Generating Multiple-Length Summaries via Reinforcement Learning for Unsupervised Sentence Summarization
Intro
초기 모델은 abstractive summarization 방식을 사용(vocab set에서 word를 generate 한다)
이러한 방식은 unsupervised 방식으로 요약을 학습하기 위해 autoencoder를 도입했다
extractive model 은 word combination을 찾아내 요약을 만들어낸다.
최근 extractive model 이 abstractive model 보다 좋은 성능을 내고 있다
이러한 추세지만 논문에서는 inherent downside를 지적
- text에 존재하는 단어로만 요약본을 만들기 때문에 효과적인 요약을 위한 새로운 단어를 사용하지 않는다는 한계
- abstractive 모델은 하지만 간단한 baseline 보다 낮은 성능을 보인다는 단점이 있는데 이를 해결하기 위해 RL 을 도입한다
모델이 고려하는 점
1) 형성된 요약본과 원래 input과의 semantic 유사도 (요약본이 input text 의 core content를 포함하도록 하기 위한 좋은 방법)
2) 형성된 요약본의 fluency
직관적으로 짧은 요약본을 생성하는 것이 더 어려움.
논문에서는 여러 길이의 요약본을 생성하도록 하고 이들이 서로 mutually 개선하게 만든다.
- 요약본을 만들기 쉬운 길이로 먼저 생성한 이후 이의 도움을 받아 만들기 어려운 길이의 요약본을 생성한다
RL 훈련을 위한 pretraining task를 고안했다
- input text에 word-level perturbation과 length prompt 를 주입
- target text 앞에 이런 식으로(’8: ’) 의도한 요약본의 길이를 나타낸다.
- 모델이 augmented input으로부터 reconstruct 하도록 훈련 (이 과정에서 summarize와 output length control 이 가능? )
Related work
이 논문에서 RL을 사용하는 목적
1) input text와 요약본 사이의 semantic similarity를 잡아내기 위해
2) 요약본의 길이를 조절할 수 있는 능력
3) model agnostic RL framework (모델에 구애받지 않는다? 무슨 모델? )
요약을 위한 pre training task
사전 논문들은 long-document 요약을 위한 pre training 과정을 소개하지만 이 논문은 sentence 요약이기 때문에 이에 특화된 방식을 제공한다.
Method
notation
변환하고자 하는 long sentence
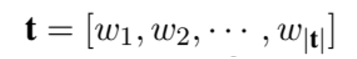
요약된 short summary
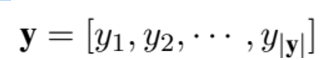
text와 요약본 쌍은 훈련시 제공되지 않는다는 점 참고
<강화학습 프레임워크>
ground truth 가 존재하지 않기 때문에 summary 의 quality에 기반해 generator를 훈련시킨다
Generation 과정은 word-sampling 과정을 필요로 하는데 이는 미분 불가능하다
→ RL을 이용해 이러한 미분 불가능성을 타파한다.
[state] : 들어간 인풋을 t, 생성된 요약본을 y_t 라고 했을 때 상태는 아래와 같이 표현된다.
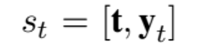
[action] : vocab set에서 다음에 올 단어를 선택
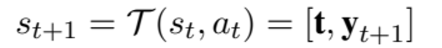
위와 같은 transition function 이 완성됨
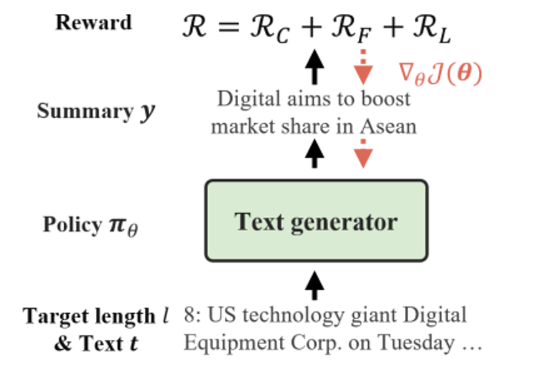
[reward]
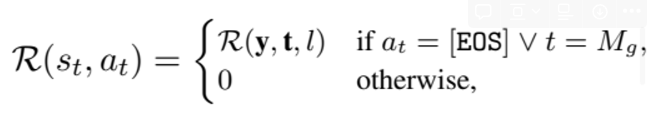
선택한 단어가 eos 이거나 요약본이 지정한 길이에 도달했을 때 reward를 주고 나머지 경우에는 0
세부적으로는 아래와 같이 세분화됨
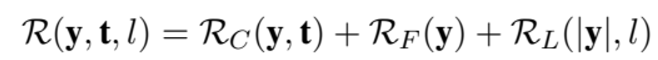
1) R_c 는 요약본과 원본의 semantic 유사도에 점수를 주는 항목 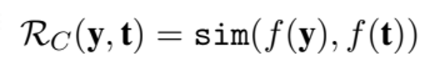
f는 BERT와 같이 text를 embedding 할 수 있는 function 이고 sim 은 cosine similarity를 사용했다
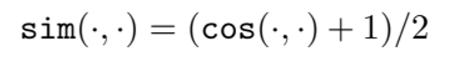
2) R_F 는 유창함에 점수를 주는 항목으로 문법의 정확도와 자연스러움을 점수로 매긴다 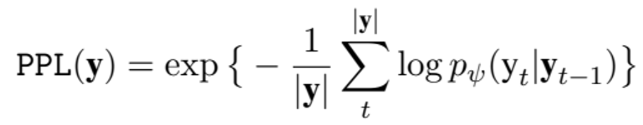
perplexity라는 NLP 에서 사용되는 지표로 낮을수록 유창함을 나타낸다.
