Guiding Pretraining in Reinforcement Learning with Large Language Models
Intro
reward 손수 만드는 것에 대한 어려움 지적
이에 대한 대안으로 intrinsic reward 도입 → action space 가 넓을 경우 방문하지 않은 space에 가중치를 주는 방식은 한계가 있음
이에 대한 대안으로 다시 LLM 을 useful behavior를 제공하는 도구로 사용
→ 상세히는 goal을 제시하고 reward를 제공
→ 이를 통해 goal을 이루는 방향으로 agent가 학습됨
Methods
주게 될 reward는 goal conditioned 로 아래와 같이 주어지며
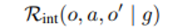
goal generation 과정도 LLM을 통해 이뤄진다.
상세)
1) GPT 같은 auto-regressive한 LLM으로 goal을 만들고
2) masked-LM을 사용해 1) 에서 만들어진 goal의 vector representation을 나타낸다.
goal generation 시 LLM에 들어가는 prompt는 다음과 같다.
→ 가능한 action + current obs + what would you do?
goal을 뽑아내는 형태에 두 가지가 있음
1) open-ended generation
- LLM 이 생성하는 문장 자체를 그대로 goal로 삼아버린다.
2) closed-form
- 가능한 goal을 QA task 형태로 주고 o, x 형태로 반환
reward generation도 LLM을 통해 이뤄진다.

여기서 c는 captioner라는 것으로 실험 바탕이 이미지이기 때문에 언어 형태로 바꿔줘야하고 goal 과 생성된 caption 사이의 cosine similarity를 측정해서 이 값이 특정 threshold를 넘으면 reward를 그에 비례하여 부여한다.
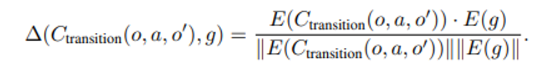
상세 계산은 위와 같으며 embedding vector 값 계산은 sentenceBERT 모델로 이뤄짐
이러한 모델링(transition과 goal 사이 거리 재는 것)은 아래 논문에서 이뤄짐
Huang, W., Abbeel, P., Pathak, D., and Mordatch, I. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. arXiv preprint
arXiv:2201.07207, 2022a.
우리 연구의 경우
우리가 만약 goal(reason)을 rating 이 특정 점수 이상인 상품에 대해 생성할 것이어서 이에 대해 fine-tune된 reasoner 모델이 만들어진다면
위의 모델이 생성하는 goal(rationale)과 막상 보게 된 상품 사이의 distance 측정을 통해 reward를 매길 수 있다.
또한 우리는 상품에 대한 rating 점수를 보유하고 있기 때문에 이렇게 생성된 reward의 성능을 평가할 수 있다. → 우리가 만든 goal(rationale) 에 대한 타당성을 입증할 수 있음
- 상품 설명 간 distance 계산 metric을 새로 제안하는 것도 contribution이 될 수 있을 것
다시 돌아와서
여러 개의 goal 이 추천될 수 있는 setting 인 것 같고 agent가 한 transition에 대해 이 중 가장 최대의 cos-similarity를 reward로 선택한다.

구현 detail
bias를 없애기 위해 같은 episode에서 이미 이룬 goal을 제거하는 filtering 과정을 포함
→ 성능에 중요한 역할을 함 !
베이스 알고리즘은 DQN
LLM의 도움을 받는 것이고 mlp layer로 text encoded 결과 입력받는 방식으로 전형적인 RL agent 모습.
이 논문에서 얻어가야 할 것
reward 주는 방식 (transition 과 goal 사이 cosine-similarity 같이)
베이스 라인으로 기존의 unsupervised RL 방식과 비교
