OFFLINE RL FOR NATURAL LANGUAGE GENERATION WITH IMPLICIT LANGUAGE Q LEARNING
Intro
LLM 은 user-specified utility에 최적화 되어 있지는 않다
RL 은 reward model이 정의되어 있는 한 user specified task에 적합하지만 on-line learning의 경우 human interaction이 비싸기 때문에 한계 존재
- leverage existing data == (offline) 방식을 사용해서 이를 극복
offline 은 흔히 BC 와 비교되는데 temporally compositional 하다는 점에서 차이가 존재
- 이는 여러 trajectory에서 부분적으로 optimal한 trajectory를 이어붙이는 추상적인 개념을 의미한다.
- BC 는 존재하는 trajectory 의 평균 정도 성능(optimality)이 예상되지만 offline RL은 temporal compositional 한 성질로 인해 expert 하지 않은 dataset에서도 좋은 성능이 기대된다.
제시된 ILQL
- 토큰 단위로 Q 와 V 값을 예측한다
- training 과정에서 V를 Q의 upper expectile에 맞추는 방향으로 훈련된다.
Related work
Offline RL은 환경↔ 유저의 interaction 요구 한계를 극복한다.
내가 고민하던 부분
prior work은 per-utterance 단위로 agent(LLM)의 action을 정의했다.
- CHAI: A CHatbot AI for Task-Oriented Dialogue with Offline Reinforcement Learning
→ 이러한 방식은 training에서 decoding overload를 야기한다.
이 논문은 per-token 방식으로 action을 처리하며 fully self-contained 방식을 사용하기 때문에 training time에 generation을 simulate 할 필요가 없다고 주장
→ 언급된 self-contained 방법에 대해서는 더 봐야할듯 (어떻게 한지 모르겠음)
preliminaries
POMDP 로 정의
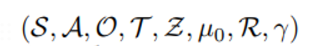
observation은 history of token 으로 정의됨
Action space는 단어 집합에서 올 수 있는 token 집합으로 정의됨
quick IQL 요약
흔히 offline RL 에서 사용하는 TD error 는
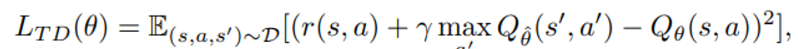
위 수식의 문제는 behavior policy에서 보지 못한 a’에 대한 over-estimation이므로
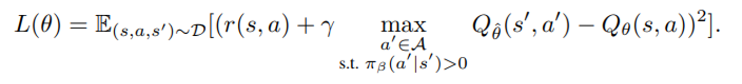
위와 같이 behavior policy에서 관측 가능한 Q를 최대로 하는 action에 대한 조건식을 최소화 하는 것을 목표로 한다.
expectile loss 개념을 가져온다
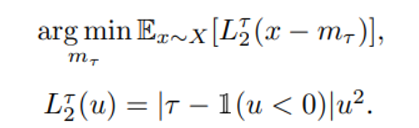
위와 같은 setting에서
-
tau가 0.5 보다 큰 경우 x-m < 0 인 경우 loss에 기여하는 비율이 낮아지고 x-m > 0 인 경우 loss에 기여하는 비율이 커진다.
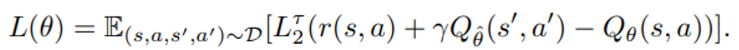
그래서 이와 같은 expectile loss를 소개 -
단점) s’ ~ p(.|s,a) 인 state transition 이 stochastic 하다는 점
→ 이는 큰 target value (r + gamma*Q) 값을 가질 수 있는 유일한 a 가 아닌 운좋게 이 값을 기록한 a를 나타낼 것이다. → 이러한 문제를 해결하기 위해 action distribution을 염두에 둔 value network 예측을 도입 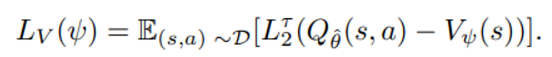참고) 실험에서 tau를 1에 가깝게 사용하는데 그러면 V는 Q보다 작을 때 더 큰 reward를 받으므로 Q의 큰 값 쪽으로 예측하도록 훈련된다.
이렇게 Q를 예측하기 위해 훈련된 value function은
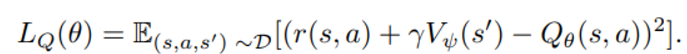
target value로써의 역할을 수행할 수 있음
하지만 이렇게 훈련된 policy는 optimal Q의 직접 대응이 아니므로 extraction 과정이 필요하다 (why?)
AWR(advantage weighted regression)
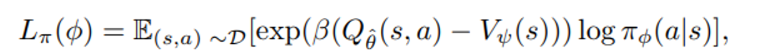
prior work 에 따르면 위의 식은 distribution constraint에서 Q 값을 최대화 하는 policy를 배울 수 있다고 한다.
