논문 리뷰
1.Tokenizer Choice For LLM Training: Negligible or Crucial? 리뷰
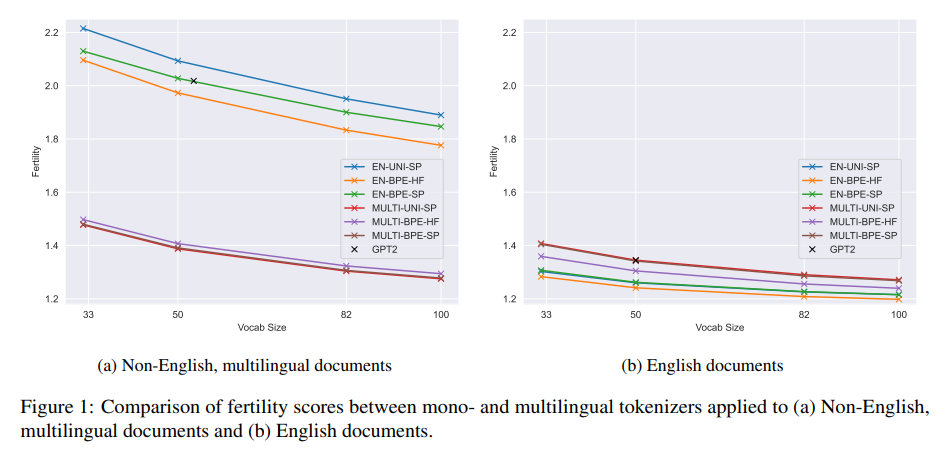
대규모 언어 모델(LLMs)의 성공은 학습 데이터셋 구성 관리와 모델 아키텍처 및 데이터셋 크기의 확장, 그리고 사전 학습 목표의 발전으로 인해 이루어졌다.그러나 우리가 간과한 부분이 존재한다. 토크나이저도 LLMs에 영향을 주지 않는다고 간과할 수는 없다. 해당 논문
2.Avoiding the 1 TB Storage Wall: Leveraging Ethereum’s DHT to Reduce Peer Storage Needs: 논문 리뷰

이더리움은 노드의 1TB 저장 한계에 도달하고 있다. 이로 인해 전체 노드를 운영할 수 있는 후보가 크게 줄어들 수 있다. 해당 논문에서는 "모든 클라이언트에 구현되어 있지만, 사용되지 않는 분산 해시 테이블을 최대한 활용하여 새로운 이더리움 동기화 및 저장 전략을 제
3.GHStore: 글로벌 해시 기반 고성능 키-값 스토어
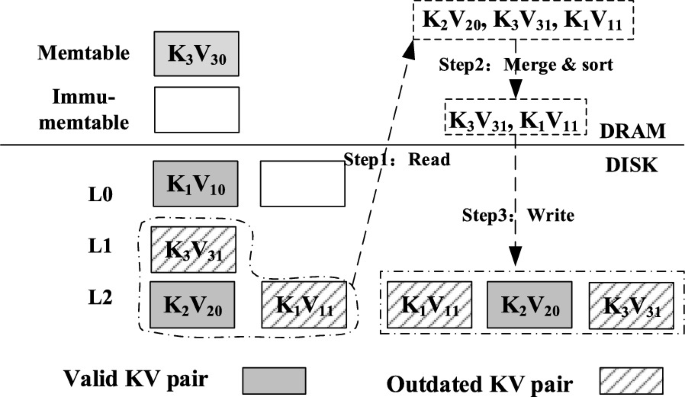
LSM 트리 키-값 저장소의 주요 데이터 구조다양한 분야에 사용된다. 분산 로컬 저장서로 자주 활용되는 모습을 보이는데, 다른 인덱싱 구조에 비해 순차적 엑세스 패턴을 유지한다는 점이다. 이러한 방식은 솔리드 스테이트 저장 장치에서 효율적이다. 솔리드 스테이트 저장
