Kafka 브로커란?
Kafka에서 브로커는 데이터를 저장하고 전송하는 서버를 의미한다.
여러 대의 브로커가 모여 Kafka 클러스터를 구성한다.
각 브로커는 고유의 정수형 ID로 식별된다.
예를 들어, 브로커 101, 102, 103 등이 있을 수 있다.
데이터 분산: 토픽, 파티션, 브로커의 관계
Kafka의 데이터 분산은 토픽(Topic), 파티션(Partition), 브로커(Broker) 세 요소가 유기적으로 연결되어 이루어진다.
- 토픽: 데이터 스트림의 논리적 단위
- 파티션: 토픽을 나누는 물리적 단위(병렬성과 확장성의 핵심)
- 브로커: 파티션을 저장하고 관리하는 서버
예시로 살펴보는 데이터 분산
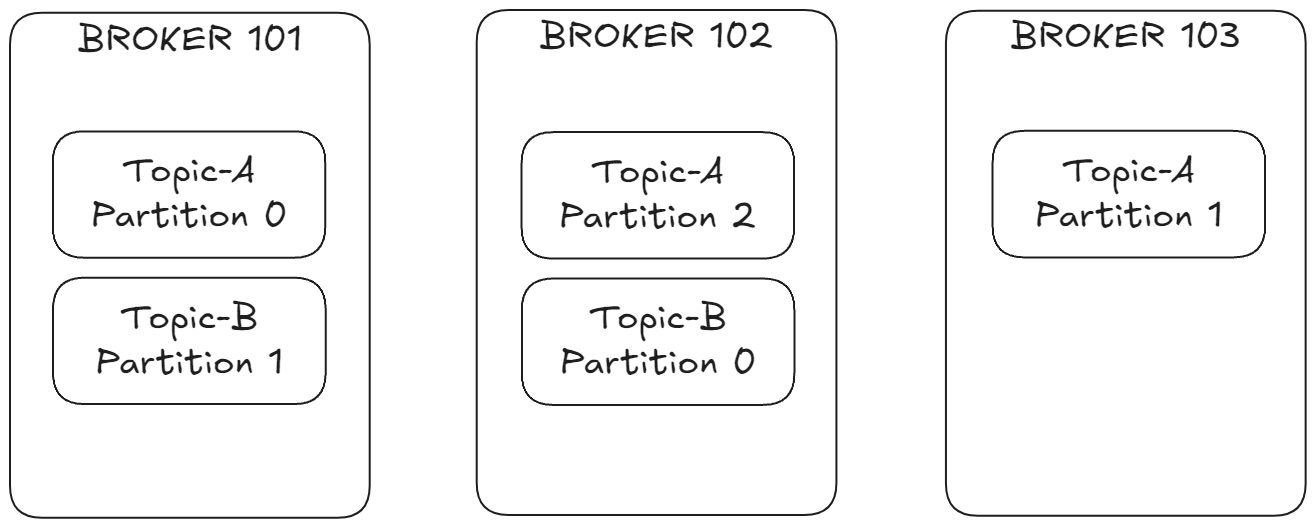
-
토픽 A (파티션 3개):
- 파티션 0 → 브로커 101
- 파티션 1 → 브로커 103
- 파티션 2 → 브로커 102
-
토픽 B (파티션 2개):
- 파티션 0 → 브로커 102
- 파티션 1 → 브로커 101
이처럼 파티션들은 클러스터 내 여러 브로커에 분산되어 저장된다.
브로커마다 저장하는 파티션이 다르며, 어떤 브로커는 특정 토픽의 파티션을 전혀 갖지 않을 수도 있다.
이 구조 덕분에 Kafka는 수평적 확장성을 갖게 된다.
브로커와 파티션을 추가하면 데이터 저장과 처리 능력이 자연스럽게 늘어난다.
카프카 클러스터란?
카프카 클러스터는 대규모 데이터의 실시간 스트리밍과 이벤트 처리를 위해 설계된 분산 메시지 시스템인 Apache Kafka의 핵심 구조다. 클러스터는 여러 대의 서버(브로커)로 구성되어, 데이터의 안정적 분산 저장과 고가용성, 확장성을 제공한다.
