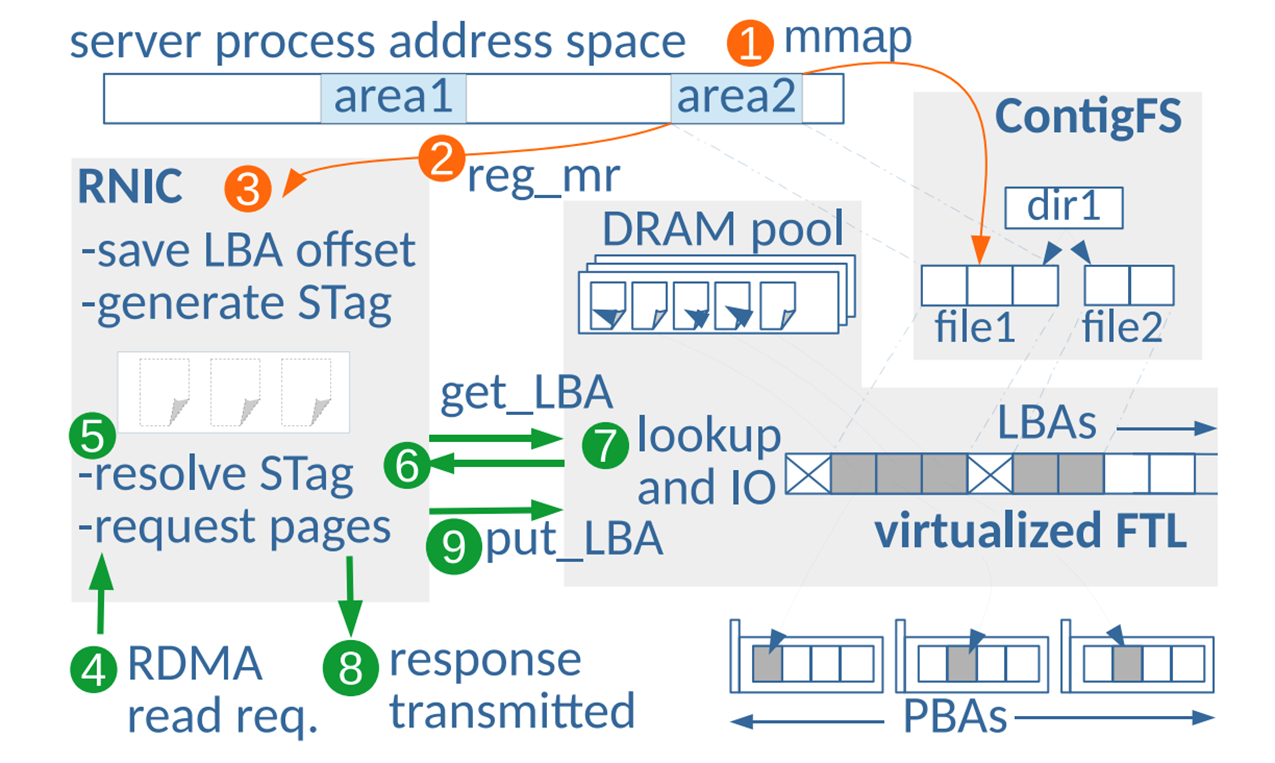
플래시넷은 위와 같은 구조로 동작한다. 주황색은 RDMA I/O를 위한 셋업 과정이며, 초록색은 실제 I/O 과정이다. 따라서 ContigFS는 오프라인 path이다. 그래서 RDMA와 Flash 컨트롤러만 온라인으로 I/O에 관여한다.
이때 두 컨트롤러 컴포넌트 사이에는 비동기 API를 통해서 통신되고, 더티 페이지 추적 및 빈도가 추적된다.
