vLLM의 등장배경
현대 컴퓨터 아키텍처에서 GPU는 가장 비싼 자원 중 하나이다. 하지만 아이러니하게도, GPU의 연산 처리량(FLOPS)은 무서운 속도로 증가하는 반면, 데이터를 담는 그릇인 GPU 메모리 용량과 대역폭은 이를 따라가지 못하고 있다.
하지만 이러한 물리적 한계 상황에서, 기존의 LLM 서빙 시스템들은 귀중한 메모리를 효율적으로 사용하기는커녕 구조적으로 낭비할 수밖에 없는 방식을 고수하고 있다. 근본적인 원인은 LLM이 텍스트를 생성하는 고유한 특성인 자기회귀(Autoregressive) 프로세스와, 이를 뒷받침하지 못하는 기존 딥러닝 프레임워크의 경직된 메모리 관리 간의 충돌에 있다.
우리가 다루는 언어 모델링의 본질을 수식으로 파고들어 보면, 왜 이토록 메모리 관리가 까다로운지, 그리고 왜 기존 시스템이 필연적으로 막대한 비효율(Fragmentation)을 낳을 수밖에 없는지 그 이유가 명확해진다.
01. Problem Definition: 왜 기존 방식은 메모리를 낭비하는가?
언어 모델링의 과제는 토큰들의 리스트 에 대한 확률을 모델링하는 것이다. 언어는 자연스러운 순차적 순서(sequential ordering)를 지니고 있기 때문에, 전체 시퀀스에 대한 결합 확률(joint probability)을 조건부 확률들의 곱으로 분해하는 것이 일반적이다.
트랜스포머 기반 언어 모델의 가장 중요한 요소중 하나는 셀프-어텐션(Self-Attention) 레이어이다.
입력 은닉 상태(hidden state) 시퀀스를 라 할 때, 셀프 어텐션 레이어는 먼저 각 토큰 위치 에 대해 학습 가능한 가중치 행렬 를 통한 선형 변환(Linear Transformation)을 수행하여 쿼리(Query), 키(Key), 밸류(Value) 벡터를 생성한다.
이후, 모델은 자기회귀(Autoregressive) 속성을 유지하기 위해 번째 쿼리 벡터 와 현재 시점을 포함한 과거의 모든 키 벡터들 간의 내적(Dot-product)을 수행한다. 이 값은 차원수 로 스케일링 및 소프트맥스(Softmax) 정규화를 거쳐 어텐션 스코어(Attention Score) 가 되며, 최종적으로 이 스코어를 가중치로 하여 밸류 벡터들의 가중 합(Weighted Sum)을 계산함으로써 출력 를 도출한다
KV Cache
학습이 완료된 LLM 서비스는 일련의 입력 프롬프트 토큰 시퀀스 를 받아, 자기회귀(Autoregressive) 방식에 따라 출력 토큰 시퀀스 를 생성한다.
이 과정에서 모델은 한 번에 하나씩 새로운 토큰을 샘플링하여 생성하며, 각 단계에서 새로운 토큰을 생성하기 위해서는 현재 시점까지 생성된 모든 이전 토큰들, 구체적으로는 그들의 키(Key)와 밸류(Value) 벡터 정보가 필요하다.
매 단계마다 이전 토큰들의 키와 밸류 벡터를 다시 계산하는 것은 막대한 연산 낭비이므로, 이를 메모리에 저장해두고 재사용하는 전략을 취하는데, 이것이 바로 KV 캐시(KV Cache)이다. 여기서 주의할 점은, 동일한 단어(토큰)라 하더라도 시퀀스 내의 위치나 이전 문맥에 따라 어텐션 메커니즘에 의해 키, 밸류 벡터 값이 달라지므로, 각 요청(Request)마다 고유한 KV 캐시를 유지해야 한다는 것이다.
- 프롬프트 단계 (Prompt Phase, a.k.a Prefill)
동작: 사용자로부터 입력받은 전체 프롬프트 를 한 번에 처리하여 첫 번째 출력 토큰의 확률을 계산하고, 프롬프트 토큰들에 대한 초기 KV 캐시를 생성한다.
