Kafka
1.Apache Kafka를 통한 기업 데이터 통합의 이해

기업에는 데이터베이스와 같은 다양한 소스 시스템이 존재한다. 시간이 지남에 따라 회사의 다른 부서에서 이 데이터를 다른 시스템(타깃 시스템)에 이동시켜야 하는 필요성이 생긴다. 초기에는 이 과정이 간단하다. 누군가 코드를 작성하여 데이터를 추출, 변환, 로딩하는 작업을
2.Apache Kafka 이론 - 토픽, 파티션, 오프셋
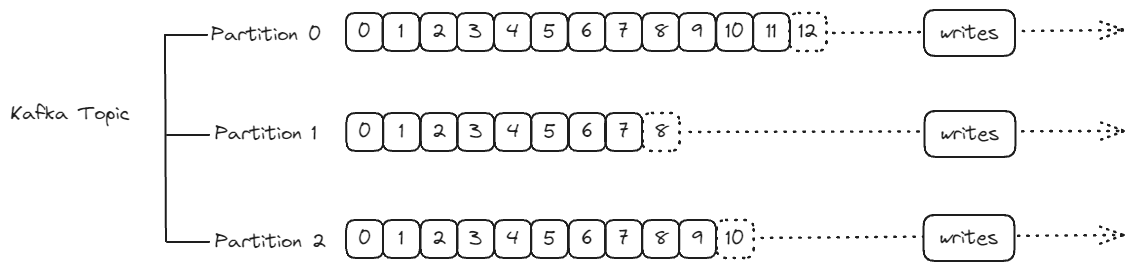
Apache Kafka의 토픽과 파티션 이해하기 Apache Kafka는 분산 데이터 스트리밍 플랫폼으로, 데이터 통합과 실시간 처리를 위한 강력한 도구다. Kafka 토픽(Topic)의 개념 Kafka 토픽은 Kafka 클러스터 내에 존재하는 데이터 스트림을 가리
3.Apache Kafka 이론 - 프로듀서 & 메시지 키
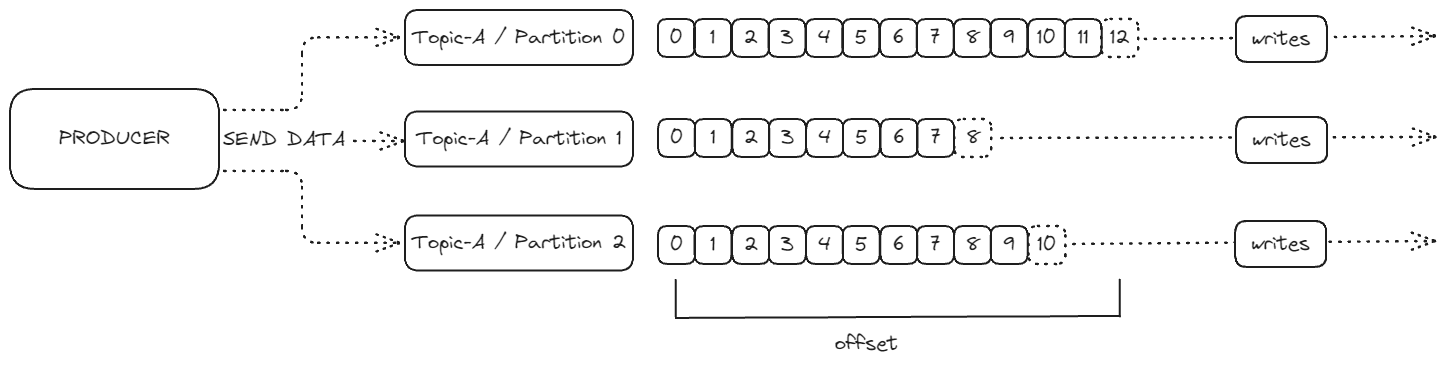
프로듀서는 Kafka 토픽과 파티션에 데이터를 전송하는 역할을 한다. 중요한 점은 프로듀서가 메시지를 어떤 파티션에 기록할지 미리 결정한다는 것이다. 많은 사람들이 Kafka 서버가 이 결정을 한다고 오해하지만, 실제로는 프로듀서가 이 결정을 담당한다.예를 들어, To
4.Apache Kafka 이론 - 컨슈머 & 역직렬화
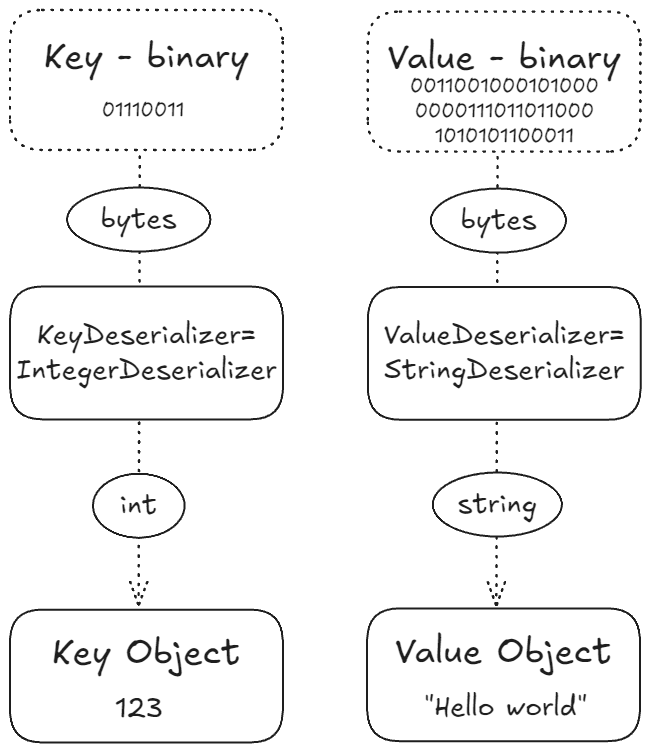
컨슈머의 기본 개념 Kafka 컨슈머는 풀(pull) 모델을 구현한다. 이는 컨슈머가 Kafka 브로커(서버)에 직접 데이터를 요청하고, 그에 대한 응답을 받는 방식이다. 중요한 점은 Kafka 브로커가 데이터를 컨슈머에게 푸시하는 것이 아니라, 컨슈머가 필요할 때
5.Apache Kafka 이론 - 컨슈머 그룹 & 컨슈머 오프셋