삼지창은 언어 모델의 network parameter를 의미하며 chain rule 이 적용되어 y_t-1를 condition 으로 갖는다.
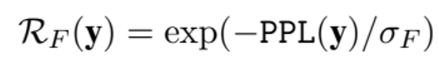
이에 따라 R_f는 위와 같이 주어진다.
3) 마지막은 의도한 길이를 맞췄을 때 가중적인 점수를 주는 항이다.
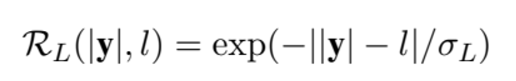
policy gradient
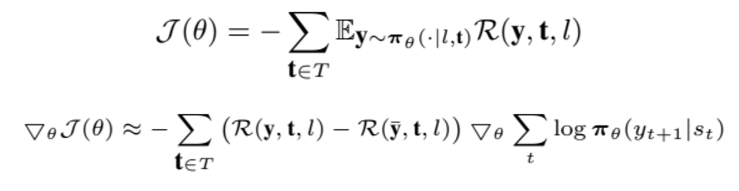
Multi summary learning
key idea: 비교적 만들기 쉬운 high quality summary로 만들기 어려운 low quality summary를 개선
l 을 요약본 길이가 집합 L 에서 하나씩 뽑는다고 생각했을 때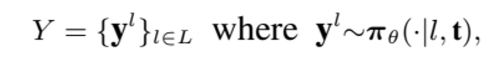
y를 제외한 다른 요약본들을 y’ 이라 했을 때 다음과 같이 쓸 수 있다.

R_q는 l 길이의 요약본이 받는 reward라고 생각하면 된다.
R_c는 앞서 설명한 것과 같이 semantic 유사도에 대한 reward이고 lambda 는 weight 계수, u는 summary y’이 y를 만들때 줄 수 있는 usefulness를 평가하는 함수이다.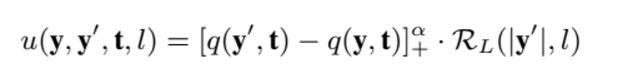
첫번째 항은 quality 함수에 의해 y’ 이 y 보다 의미있는 summary 일때만 기여하게 된다.
기호는 scaling factor alpha 와 max(., 0) 을 적용하는 것을 의미한다.
요약본의 길이가 비슷할수록 좋은 영향을 줄 것이므로 R_L 항을 곱해 usefulness 를 나타낸다.
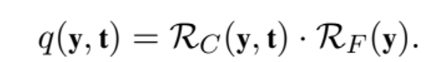
quality 함수는 유사도를 의미하는 R_c와 유창함을 의미하는 R_f 의 곱으로 표현된다.
전체 훈련을 위한 reward는 따라서 아래와 같이 주어진다.
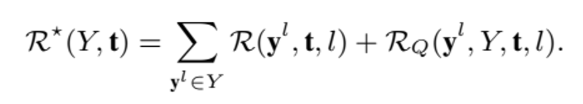
pretraining task
perturbation을 가하고 prompt 를 추가해 단어들을 (reorder, add, remove) 하는 방식과 원하는 길이만큼 생성하는 능력을 갖춘다.