특성: 입력된 모든 토큰이 이미 주어져 있으므로(Known), 병렬 처리가 가능하다.
연산: 거대한 행렬 간의 곱셈인 행렬-행렬 곱셈(Matrix-Matrix Multiplication) 연산을 수행하므로, GPU의 병렬 연산 코어(Core)들을 효율적으로 활용할 수 있다. (Compute-bound)
- 자기회귀 생성 단계 (Autoregressive Generation Phase, a.k.a Decoding)
- 동작: 나머지 토큰들을 순차적으로 하나씩 생성한다. 반복(Iteration) 시점에서 모델은 직전에 생성된 토큰 하나만을 입력으로 받는다.
- 특성: 부터 위치까지의 키와 밸류 벡터는 이미 KV 캐시에 저장되어 있으므로, 새로운 토큰에 대한 키/밸류 벡터만 계산하면 된다.
- 연산: 데이터 의존성(Data Dependency)으로 인해 다음 토큰 생성을 위해 이전 단계가 완료되기를 기다려야 하므로 병렬화가 불가능하다. 이때 연산은 행렬-벡터 곱셈(Matrix-Vector Multiplication) 형태를 띤다.
- 문제점: 이 단계에서는 연산량 대비 메모리에서 데이터를 가져오는 양이 많아, GPU 연산 코어는 놀게 되고 메모리 전송을 기다리는 메모리 대역폭 제한(Memory-bound) 상태에 빠지게 된다. 이것이 단일 요청 지연 시간(Latency)의 대부분을 차지하는 주원인이다.
배칭(Batching): 연산 효율성의 핵심과 한계
LLM 서빙에서 GPU의 연산 활용도(Utilization)를 극대화하는 핵심 기술은 배칭(Batching)이다. 여러 요청을 묶어서 처리하면 거대한 모델 가중치(Weights)를 한 번만 메모리에서 로드하여 공유할 수 있다. 이로 인해 메모리 대역폭 비용이 여러 요청에 걸쳐 상각(Amortize)되며, 배치 크기가 충분히 크다면 연산 효율이 극적으로 향상된다.
하지만 LLM의 특성상, 기존의 단순한 배칭(Static Batching) 전략은 두 가지 치명적인 한계를 가진다.
요청 도착 시간의 비동기성: 요청들은 서로 다른 시간에 불규칙하게 도착한다. 단순한 배칭은 늦게 오는 요청을 기다리거나(지연), 먼저 끝난 요청이 나머지 요청이 끝날 때까지 대기해야 하므로 심각한 대기 지연(Queueing Delay)을 초래한다.
가변적인 입출력 길이: 요청마다 입력 프롬프트와 생성할 출력의 길이가 제각각이다. 기존 방식은 길이를 맞추기 위해 짧은 시퀀스에 의미 없는 값을 채우는 패딩(Padding)을 적용하는데, 이는 소중한 GPU 연산 자원과 메모리를 낭비하는 주원인이 된다.
LLM 서빙의 Memory Challenge: 거대한 KV 캐시와 단편화
세밀한(Fine-grained) 배칭 기술을 도입하여 패딩 문제를 완화하더라도, 결국 시스템의 처리량(Throughput)은 GPU 메모리 용량(Capacity), 그중에서도 KV 캐시를 저장할 공간에 의해 제한된다.
-
거대한 KV 캐시 (Large KV Cache) KV 캐시의 크기는 배칭 된 요청의 수와 시퀀스 길이에 비례하여 빠르게 증가한다. 예를 들어, 13B(130억) 파라미터 크기의 OPT 모델조차 하나의 요청을 처리하는 데 최대 1.6GB의 KV 캐시 메모리를 요구한다. 이는 수십 기가바이트의 메모리를 가진 고성능 GPU에서도 동시 처리 가능한 요청 수를 수십 개 수준으로 제한하는 병목이 된다.
-
메모리 단편화 (Fragmentation) 더 큰 문제는 기존 시스템들이 사용하는 'Chunk Pre-allocation' 방식의 비효율성이다. 출력 길이를 예측할 수 없기에 '최대 길이'만큼의 연속된 메모리를 미리 할당하는 이 방식은 세 가지 주요 메모리 낭비를 유발한다.