카프카 클러스터의 주요 구성 요소
- 브로커(Broker)
- 토픽(Topic)
- 파티션(Partition)
- 세그먼트(Segment)
- 프로듀서(Producer)와 컨슈머(Consumer)
- 컨트롤러(Controller)와 주키퍼(Zookeeper)
카프카 클러스터의 특징
- 고가용성
여러 브로커에 데이터를 복제(Replication)해 저장하므로, 일부 브로커가 장애가 나도 데이터 손실 없이 서비스가 지속된다.- 확장성
브로커와 파티션 수를 늘려 손쉽게 시스템을 확장할 수 있다. 대규모 환경에서는 수십~수천 대의 브로커, 수십만 개의 파티션으로 구성할 수 있다.- 데이터 복제 및 장애 대응
파티션 단위로 복제가 이루어지며, 리더-팔로워 구조를 통해 장애 시 자동으로 리더를 재할당해 서비스 중단을 최소화한다.- 분산 처리
데이터가 여러 파티션에 분산 저장되어 병렬로 빠르게 처리할 수 있다.
브로커 발견(Discovery)과 부트스트랩 서버
Kafka 클러스터에 연결할 때 모든 브로커의 정보를 미리 알 필요는 없다.
Kafka의 클라이언트(프로듀서, 컨슈머 등)는 부트스트랩 브로커(bootstrap broker) 한 곳에만 연결하면 된다.
브로커 발견 과정
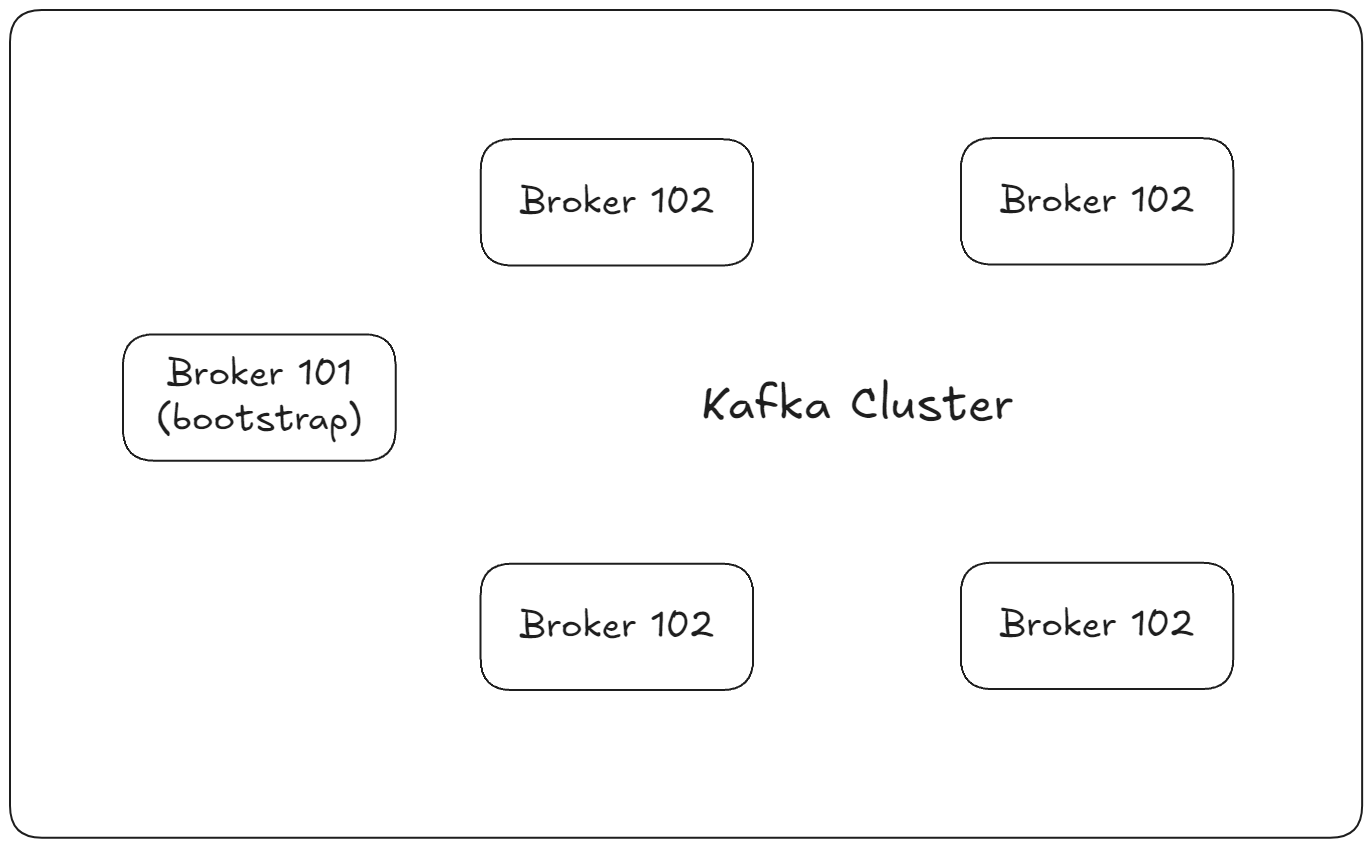
브로커 101만 부트스트랩이라고 표시했지만 사실은 모든 브로커가 부트스트랩 서버이다.