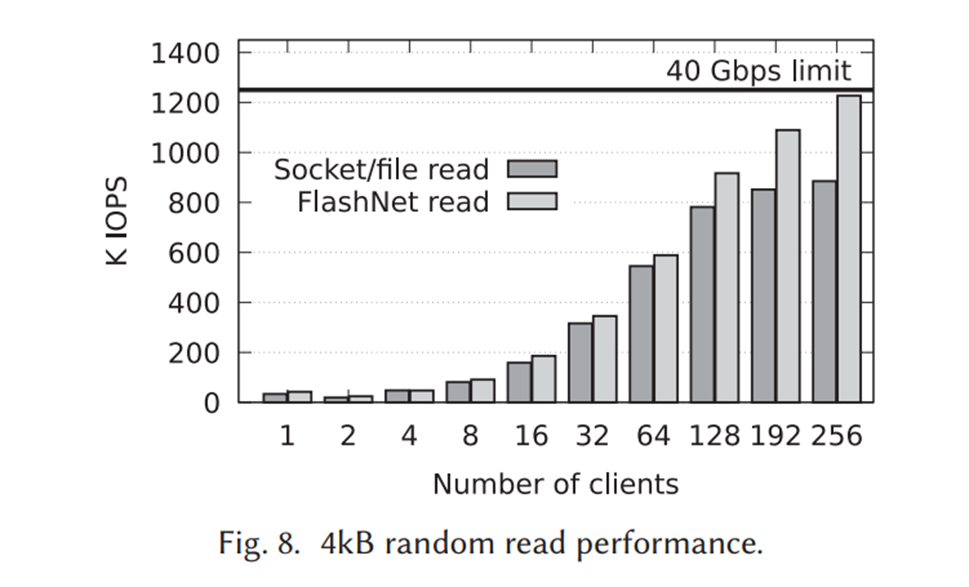
성능을 측정한 그래프로 4KB 랜덤 읽기 성능을 측정했다. 플래시넷이 전반적으로 더 우수하지만, 넘버=2 인 경우는 한 쪽에 I/O가 몰리는 경우가 있기 때문에 플래시넷이 더 낮은 모습을 보이기도 한다.
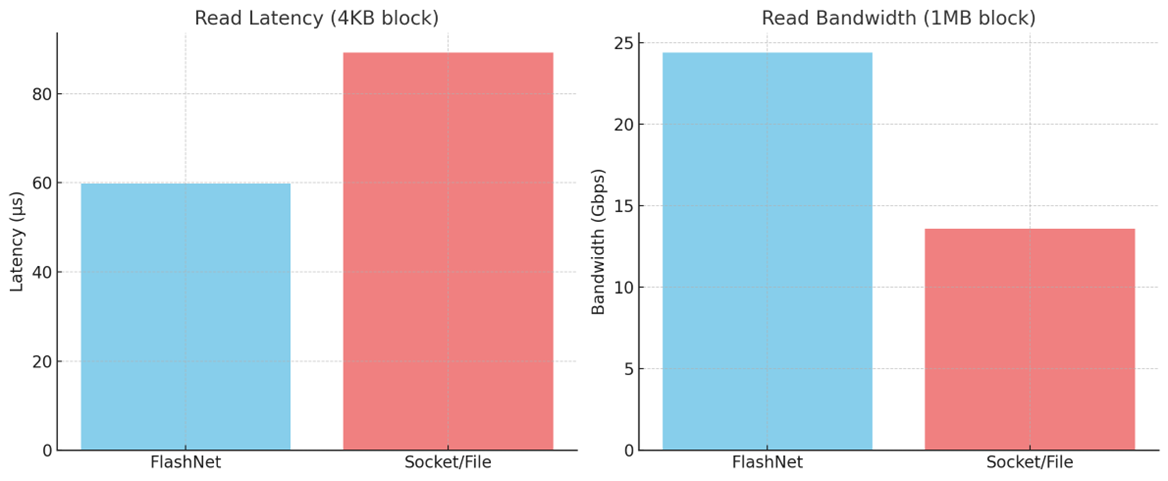
밴드위스와 레이턴시를 비교하여도 플래시넷이 더 우수하다.
