Towards mental time travel: a hierarchical memory for reinforcement learning agents
Abstract
[RL 의 메모리 관점 한계]
1) past event detail 기억 못함
2) distractor task 가 존재할 경우 single timestep 도 기억못함
[HCAM 특징]
1) chunk 로 기억을 묶은다음 이를 꺼내올 때 chunk를 대상으로 coarse attention을 시행함
2) 1)에서 선택된 chunk에 대해서만 detailed attention을 시행한다
[세가지 측면에서 잘함]
1) long-term recall
2) retention (보유, 유지)
3) reasoning over memory
Introduction
사람의 기억 저장 방식에서 아이디어를 얻어 대략적인 기억에서 세부사항들을 뽑아내는 방식을 RL에 적용하고자 했다
주의) 새로운 내용을 배워야 하는 task가 주어졌을 경우 과거에 배웠던 기억들을 잊어버리면 안된다!
[선행연구들]
1) meta learning 측면 - 다음 task를 수행하려는 경우 이전에 배운 것들을 서서히 잊어버린다
2) LSTM, Transforemer - short task 에서 기억할 수 있다 but, detailed recall 에 취약하다
의외의 점 ) Transformer 기법은 long range 라면 supervised task에서도 유용하지 않다
[원인분석]
1) single timestep 보다 memory chunk 가 짧아서 불러올때 정보를 포함하지 못한다
2) sparsity of attention : 다른 event 들 없이는 specific event detail을 불러오지 못한다는 한계 → 이러한 점은 새로운 task가 주어졌을 경우 대처하는 능력도 떨어뜨린다
[HCAM 의 장점]
1) long-term 측면에서 볼 때 : coarse chunk로 long-term을 커버할 수 있다
2) short-term 측면에서 : transformer 의 short-term sequential and reasoning power를 누릴 수 있다
[HCAM 결과]
1) maintain and recall memory over 5x more distractors (훈련 때에 비교해서 5배 커버가능)
2) 새로운 환경을 만났을 때 기존의 memory를 사용해 near optimal 성능 도출가능
3) robust to hyperparameter
Background
long term memory 를 요하는 RL 을 위한 메모리 구조로는 LSTM 사용
[Transformer]
supervised learning task 마저에서조차 long sequence 문제가 들어오면 transformer는 이를 기억하기 힘들어한다
학술검색 : Long Range Arena : A benchmark for efficient transformers. In International Conference on Learning Representations, 2021 시도
Memory Architecture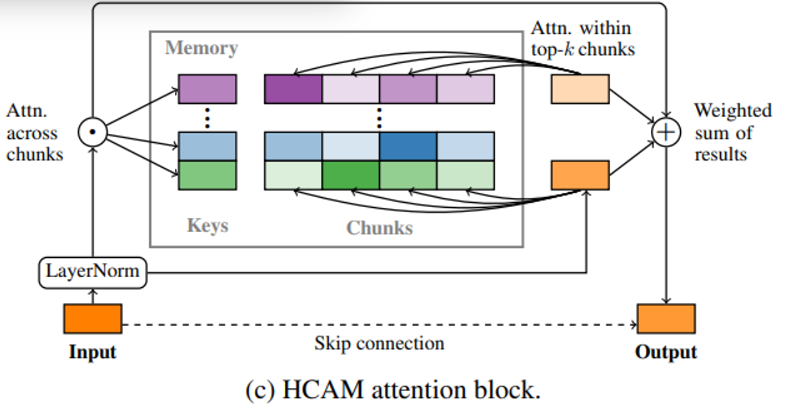
- 메모리를 chunk로 나눠 저장 후 이를 대표하는 값은 average pool 시켜 저장
- 이 average pooled 된 값이 key로 작용
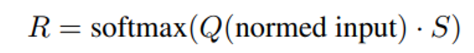
- 들어온 input은 normalized 된 이후 Q matrix 로 linear projection 된다
- key 로써 작용하는 대표값들과 곱셉 후 softmax를 통해 relevance score 를 구한다
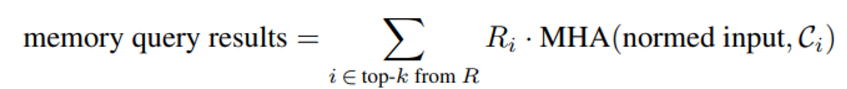
- C_i는 i 번째 key에 대한 memory chunks 들을 나타내며 input 과의 mulit-head attention 결과값에 relevance score를 가중치로 곱한 값의 합을 결과로 반환한다
- 이 값은 input에 더해져서 최종 HCAM block의 output으로 나타난다
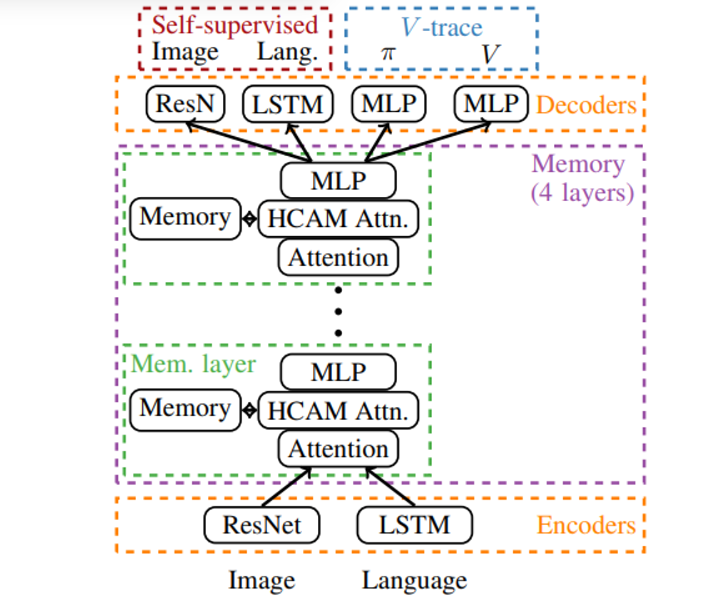
- agent는 IMPALA 알고리즘에 의해 훈련된다
- memory 구조는 Gated Transformer XL에서 따왔다..?