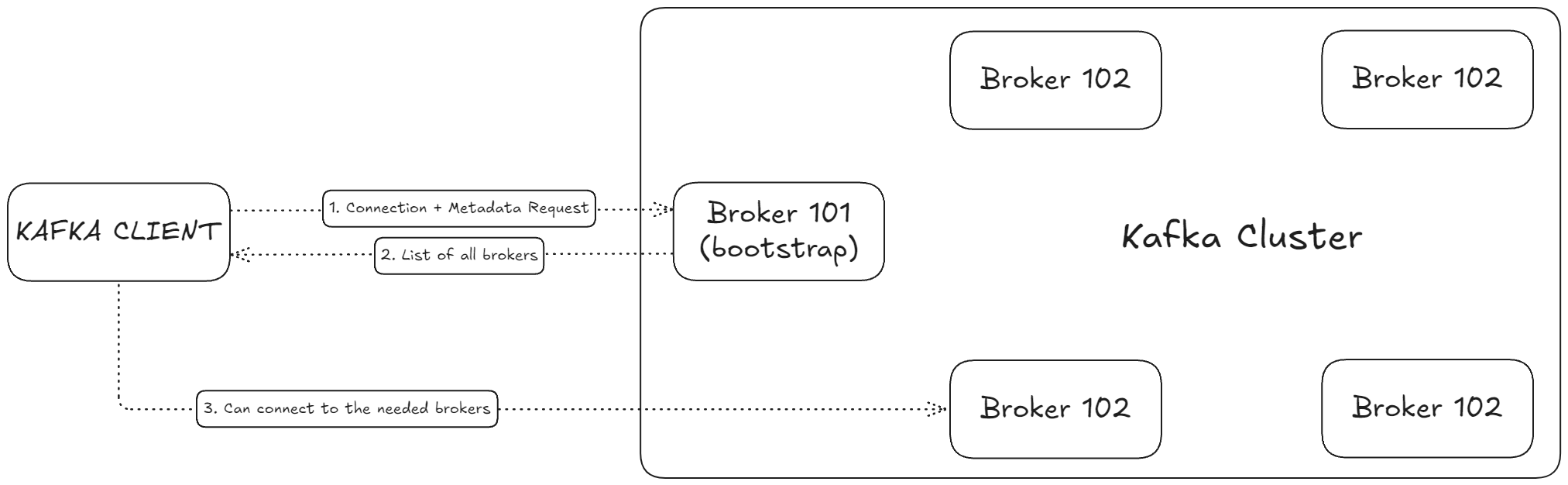
- 클라이언트가 부트스트랩 브로커(예: 101번)에 연결하고 메타데이터 요청을 전송
- 부트스트랩 브로커가 전체 클러스터의 브로커 목록과 메타데이터(토픽, 파티션 정보 등)를 반환
- 클라이언트는 필요한 브로커와 직접 통신하며 데이터 생산/소비를 진행
모든 브로커는 클러스터의 전체 메타데이터를 알고 있으므로,
어떤 브로커에 접속해도 클러스터 전체에 접근할 수 있다.
부트스트랩 서버
- 클러스터에 있는 각각의 Kafka 브로커
실전 TIP:
클러스터에 브로커가 5대 있다면, 그 중 아무 브로커나 부트스트랩 서버로 지정해도 무방하다.
브로커의 유연한 확장성
Kafka 클러스터는 원하는 만큼의 브로커로 구성할 수 있다.
- 소규모 환경: 3대 브로커로 시작
- 대규모 환경: 100대 이상의 브로커 운영도 가능
브로커와 파티션을 늘릴수록 데이터가 더 넓게 분산되고, 처리량과 안정성이 크게 향상된다.
핵심 요약
- Kafka 브로커는 데이터를 저장·전송하는 서버로, 클러스터의 핵심 구성 요소다.
- 파티션 단위로 데이터가 여러 브로커에 분산 저장되어, 확장성과 장애 복구가 뛰어나다.
- 클라이언트는 부트스트랩 브로커 한 곳에만 연결하면 전체 클러스터에 접근할 수 있다.
- 브로커 수와 파티션 수를 조절해 클러스터를 유연하게 확장할 수 있다.
Kafka 브로커의 구조와 동작 원리를 이해하면,
클러스터 설계와 운영, 장애 대응, 확장성 확보에 큰 도움이 된다.
