서론
대규모 언어 모델(LLMs)의 성공은 학습 데이터셋 구성 관리와 모델 아키텍처 및 데이터셋 크기의 확장, 그리고 사전 학습 목표의 발전으로 인해 이루어졌다.
그러나 우리가 간과한 부분이 존재한다. 토크나이저도 LLMs에 영향을 주지 않는다고 간과할 수는 없다.
해당 논문의 연구 결과는 토크나이저의 선택이 모델의 다운스트림 성능과 학습 비용에 큰영향을 미칠 수 있음을 보인다.
하지만 본 연구 실험중 내가 가장 중요하게 살펴볼 내용은 바로 토크나이저가 CPU 자원을 차지하는 것이다.
토크나이저
다양한 토크나이저가 존재한다. 이론적으로는 토크나이저의 성능이 모델 추론에 큰 영향을 준다고 한다. 토크나이저의 중요성과 성능이 낮은 토크나이저의 잠재적 영향에도 불구하고 본질적으로 토크나이저의 성능을 조사하는 연구하지 않았다고 한다.
현재 LLM 핵심인 디코더 전용 모델에 대한 연구가 부족하다.
검증된 토크나이저
BPE와 Unigram, 허깅페이스 토크나이저, SentencePiece 토크나이저에 대한 비교를 수행한다.
해당 논문에서는 이 4가지 토크나이저에서 대해서 신뢰성을 가진 것 같다.
직접적으로 BPE와 Unigram에 대해서는 검증되었다고 한다.
자료
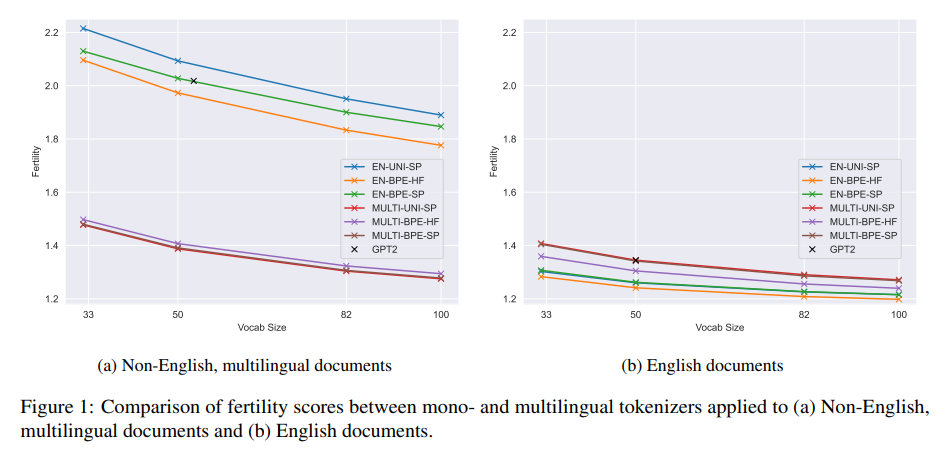
위 자료를 보면 y축 Fetility와 x축 Vocab Size가 의미하는 것은 아래와 같다.
Fetility : 효율성, 추론을 얼마나 잘하는지?
Vocab Size : 데이터셋의 단어 개수
학습하는 단어 개수가 풍부할 수록 추론을 잘하는 것은 당연하다. 그러나 다음 데이터를 살펴보면

단어 개수가 많아 질수록 연산량이 증가한다. 즉 추론 능력이 줄어도 연산량이 늘어나기 때문에 이는 상쇄 효과가 된다.
컴퓨팅 비용
더 큰 Vocab Size는 토크나이저의 추가적인 연산 비용을 발생하고 상쇄 효과가 발생하지만
50k보다 더 큰 어휘 크기에서는 더 이상 상쇄할 수 없음을 논문에서 확인할 수 있다.
이러한 문제는 오버헤드이며 해결되어야 한다.
인-스토리지 프로세싱
본 과제에서는 이러한 오버헤드를 ISP(인-스토리지-프로세싱)을 통해서 해결해보고자 한다.