- XL memory를 HCAM block 으로 교체했다
- local attention 에 주는 input을 메모리에 저장했다 (output보다 결과가 좋음)
- fixed length memory chunk 에 이 값을 저장 후 chunk 가 가득 차면 메모리에 올렸다
- episode 사이에 memory를 비웠다 (cross-episode memory 평가시 제외)
- memory로 흘러들어가는 gradient 는 막았다 (top-k relevent chunk 고르는 형태에 대한 미분불가능함을 해결) → 이거 옛날에 해결하는 논문 있지 않았나..?
- encoder를 빨리 훈련시키기 위해 reconstruction loss 를 설정했다
Experiment
실험 3.3 : word-learning task (이전 실험들보다 maintain 하기 더 어렵고 distractor task 가 존재)
transformer based agent가 3D env에서 한번 본 물체를 기억할 수 있다는 사실을 발표한 선행논문 task를 더 어렵게 만듦(중간에 방해하는 task들로)
방식 ) 세가지 고정된 물체들로 이 들 중 하나를 들어올리라는 task를 distractor로 넣는다
⇒ 10개 distractor phase 까지 커버가능했다
[episode 간 knowledge 유지하기]
- agent를 single episode로 계속 훈련시킴
- 여러 episode 이전에서 나왔던 word와 관련된 task로 evaluation을 진행함
- agent는 새로운 단어를 저장하게 강제되지 않음
- 결과 ) 4 에피소드 이후의 단어를 기억해냄, 두 에피소드 이후에 기억해 내는데 각 에피소드마다 distractor task가 훈련시보다 많이 존재함
Discussion
- new env에서 optimal planning, delay + distrator task의 존재에도 이전 timestep 더 나아가 이전 episode에서 있었던 것도 기억
[language task와 같은 supervised setting 과 RL 비교]
- sparse reward 환경은 빈약한 learning signal 을 주는데 HCAM 의 memory는 이를 극복하게 도와준다
- RL이 진행되는 multimodal 한 환경은 language 환경보다 많은 정보를 내포하고 있다 → memory 가 필요한 이유
- 수행된 task들은 과거 memory에 대해 detailed, structured aspect 을 요구하는데 보통 nlp task는 structure에 크게 의존하지 않는다
[episodic memories] page 9 부분에서 힌트..?
It can be useful to store more general structures—such as a time-sequence of states—as a single “value” in memory
[Transformer memories]
- inductive bias를 통해서 transformer가 자신이 훈련된 것보다 더 킨 evalutation length에서 이익을 볼 수 있다는 논문
Attention with linear biases enables input length extrapolation
[Memory and adaptation]
- prior task representation 을 바꾸는 것이 변형된 task에 대한 zero shot adaptation을 가능하게 한다는 논문
Transforming task representations to perform
novel tasks
future directions
- 현재 방식은 previous step을 메모리에 저장하는 방식을 요구하는데(그 step을 포함하는 chunk가 예측에 상관없더라도) 이를 전체 language dataset을 살펴보는 kNN implementation을 이용해 해결할 수 있을 것이다
Generalization through memorization: Nearest neighbor language models
- 지금은 그냥 chunk로 나누고 있지만 event segmentation 방식을 사용하면 더 성능을 높일 수 있을 것이다
- chunk summary 에 대한 개선된 방식도 존재할 것이다

Therapeutic Approaches: Learn about different therapeutic approaches and their effectiveness in treating mental health issues. Our content covers therapies such as cognitive-behavioral therapy (CBT), psychotherapy, and more. Mind Psychiatrist provides insights into finding the right therapy for your needs. Mind Psychiatrist