- 예약된 슬롯 (Reserved Slots): 미래에 생성될 토큰을 위해 미리 자리를 잡아두지만, 생성 과정 중에는 비어 있는 공간이다.
- 내부 단편화 (Internal Fragmentation): 최대 시퀀스 길이(예: 2048)에 맞춰 과도하게 할당했으나, 실제 출력이 그보다 짧아 영구적으로 사용되지 않고 버려지는 공간이다.
- 외부 단편화 (External Fragmentation): 버디 할당자(Buddy Allocator)와 같은 메모리 할당 메커니즘으로 인해, 요청과 요청 사이의 메모리 틈새가 활용되지 못하고 낭비되는 현상이다.
실험 결과, 이러한 단편화 문제로 인해 기존 시스템은 실제 유효 메모리의 약 20%~40%밖에 활용하지 못하고 있음이 밝혀졌다. 즉, 하드웨어 스펙상의 메모리는 충분하지만, 잘못된 관리 방식으로 인해 '메모리 부족(OOM)'을 겪고 있는 것이다.
02. Idea: PagedAttention
기존 LLM 서빙의 고질적인 메모리 단편화 문제를 해결하기 위해, vLLM 팀은 운영체제(OS)의 가상 메모리 관리 기법인 '페이징(Paging)'에 주목했다. 이 아이디어를 GPU 메모리 관리에 적용한 것이 바로 PagedAttention이다.
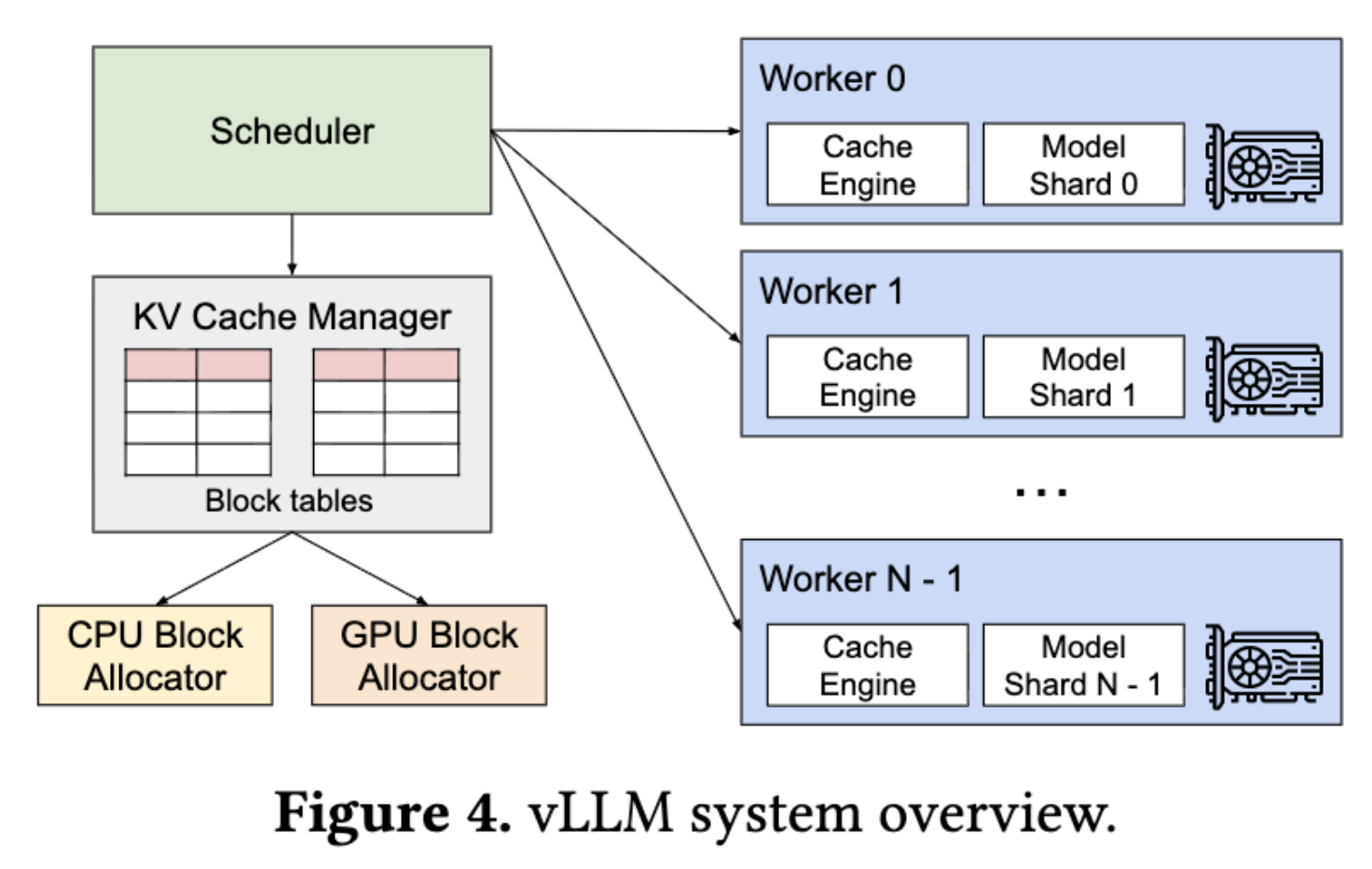
- 중앙 스케줄러 (Scheduler): 들어오는 요청들을 관리하고 교통정리를 담당
- KV 캐시 매니저: 논리적인 블록과 물리적인 GPU 메모리 주소를 매핑하는 블록 테이블(Block Table)을 관리
기존 어텐션 알고리즘은 키(Key)와 밸류(Value) 텐서가 반드시 연속된(Contiguous) 메모리 공간에 있어야만 작동했습니다. 하지만 PagedAttention은 이 제약을 깨고, 불연속적인(Non-contiguous) 메모리 공간에 데이터를 저장하고 연산하는 것을 가능하게 했다.