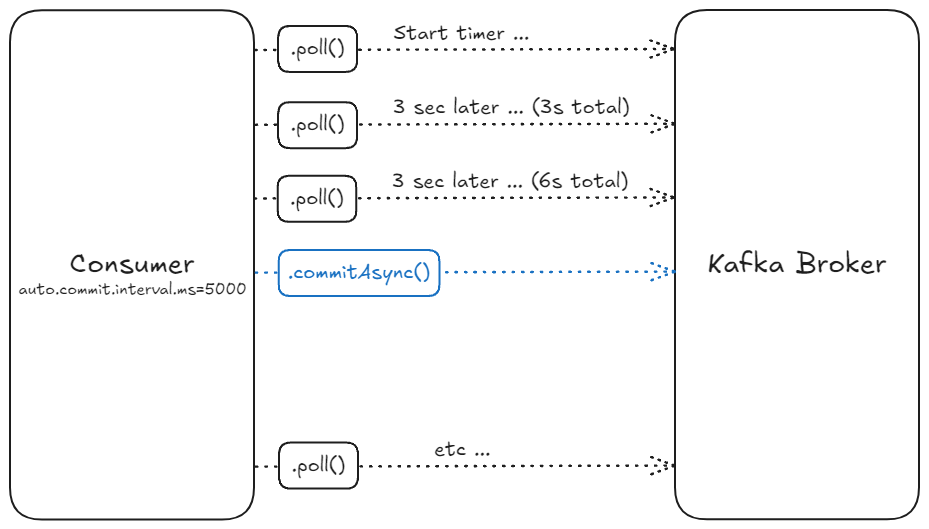
컨슈머 그룹이란? Kafka에서 데이터를 읽는 애플리케이션은 여러 컨슈머(Consumer) 인스턴스를 실행할 수 있다. 이 컨슈머들이 그룹을 이루어 데이터를 읽는 구조를 ‘컨슈머 그룹’이라고 부른다. 컨슈머 그룹은 확장성과 병렬 처리의 핵심이다. 컨슈머 그룹과 파티
6.Apache Kafka 이론 - 브로커 & 토픽
Kafka 브로커란? Kafka에서 브로커는 데이터를 저장하고 전송하는 서버를 의미한다. 여러 대의 브로커가 모여 Kafka 클러스터를 구성한다. 각 브로커는 고유의 정수형 ID로 식별된다. 예를 들어, 브로커 101, 102, 103 등이 있을 수 있다. 데이터
7.Apache Kafka 이론 - 토픽 복제
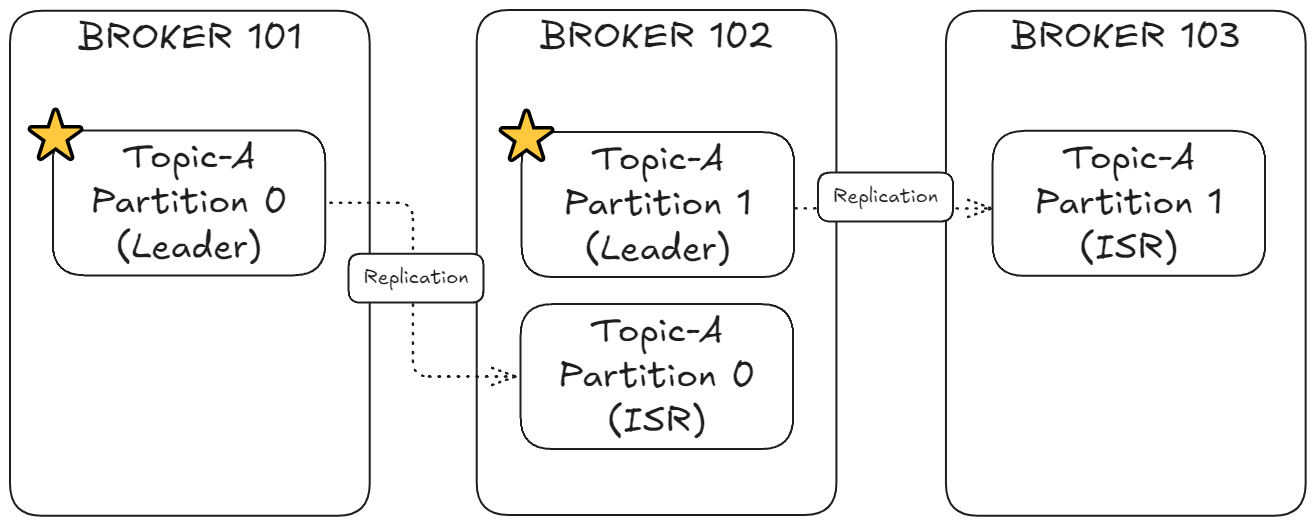
복제 계수(Replication Factor)란 무엇인가? Kafka에서 복제 계수는 각 토픽 파티션의 데이터 사본(레플리카)이 몇 개의 브로커에 저장될지 결정하는 값이다. 개발/테스트 환경: 복제 계수 1로도 충분하다. (데이터가 한 브로커에만 저장) 프로덕션 환
8.Apache Kafka 이론 - 프로듀서 확인 & 토픽 내구성
프로듀서의 데이터 쓰기 확인(acks)란? Kafka 프로듀서는 브로커에 데이터를 전송할 때, 해당 데이터가 성공적으로 저장되었는지 확인(acknowledgment)을 받을 수 있다. 이 확인 방식은 acks 옵션으로 제어하며, 데이터 유실 가능성과 시스템의 신뢰성,
9.Apache Kafka 이론 - Zookeeper & Kafka KRaft
Zookeeper란 무엇인가? Zookeeper는 Kafka가 오늘날까지 기능을 유지해온 비결이다. 하지만 Zookeeper는 점점 사라지고 있고, 앞으로는 Kafka에서 대체될 예정이다. Kafka와 Zookeeper의 관계 Zookeeper의 역할 Zooke