4.IceClave: A Trusted Execution Environment for In-Storage Computing 논문 리뷰
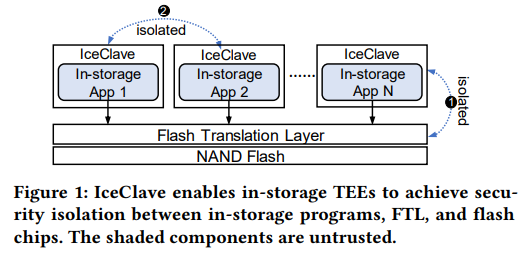
정리 원본 링크https://www.notion.so/IceClave-A-Trusted-Execution-Environment-for-In-Storage-Computing-a93d724b2f70435a9908a8326ef3bfcb?pvs=4내부 저장소 컴퓨팅은
5.논문 리뷰 : A SPACE-EFFICIENT FLASH TRANSLATION LAYER FOR COMPACTFLASH SYSTEMS

대학원 적응을 위한 논문 리뷰 포스트
6.RemoteBlock: A Scalable Blockchain Storage Framework for Ethereum 리뷰
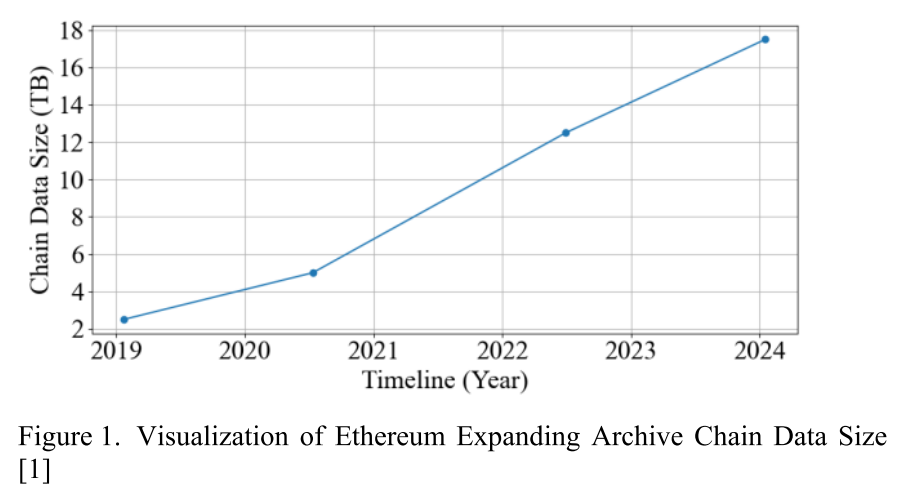
2024년 ieeexplore에 개제된 최신 논문이다. 이 논문을 블록체인 네트워크 중 이더리움을 대상으로 지속적으로 증가하는 스토리지 공간 문제에 대해서 해결하고자 한다. 기존 이더리움은 실행 노드와 합의 노드로 나뉘어져 있다. 실행 노드에서는 머클 패트리샤 트리를