운영체제가 메모리를 고정된 크기의 '페이지(Page)'로 쪼개듯, PagedAttention은 KV 캐시를 고정된 크기의 KV 블록(Block)으로 분할한다.
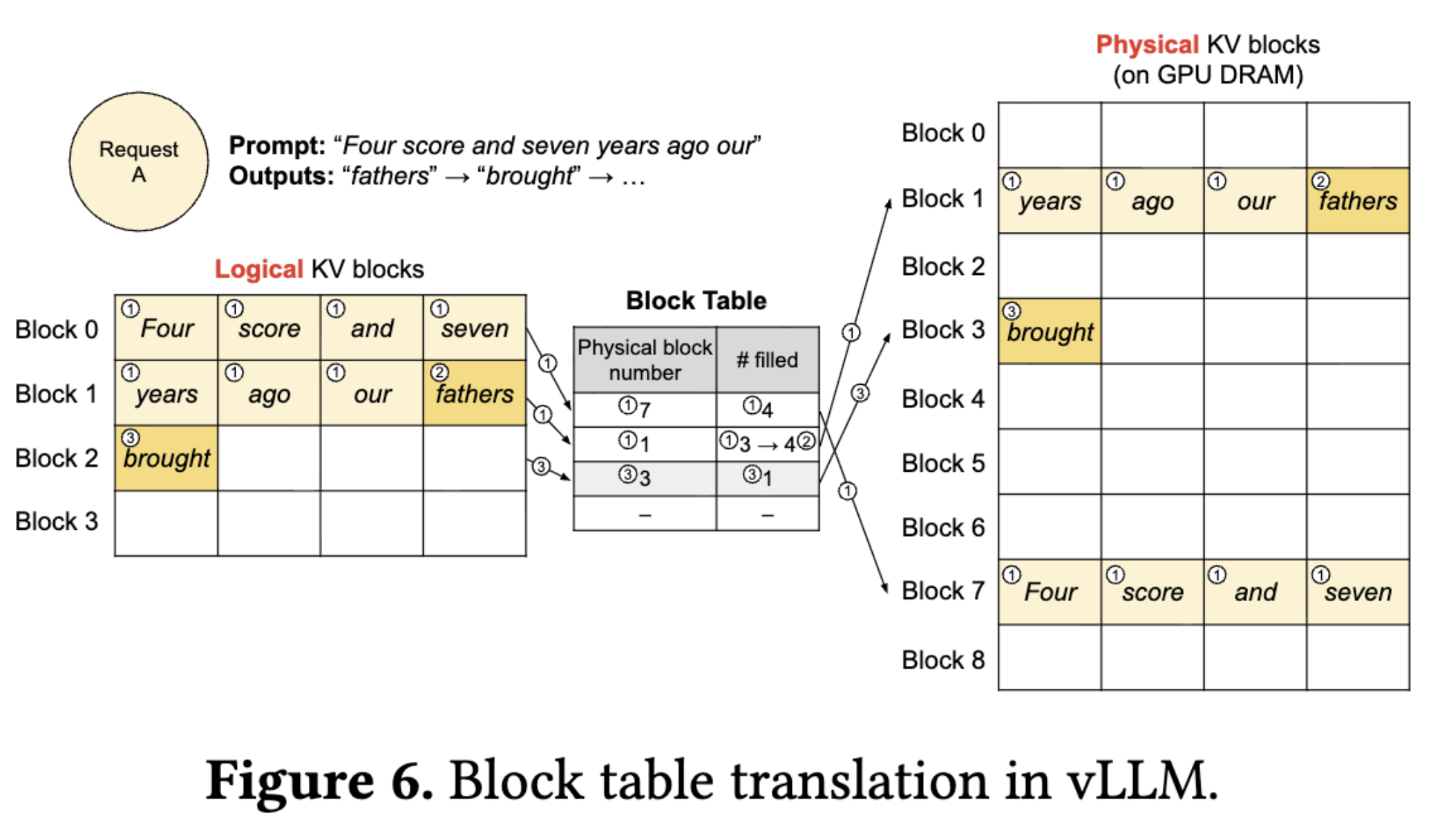
- 논리적 블록 (Logical KV blocks): 모델 입장에서 데이터는 순차적으로 보임
- 물리적 블록 (Physical KV blocks): 실제 GPU 메모리상에서는 데이터가 여기저기 흩어져 저장
- 블록 테이블 (Block Table): 이 둘 사이를 연결해 주는 지도(Map) 역할
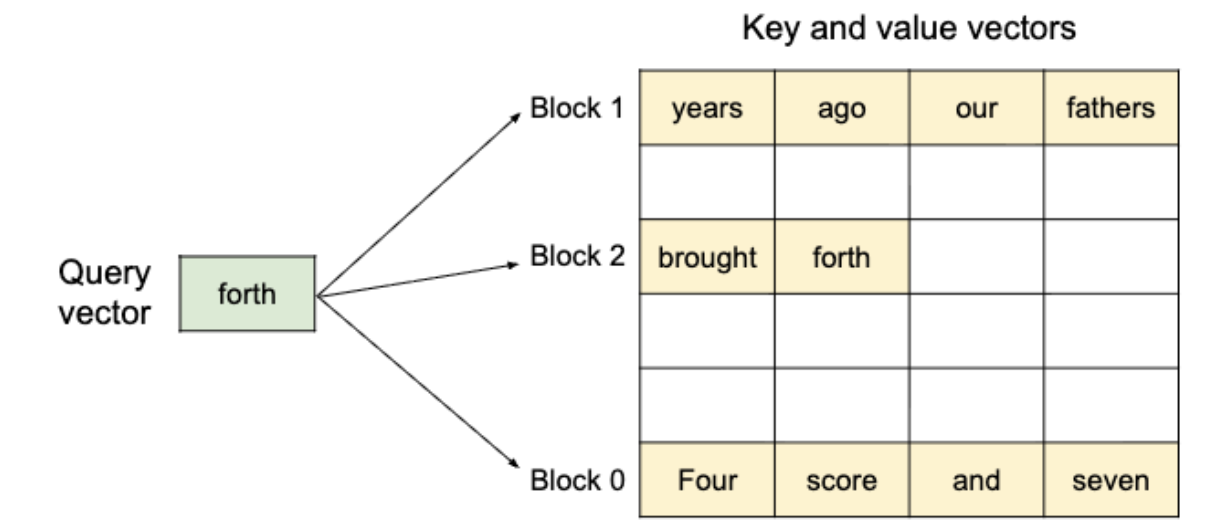
PagedAttention 커널은 전체를 한 번에 계산하는 대신, 블록 단위로 데이터를 가져와서(Fetch) 계산하고 합친다. 위 그림의 예시를 보면, 쿼리 토큰 "forth"에 대한 어텐션을 계산하는 과정은 다음과 같다.