10.Apache Kafka - Windows 환경에서 KRaft 모드로 카프카 시작하기
Zookeeper는 점점 사라지고 있고, 앞으로는 Kafka에서 대체될 예정이다. 따라서 KRaft 모드로 카프카를 시작하려는데 어떤 방식으로 카프카를 시작할 지 고민이 되었다. 많은 공식 문서와 기업, 커뮤니티에서 도커로 카프카를 실행하는 방법과 베스트 프랙티스를
11.Apache Kafka - Kafka 컨슈머 그룹과 파티션 리밸런싱 전략 이해하기
Kafka 컨슈머 그룹과 파티션 리밸런싱 전략 이해하기 Kafka에서 컨슈머 그룹의 구성이 변경될 때마다 파티션 리밸런싱이 발생한다. 이 과정은 컨슈머가 그룹에 합류하거나 떠날 때, 또는 관리자가 토픽에 새 파티션을 추가할 때 발생하는 중요한 메커니즘이다. 리밸런싱을
12.Apache Kafka - 프로듀서의 acks 설정과 데이터 안전성 이해하기
Kafka 프로듀서가 메시지를 브로커에 전송할 때, 데이터가 얼마나 안전하게 저장되는지는 acks 설정에 따라 크게 달라진다.프로듀서가 메시지를 전송한 후 브로커의 응답을 기다리지 않고 즉시 성공으로 간주한다.특징:브로커가 메시지를 실제로 받았는지 확인하지 않음네트워크
13.Apache Kafka - 프로듀서의 재시도 메커니즘 & 멱등 프로듀서
Apache Kafka 프로듀서가 브로커에 메시지를 전송할 때 네트워크 문제나 브로커 장애 등으로 실패할 수 있다. 이런 상황에서 데이터 손실을 방지하기 위해 Kafka는 재시도 메커니즘을 제공한다. 프로듀서 재시도가 필요한 이유 프로듀서에서 Kafka 브로커로 데
14.Apache Kafka - 프로듀서 최적화: 메시지 압축과 배칭 전략