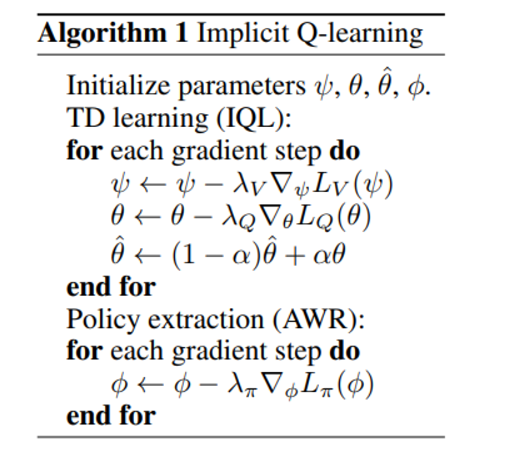
최종 알고리즘은 다음과 같음
다시 ILQL
IQL 에서 modification 사항
- sequence model 과 integrate
- 별도의 actor를 훈련시키지 않고 (AWR 안함?) value function을 이용해 behavior policy를 직접 perturb (stability 측면에서 향상)
- Q 함수에 conservatism항 추가
Method
IQL loss 항이 두개 합쳐진 loss를 사용한다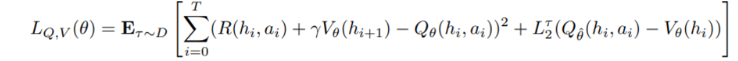
Q, V 가 parameter를 공유하고 이로 인해 loss 합치기 진행
[policy extraction]
IQL 에서는 AWR로 policy extraction 과정을 거쳤는데 여기서는 그러지 않는다.
gradient update를 통해 별도의 policy를 생성하는 대신 그냥 바로 훈련된 Q,V 값을 이용해 sample을 생성하도록 한다.
즉, behavior policy를 모방하기 위해 supervised 방식으로 훈련된 모델에 Q(h,a) - V(h) 의 advantage를 더해 나오는 결과를 사용한다. (advantage 더하고 다시 softmax)

여기까지 했을 때 문제
supervised로 훈련된 behavior policy가 모든 token에 대해 over-smoothed 된 경우 unlikely token에 대해 잘못된 Q, V가 예측될 수 있음
이를 막기 위해 CQL 에서 제안된 OOD Q 값을 push down 하는 loss term을 IQL 의 합쳐진 loss 항에 추가해 최종적인 loss를 제안한다.
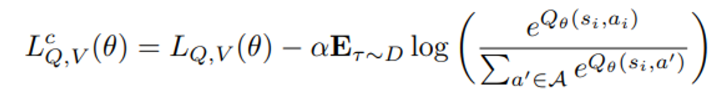
detail
GPT2-small 을 사용하고 value function 은 3개의 mlp-head 사용
- 2개의 Q, 한 개의 V head
- embedding dimension 의 두 배짜리 hidden dimension 사용
- 두 개의 Q head 중 작은 값을 Q 값으로 설정
Experiment
reddit comment 실험이 가장 적합해 보임
→ 근데 또 왔다 갔다하는 high level squential 성질이 부족해보임
dataset 특징
- text 가 diverse
- reward가 stochastic : 주관적인 human 판단에 의존하므로
- 4 million Reddit comment, agent에게는 윗 댓글이나 포스트 내용이 주어짐
- agent는 ‘toxicity’, ‘upvotes real’ 항목 중 하나에 부합하는 댓글을 생성하도록 훈련됨
- ‘toxicity’의 경우 경도에 따라 -10, -5, 0 으로 보상을 부여
- 이 reward는 openai api 를 이용 (toxicity 판단해주는 모델이 있음)
- ‘upvotes’ 항목은 양수의 추천을 받으면 10, 아니면 0 점을 부여함
RoBERT-a model에 대해 해당 댓글이 upvote 일지 아닐지 예측훈련을 시킴
- ‘upvotes real’ 은 agent를 ground truth reward를 바탕으로 훈련
- ‘upvote model’은 agent를 위의 model이 만든 reward를 바탕으로 훈련
- 이 모델은 RoBERTa에 mlp head를 추가해서 cross entropy 방식으로 훈련시킴
visual dialogue dataset
- 원래 의도와는 달리 agent가 question 물어보는 방향으로 훈련
- reward는 agent가 ground-truth 이미지를 잘 예측할 수 있는지 기반으로 제공
- 선행연구로 훈련된 모델을 evalautions simulator로 사용
- agent가 natural language 영역에서만 활동할 수 있도록 image embedding을 reward function의 일부로 생각
특징) temporal compositionality : 어떤 질문에 대한 답이 새로운 질문을 유도할 수 있음
reward
- ground truth 예측하지 못하면 -1(매턴마다), 다른 경우 reward 0 + env 종료
- y/n reward는 상대 답변이 yes 이나 no 형태로 나오는 경우 -2를 받음
- conservative y/n 는 yes/no를 돌려 말한 값도 -2 의 값을 부여