- Block 0 Fetch: "Four score and seven"이 저장된 물리 블록을 가져와 연산함
- Block 1 Fetch: "years ago our fathers"가 저장된 저 멀리 떨어진 물리 블록을 가져와 연산
- Aggregation: 각 블록에서 계산된 부분적인 어텐션 스코어들을 합쳐 최종 결과를 도출
PagedAttention은 기존의 어텐션 수식을 다음과 같이 블록 단위 연산(Block-wise computation)으로 재정의한다
- (블록 단위 벡터): 기존 수식의 가 전체 시퀀스의 거대한 행렬이었다면, 여기서 는 번째 물리적 블록에 저장된 토큰들만의 키/밸류 묶음을 의미함
- (블록 개수만큼 반복): 시그마()의 범위가 부터 (전체 토큰 개수)가 아니라, (현재까지 생성된 블록의 개수)로 바뀐 점이 핵심이다. 즉, 커널은 전체 메모리를 훑는 게 아니라, 블록 테이블을 참조하여 흩어져 있는 개의 블록만 순차적으로 가져와(Fetch) 계산
- 메모리 저장 방식만 물리적으로 흩어놓았을 뿐, 수학적으로 계산된 결과값()은 기존 어텐션과 완전히 동일하다. 즉, 정확도 손실 없이 메모리 효율성만 극대화됨
03. Implementation
vLLM 엔진은 약 8,500줄의 Python 코드와 2,000줄의 C++/CUDA 코드로 작성되었다. 스케줄러(Scheduler)와 블록 매니저(Block Manager)를 포함한 제어 관련 컴포넌트들은 Python으로 개발하였으며, PagedAttention과 같은 핵심 연산을 위해서는 커스텀 CUDA 커널을 개발했다.
04. Evaluation
- 실험 환경 (Experimental Setup)
모델: OPT (13B, 66B, 175B), LLaMA (13B)
하드웨어: NVIDIA A100 GPU
워크로드: ShareGPT (긴 입출력), Alpaca (짧은 입출력). 요청 도착 시간은 포아송 분포(Poisson Distribution)를 따름.
베이스라인 (Baseline):
- FasterTransformer: 레이턴시(Latency) 최적화 엔진.
- Orca: 처리량(Throughput) 최적화 시스템 (공개되지 않아 자체 구현).
- 주요 지표: 높은 요청률(Request Rate) 하에서도 정규화된 지연 시간(Normalized Latency)을 낮게 유지하며 처리량(Throughput)을 극대화할 수 있는지를 측정한다.
- 주요 실험 결과
-
기본 샘플링 (Basic Sampling): ShareGPT 데이터셋에서 vLLM은 Orca(Oracle) 대비 1.7~2.7배, Orca(Max) 대비 2.7~8배 더 높은 요청률을 처리하면서도 비슷한 수준의 지연 시간을 유지했다. 이는 메모리 낭비를 줄여 더 많은 배치를 동시에 처리했기 때문이다.
-
병렬 샘플링 및 빔 서치 (Parallel Sampling & Beam Search): PagedAttention의 메모리 공유(Memory Sharing) 효과가 극대화되는 지점이다. 프롬프트의 KV 캐시를 여러 시퀀스가 공유함으로써 메모리 사용량을 획기적으로 줄였고, 그 결과 Orca 대비 더욱 큰 성능 격차를 보였다.