메시지 압축과 배칭 전략을 적절히 활용하면 네트워크 대역폭을 절약하고, 처리량을 증가시키며, 디스크 사용량을 줄일 수 있다. 메시지 압축(Message Compression)의 이해 압축의 필요성과 이점 프로듀서가 Kafka에 데이터를 전송할 때 일반적으로 텍스트
15.Apache Kafka - 컨슈머의 고급 설정과 동작 원리
Kafka 컨슈머 그룹이 장시간 실행될 때 안정적으로 작동하기 위해서는 내부 메커니즘과 주요 설정을 이해하는 것이 중요하다. 컨슈머 그룹의 핵심 메커니즘 Kafka 컨슈머 그룹은 두 가지 중요한 메커니즘을 통해 상태를 유지한다: 허트비트 스레드(Heartbeat
16.Apache Kafka - 컨슈머의 가장 가까운 레플리카 읽기 기능
Kafka 2.4 버전부터 도입된 '가장 가까운 레플리카 읽기(Closest Replica Fetching)' 기능은 멀티 데이터센터 환경에서 Kafka를 운영할 때 레이턴시와 네트워크 비용을 크게 줄일 수 있는 중요한 기능이다. 기존 Kafka 컨슈머의 동작 방식
17.Apache Kafka - Kafka Connect, Kafka Streams, Schema Registry
카프카 생태계는 데이터 파이프라인 구축과 실시간 데이터 처리를 위한 다양한 컴포넌트를 제공한다. Kafka Connect Kafka Connect는 Apache Kafka의 오픈소스 구성요소로, 데이터베이스, 키-값 저장소, 검색 인덱스 및 파일 시스템 간의 데이터
18.Apache Kafka - 아키텍처 설계 가이드: 파티션, 복제 계수 및 토픽 네이밍 컨벤션
파티션 개수와 복제 계수 설정하기 토픽을 생성할 때 가장 중요한 두 가지 요소는 파티션 개수와 복제 계수다. 이 두 요소는 시스템 성능과 지속성에 직접적인 영향을 미치기 때문에 처음부터 신중하게 설정해야 한다. 파티션 개수 변경의 영향 토픽 생성 후 파티션 개수를