abtract
최근 논문은 offline RL을 transformer 구조를 이용해 sequential modeling task로 보고 성능 증가를 이룬바 있다.
→ 이러한 방식은 convergence 속도에 한계가 분명히 존재한다 (scratch로 시작할 경우)
이 논문에서는 vision 및 language domain 에서 pre-trained된 모델을 offline RL fine tuning 할 경우 transferability 에 대해 살펴본다.
또한 vision, language ↔ RL 사이 transfer을 잘하기 위한 방식도 제안한다.
sota 성능 도달에 3~6배 절약된 훈련 시간을 보여준다.
Wikipedia-pretrained + GPT2 model
Introduction
offline RL은 sequence modeling 과 유사한 것으로 여겨짐
→ return 이 추가(augmented)된 trajectory를 fit 하는 supervised learning task로 생각
이 논문에서는 pre-trained laguage model 이 offline RL (language 와 전혀 성관없는) 의 initializing weight로 작용할 수 있는지 탐구
더 나아가 positional embedding 에 대한 extension + embedding similarity 극대화를 통해 pre-trained language model 의 feature를 적극 활용
Decision Transformer에 비해 Gym, Atari offline benchmark에서 더 좋은 성능
3. Methodology
3.1 modeling
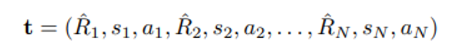
trajectory 는 위와 같이 모델링하며 R_i 는 returns to go 로 r_t 를 (t=i~N) 까지 합한 것
(Decision Transformer 같이)
3.2 Techniques
laguage representation과 offline RL representation의 similarity를 증가시키는 법
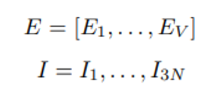
E 는 V 크기의 vocab size를 가진 laguage embedding, I 는 Linear projection을 통과한 (r,s,a) 의 결과
이 둘을 align 시키기 위해 cosine similarity를 최소화 시키며 loss function은 아래와 같다.
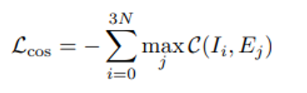
각 (r,s,a) projection 에 대해 cosine distance를 최대로 만드는 단어 emedding 의 합을 최소화 시키는 방향
하지만 단어 집합이 너무 크기 때문에 K-means clustering 을 사용해 K로 사이즈를 줄이고 cluster center를 원래 embedding 값으로 생각
Laguage model co-training
laguage modeling 과 trajectory modeling을 joint 하게 훈련시키는 것도 실험했다.
이렇게 하면 Transformer 구조가 language와 trajectory를 simultaneous 하게 handle 할 수 있기 때문
Final objective
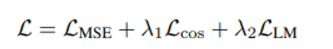
첫항 : offline trajectory modeling objective
둘째항 : cosine similarity btw 단어 & trajectory
셋째항 : LM 원래 objective
- Experiment
현재 이해
gpt2-small로 laguage only pretraining 성능 확인
ChibiT 라는 모델로 DT 와 비교(parameter 수 맞춤)
→ 이 모델은 Wikitext-103 과 offline RL 동시 훈련한 것으로 생각됨
이미지 pre-trained 모델에 대해서도 했으나 이부분은 관심 없음..
RL baseline
DT, CQL, TD3 + BC 등…