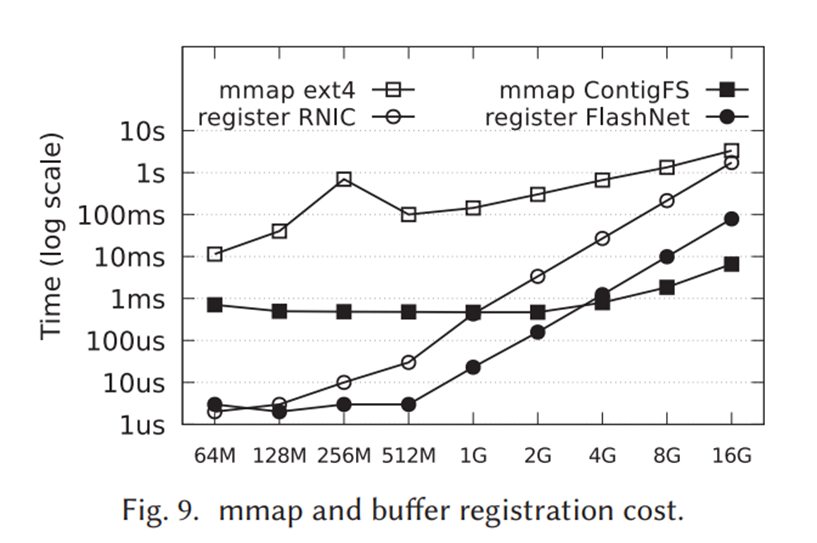
버퍼 등록 비용은 RDMA I/O에서 가장 비용이 많이드는데, mmap은 파일 시스템의 매핑 방식(extent vs range)로 플래시넷이 더 빠르며, register 같은 경우는 온-디맨드와 고정 핀 방식의 차이로 이 경우도 플래시넷이 더 우수하다.
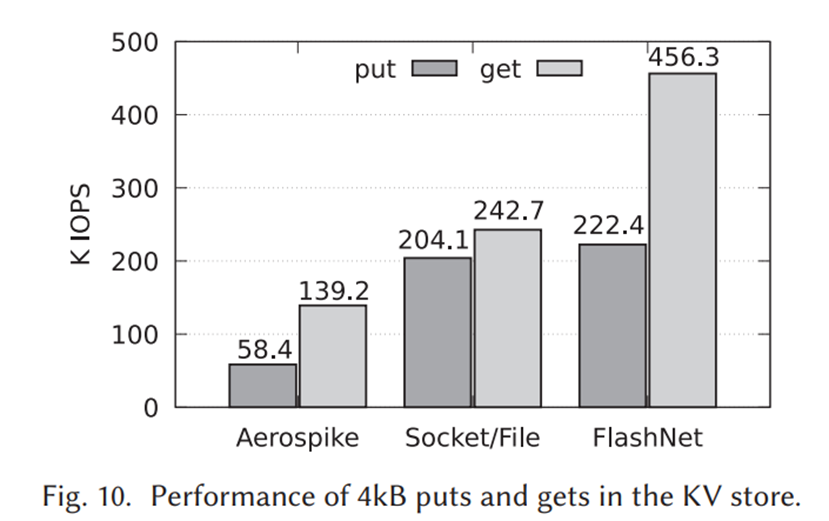
kv-store의 애플리케이션 레벨 성능 측정이다. Aerospike와 비교하여도 플래시넷이 더 우수하며, 실험을 위해 캐시를 비우고 실험했다.
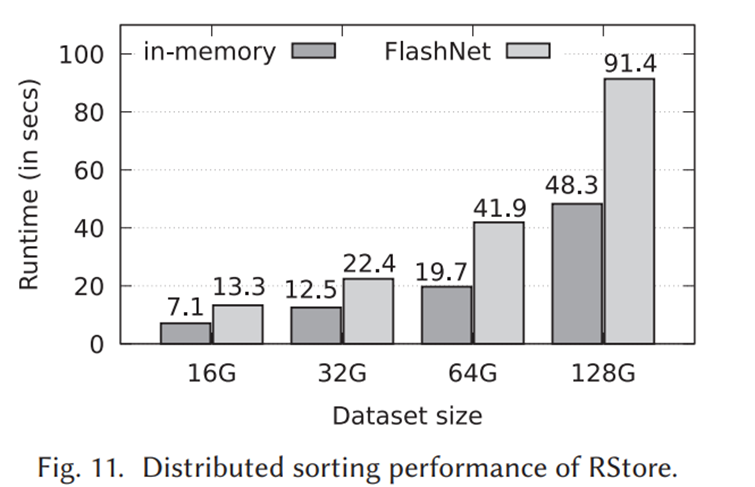
런타임을 비교했을 때, 플래시넷이 더 길다. 이러한 이유는 플래시넷은 디스크I/O 기반이고, 비교군은 메모리I/O이기 때문이다. 오히려 예상한 디스크 I/O 시간은 50초인 반면 실제 증가한 시간은 43초이기 때문에 플래시넷의 연산 오버헤드는 거의 없다라고 주장한다.