7.LMPTs : 이더리움 클라이언트의 스토리지 버틀넥 개선
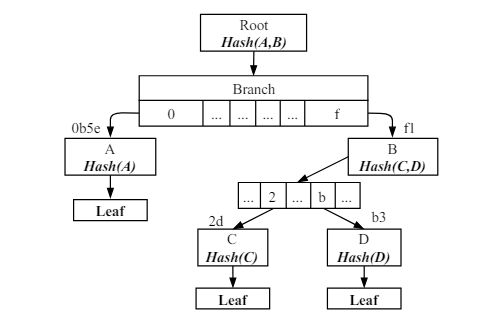
버틀넥(bottleneck)이라는 용어는 여기저기서 많이 사용된다. 컴퓨터 조립을 할 때, cpu와 gpu 사이에서도 병목 현상이 발생하고 이더리움에서도 병목 현상이 발생한다. MPT의 읽기/쓰기 작업은 트랜잭션의 TPS 속도를 받침하기 에는 느리다. 따라서 이더리움
8.A partition cover approach to tokenization 리뷰

토큰화는 문자열을 고정된 크기의 K 어휘에서 가져온 토큰으로 인코딩하는 과정이다. 현재 가장 널리 사용되는 토큰화 알고리즘은 Byte-Pair Encoding(BPE)이다. BPE는 토큰화를 압축과 병합 연산을 반복하여 수행한다. 토큰화는 LLM 아키텍처의 핵심적인 구
9.Application Managed Flash : 오픈채널 SSD의 시초

2016년 MIT와 서울대학교에서 공동연구로 진행하여 Fast'16에 발표한 논문이다.해당 논문에서 제시하는 아이디어는 현재 OCSSD, ZNS와 같은 형태를 보인다.여기서 말하는 OCSSD는 오픈채널 SSD를 의미한다. 해당 아이디어는 SSD FTL에서 처리하는 기능
10.FlashNet : Flash/Network Stack Co-Design 리뷰

