CHAI: A CHatbot AI for Task-Oriented Dialogue with Offline Reinforcement Learning
action space를 product id + attribute로 정의할 때 language model이 만들어내는 product가 이미 존재하는 목록들에 bounded 되도록 하는법? ( n개의 action을 generation 하는 과정에서 이미 있는 item 에 bounded 하게 만드는 과정이 까다로움.. )
- item list를 prompt에 모두 포함하기는 너무 긺
- reason 에 기반한 query 및 retrieval 과정..?
action space를 token 단위로 가져갈 때는 비교적 쉬움
- 만약 token 단위로 간다고 하면 결국 아이템 attribute 가 주어진 최종적인 Q 값 합을 도출할 수 있으므로 BERT4REC 처럼 1개 참 + 100개 거짓 상품 주고 Q 값 비교해서 HR@10, 20 등 비교
Intro
주로 goal 이 있는 dialogue 는 human interaction data로 imitation learning으로 훈련함
dialog를 control 문제로 보면 RL framework를 사용해 task goal로 향하는 대화를 optimize 할 수 있다.
Related work
이전 논문들과의 차이점은 pre-trained LLM을 사용하므로서 large amount 의 unsupervised data를 leverage 한다는 것이다. (conversation 형태의 curated data를 offline RL로 leverage)
Negotiation task
두 유저가 buyer/seller 역할을 하며 나눴던 dialogue를 바탕으로 dataset 구성
- buyer, seller 는 4가지 response type을 가짐
- message : 한 유저가 다른 유저에게 utterance를 전송
- offer : 한 player가 거래를 성사시키기 위한 가격을 제시
- accpet, reject : offer가 진행된 이후 취할 수 있는 행동
- reward는 거래 가격에 기반해서 형성
- reject 당하면 -20 을 받기 때문에 거래를 성사시키는 방향으로 훈렫뇜
- 성공하면 price에 비례하는 normalized reward를 받음
RL setup
agent 가 seller position 에서 역할을 수행한다.
(우리의 경우에는 추천 해주는 position을 수행하게 될 것)
env가 buyer 역할을 진행
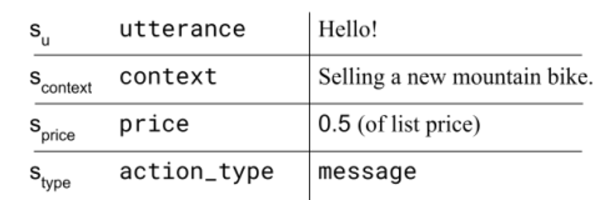
state, action space는 다음과 같이 정의됨
[state]
[action]
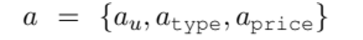
- a_u, s_u 같은 경우 utterance를 의미 (각각 agent, env 가 생성한)
- a_type, s_type은 각각 위에서 설명한 네 가지 행동들 중 하나를 의미
buyer == env 인 환경에서
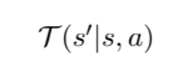
env가 나타내는 reponse에 대한 distribution을 나타냄
Method
GPT-2를 task-specific 한 dialogue에 fine tuning 시킨다.
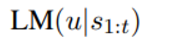
- dialogue history 가 s1:t 처럼 나타나 있을 때 LLM이 utterance에 대해 가지는 distribution을 위와 같이 표현한다.
- LM 자체는 task에 대해 concept 이 없는 상태이기 때문에 offline RL에서 Q 함수를 이용해 LM이 task-specific 한 goal을 향해 갈 수 있도록 훈련하는 셈
Q function 훈련
세가지 다른 방식의 offline training 방법을 소개
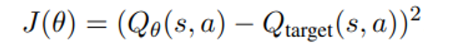
이 objective를 최소화 시키려는데 offline learning에서 Q_target이 보지 못한 ood action에 대한 잘못된 estimation 문제가 있으므로 세가지 방법으로 Q_target을 설정