-
공유 프리픽스 (Shared Prefix): 번역 태스크와 같이 예시(Few-shot examples)가 포함된 긴 프리픽스를 여러 요청이 공유하는 경우, vLLM은 Orca 대비 1.67배에서 최대 3.58배 높은 처리량을 달성했다.
-
챗봇 (Chatbot): 긴 대화 기록(History)을 매번 프롬프트로 처리해야 하는 시나리오에서, vLLM은 메모리 단편화 문제를 해결함으로써 Orca 대비 2배 높은 요청률을 안정적으로 유지했다.
- 어블레이션 연구 (Ablation Studies)
-
커널 오버헤드 vs 시스템 이득: PagedAttention은 블록 테이블 조회(Look-up) 등의 과정으로 인해, 최적화된 FasterTransformer 커널보다 약 20~26% 느린 커널 레이턴시를 보였다. 하지만 어텐션 연산은 전체 모델 연산의 일부일 뿐이며, 향상된 메모리 관리로 배치 크기를 키움으로써 엔드-투-엔드(End-to-End) 처리량에서는 압도적인 성능을 달성했다.
-
블록 크기의 영향: 실험 결과, 블록 크기 16이 GPU 병렬성 활용도와 메모리 단편화 사이의 최적점(Sweet Spot)으로 나타나 vLLM의 기본값으로 채택되었다.
05. Discussion
다른 GPU 워크로드 적용 가능성
vLLM의 접근 방식이 모든 GPU 작업에 만능은 아니다.
-
Effective: LLM 서빙처럼 출력 길이를 예측할 수 없어(Unknown Output Length) 동적 할당이 필수적이고, 성능이 GPU 메모리 용량(Memory Capacity)에 의해 제한되는 'Memory-bound' 작업에서 강력하다.
-
Ineffective: DNN 학습(Training)이나 일반적인 CNN 서빙처럼 연산 속도가 병목(Compute-bound)이거나 텐서 크기가 정적인 경우에는, 페이징의 오버헤드로 인해 오히려 성능이 저하될 수 있다.
LLM 특화 페이징 최적화 (LLM-Specific Optimization)
vLLM은 OS의 페이징 기법을 기계적으로 차용한 것이 아니라, LLM의 특성에 맞춰 재해석했다.
-
All-or-Nothing 스왑: 요청 처리를 위해선 시퀀스의 모든 토큰 데이터가 필요하므로, 스왑 시 페이지 단위가 아닌 시퀀스 전체를 이동시킨다.
-
재연산 (Recomputation): 스왑 아웃된 데이터를 디스크에서 읽어오는 대신, GPU 연산으로 다시 계산하는 것이 더 빠를 경우를 고려해 복구 전략을 다양화했다.
-
커널 융합 (Kernel Fusion): 메모리 접근과 어텐션 연산을 하나의 커널로 합쳐 오버헤드를 최소화했다.
관련 연구와의 비교 (Related Work)
일반 모델 서빙 (Clipper, TF Serving): 배칭과 스케줄링을 다루지만, LLM 고유의 자기회귀적 특성과 KV 캐시 상태 관리를 고려하지 않아 최적화에 한계가 있다.
트랜스포머 특화 서빙 (FasterTransformer, Orca):
-
FasterTransformer: 레이턴시 단축에 집중했다.
-
Orca: 처리량 증대에 집중한 모델로 vLLM의 가장 강력한 비교 대상이다.
-
Orca vs vLLM (상호보완적 관계): Orca가 '스케줄링'을 통해 빈틈을 채웠다면, vLLM은 '메모리 관리'를 통해 공간을 확보했다. vLLM은 메모리 파편화를 제거하여 Orca보다 2~4배 높은 성능을 냈다. 특히, 메모리 관리가 효율적일수록 스케줄링 난이도도 낮아지므로 두 기술은 상호 보완적이다.
메모리 최적화 연구 (FlexGen, FlashAttention):
-
FlexGen: 오프라인 추론을 위한 스와핑에 집중하여, 실시간성이 중요한 온라인 서빙에는 부적합하다.
-
FlashAttention: 연산 자체의 메모리 사용량을 줄였으나, vLLM처럼 시스템 레벨의 블록 단위 메모리 관리를 제안하지는 않았다.