위 이미지처럼 연산 노드와 스토리지 노드를 분리하는 구조는 모던 컴퓨팅에서 아주 흔한 아키텍처이다. 필요한 하드웨어만 확장하면 되는 효율적인 구조이다. 그러나 I/O 스택에서 문제가 발생한다고 한다.특히 네트워크와 디스크 I/O가 빨라질수록 커널 스택이 비효율을 초래한
11.DockerSSD: 인-스토리지 프로세싱 모델
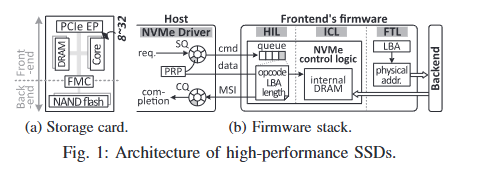
DockerSSD는 카이스트에서 2022년에 발표한 연구이다. 인-스토리지 프로세싱이라는 모델에 대한 연구이다. 인-스토리지 프로세싱은 스토리지 내에서 데이터를 처리하는 모델로 대규모 데이터셋 처리할 때 에너지 효율적인 해법으로 알려졌다. 그러나 이와 같은 시도는 저장
12.vLLM: LLM 서빙 메모리 최적화의 교과서
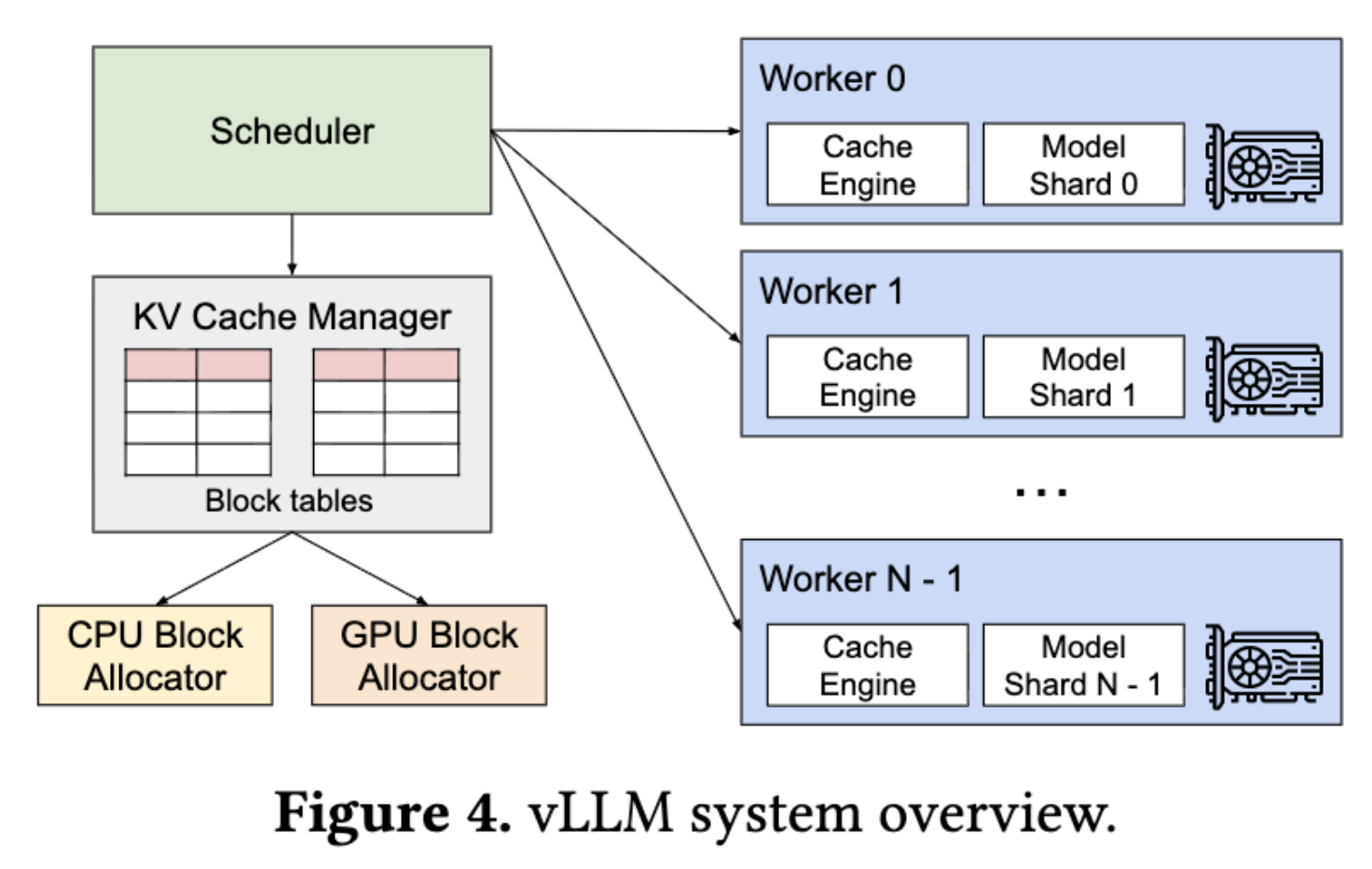
현대 컴퓨터 아키텍처에서 GPU는 가장 비싼 자원 중 하나이다. 하지만 아이러니하게도, GPU의 연산 처리량(FLOPS)은 무서운 속도로 증가하는 반면, 데이터를 담는 그릇인 GPU 메모리 용량과 대역폭은 이를 따라가지 못하고 있다.
13.GPU 메모리 부족을 해결하기 위한 오프로딩(Offloading) 기술의 진화
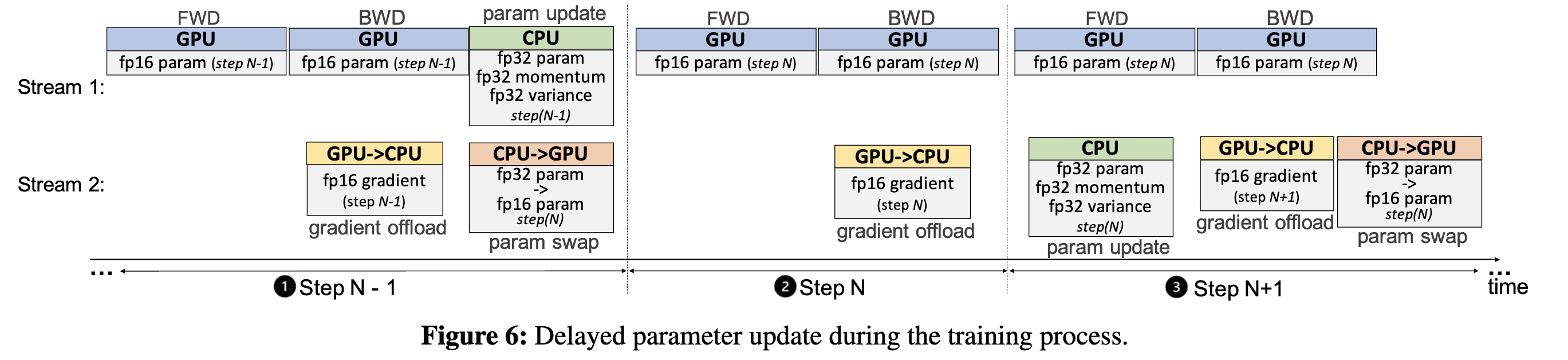
호스트 DRAM을 GPU 메모리처럼 사용할 수 없을까?