Intro
- On-policy Policy Gradient 방식 (Policy는 stochastic 형태)
- clipped probability를 통해 비관적인 lower bound 예측을 통한 novel objective 를 설정
- Policy optimize 과정은 policy에서 sample data를 받고 sampled data에서 optimization 과정을 거치는 것이다
Background
- policy gradient는 objective L을 미분하는 형태로 다음과 같은 objective와 gradient 식으로 주어진다
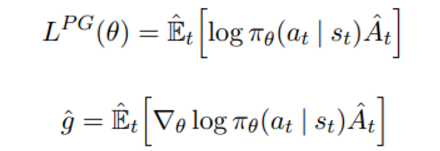
- TRPO 에서는 아래와 같은 contraint 하에서 objective function 이 업데이트된다
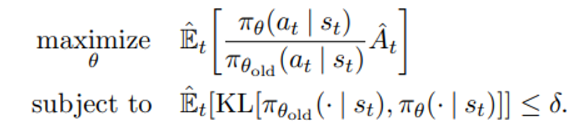
E_t notation은 유한한 sample batch 에서 실험적인 평균값을 의미한다
→ 근데 이게 여러 batch에서 t 방향으로의 평균을 의미하는지
→ 각각의 batch에 대해 finite 한 trajectory 평균인지 모르겠음 (t 가 )
TRPO 논문에서는 unconstrained optimization 문제로 변환하기 위해 대신 아래와 같은 수식을 사용한다

하지만 실제 상황에서는 여러 환경에서 최적인 beta를 찾는것이 어려울 뿐만 아니라 같은 상황에서도 변하는 policy에 맞춰 알맞은 beta를 찾는것이 어렵기 때문에 추가적인 modification 이 필요하다
Clipped Surrogate Objective
TRPO에서는 old policy에 대한 current policy의 비율을 r(t)로 정의하고 아래와 같은 objective를 최대화 시키려 한다
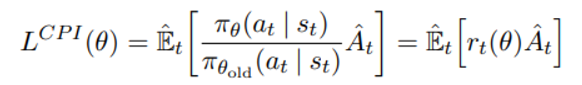
하지만 contraint 없이 이러한 objective를 최대화 시킨다면 과도하게 큰 policy update를 유발할 것이며 이를 저지하기 위해 clipped objective를 제안한다
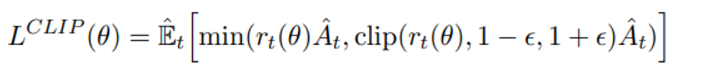
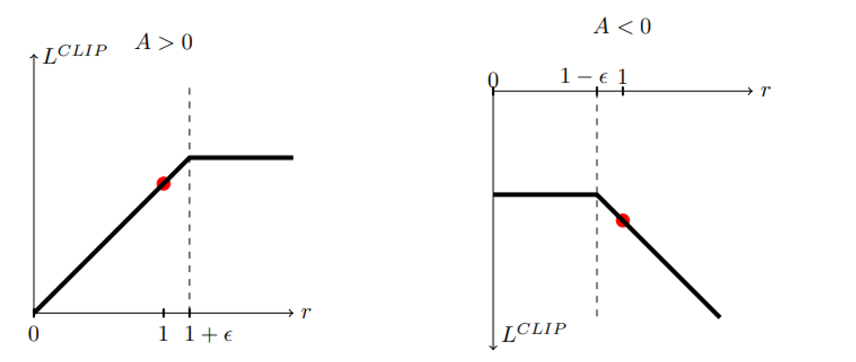
(위의 그림을 다음과 같이 이해했다)
A 는 advantage function으로 A>0 인 경우 위의 objective는 policy가 이러한 action 을 취하는 방향으로 변하는데 일정한 bound를 건다 (해당 action을 취하더라도 objective가 계속 증가하지 않게!)
반대로 A<0인 경우 policy가 이러한 action을 취하지 않으려는 방향으로 변하는데 일정한 bound를 건다 (마찬가지로 해당 action을 취하더라도 objective가 계속 변하지 않게)
Adaptive KL Penalty Coefficient
→ 위와 같이 clipped 쓰는 방식 대신 TRPO 변화하기 이전 방식의 objective function 처럼 penalty coefficient 주는 방식을 생각해 볼 수 있는데 이러한 방법은 성능이 그닥 좋지 않지만 논문에서 baseline 으로 사용되었다
Algorithm
종합적인 objective는 아래와 같으며 이를 최대화 하는 방향으로 policy update가 진행된다 (Silver 강의 PG에서 J 와 상응하는 함수)
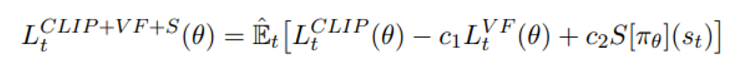
첫번째 항은 clipped surrogate objective 두 번째 항은
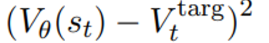
위와 같이 value function의 squared-error 이다
마지막 항은 충분한 exploration을 보장하는 entropy 부분이다
Clipped surrogate objective에서 사용되는 advantage function은 아래와 같이 정의된다
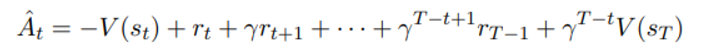
이는 PPO 에서 택한 policy update 과정과 결부되어 있으며 policy를 T step 동안 돌리고 얻은 sample을 통해 update 를 시키기 때문에 위와 같은 함수를 정의한 것이다
위의 advantage 함수는 TD-error와 함께 나타내려면 아래와 같이 표현가능하다
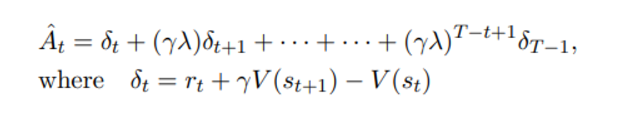
Pseudo code

전체 코드는 위와 같으며 N개의 actor가 훈련에 참여한다..?
하나의 policy는 각각의 actor 에 대해 (총 N번) T 번의 timestep동안 총 NT 개의 sample data를 갖고 minibatch SGD를 통해 optimize 된다
