Zookeeper란 무엇인가?
Zookeeper는 Kafka가 오늘날까지 기능을 유지해온 비결이다. 하지만 Zookeeper는 점점 사라지고 있고, 앞으로는 Kafka에서 대체될 예정이다.
Kafka와 Zookeeper의 관계
Zookeeper의 역할
- Zookeeper는 Kafka 브로커를 관리하는 소프트웨어다.
- Kafka 브로커들의 리스트를 유지한다.
- 브로커가 다운될 때마다 파티션의 새로운 리더를 선택하는 리더 선출 과정에 도움을 준다.
- 변경사항이 있을 때(예: 새 토픽 생성, 브로커 다운/생성, 토픽 삭제 등) Kafka 브로커들에게 알림을 전송한다.
- 그래서 Zookeeper에는 Kafka의 메타데이터가 많이 저장되어 있다.
Kafka 버전과 Zookeeper
- Kafka 2.x, 정확히는 2.8까지는 Zookeeper 없이는 사용할 수 없었다.
- Kafka가 출시된 때부터 Zookeeper는 Kafka 브로커들의 동반자였고, Zookeeper를 실행하지 않고는 Kafka를 실행할 수 없었다.
Kafka의 변화: Zookeeper에서 KRaft로
- Kafka 3.x부터는 Zookeeper 없이도 독립적으로 실행할 수 있다. 이를 Kafka Raft 메커니즘(KRaft, Kafka Raft)라고 부른다.
- Kafka 4.x 버전부터는 Zookeeper가 완전히 사라질 예정
- 커뮤니티는 Zookeeper 없이 Kafka가 올바르게 작동하도록 전환 중이며, 조만간 완전히 이전될 예정
실무에서의 Zookeeper 활용
왜 아직도 Zookeeper를 공부해야 할까?
- 지금으로써는 Kafka와 Zookeeper를 함께 사용해야 하므로, 여전히 Zookeeper를 공부해야 한다.
- 프로덕션 환경에서 많이 사용되고 있기 때문이다.
Zookeeper의 서버 구성
- Zookeeper는 홀수 개수의 서버와 함께 작동하도록 설계되어 있다.
- 1개, 3개, 5개, 7개 등으로 구성하며, 일반적으로 7개를 넘지는 않는다.
- Zookeeper에도 리더와 팔로워 개념이 있다. 1개는 쓰기, 나머지는 읽기에 사용된다.
과거와 달라진 점
컨슈머 오프셋 저장 위치
- 예전에는 Kafka 컨슈머 오프셋을 Zookeeper에 저장했지만, Kafka 0.10부터는 컨슈머 오프셋이라는 내부 Kafka 토픽에 저장한다.
- 이제 Zookeeper는 컨슈머 데이터를 전혀 갖지 않는다.
클라이언트와 Zookeeper의 관계 변화
- 과거에는 프로듀서, 컨슈머, 관리자 클라이언트 등 Kafka 클라이언트가 Zookeeper에 직접 연결해야 했다.
- 이제는 모든 Kafka 클라이언트와 CLI 툴이 오로지 Kafka 브로커만을 연결 엔드포인트로 사용하도록 바뀌었다.
- Kafka 2.0, 2.2부터는 kafka-topics.sh 명령도 Zookeeper가 아닌 Kafka 브로커를 참조한다.
KRaft 모드의 탄생 배경
KIP-500과 주키퍼 제거
2020년, Kafka 프로젝트는 주키퍼에 대한 의존성을 제거하는 작업을 시작했다. 이 작업은 KIP-500이라는 이름으로 불린다.
주키퍼를 사용하면 파티션이 100,000개를 넘었을 때 Kafka 클러스터에 스케일링 문제가 있었다. 100,000개면 정말 많은 수다.
KRaft란 무엇인가?
KRaft(Kafka Raft)는 Apache Kafka에서 기존에 사용하던 ZooKeeper를 대체하기 위해 도입된 새로운 메타데이터 관리 및 합의(Consensus) 프로토콜이다. KRaft는 Kafka 내부에 Raft 합의 알고리즘을 적용하여, 클러스터의 메타데이터와 상태를 Kafka 자체적으로 관리할 수 있게 만든 구조다.
주요 특징 및 배경
- ZooKeeper 제거: 기존 Kafka는 클러스터 메타데이터(토픽, 파티션, 컨트롤러 선출 등)를 ZooKeeper를 통해 관리했으나, KRaft 도입 이후에는 Kafka가 자체적으로 이 모든 것을 관리한다.
- 구조 단순화: Kafka만으로 클러스터를 운영할 수 있어 설치, 구성, 운영, 모니터링이 간단해지고, 관리 복잡성이 크게 줄어든다.
- 성능 및 안정성 향상: 메타데이터 동기화가 더 빠르고, 컨트롤러 장애 시 복구 속도가 빨라졌으며, 대규모 파티션 환경에서도 확장성이 좋아졌다.
- Raft 합의 프로토콜 적용: 여러 컨트롤러 노드(Controller Quorum)가 투표를 통해 메타데이터의 일관성과 장애 복구를 보장한다. 최소 과반수 이상의 컨트롤러가 살아있어야 클러스터가 정상 동작한다.
주키퍼 제거의 효과
주키퍼를 제거함으로써 Apache Kafka는 수백만 개의 파티션으로 확장할 수 있게 되었다.
또한 유지보수와 설정이 쉬워지고, 안정성도 개선되었으며, Kafka를 모니터링, 지원, 관리하기가 더 쉬워졌다.
이제 시스템 전체에 하나의 보안 모델만 적용하면 되기 때문에, 주키퍼 보안이 아니라 Kafka 보안만 신경 쓰면 된다.
KRaft 모드의 장점
- Apache Kafka를 사용할 때 시작 프로세스가 하나면 된다.
- 컨트롤러 셧다운 시간과 복구 시간이 단축된다.
- 관리와 운영이 단순해진다.
KRaft 도입 시기와 지원 버전
Kafka KRaft는 Kafka 3.x 버전(3.0)부터 구현되었다.
하지만 프로덕션 환경에서 준비가 된 것은 Kafka 3.3.1부터(KIP-833)다.
Kafka 4.0부터는 KRaft만 지원되고, 주키퍼는 더 이상 지원되지 않는다.
KRaft 아키텍처 vs. 주키퍼 아키텍처
주키퍼 기반 아키텍처
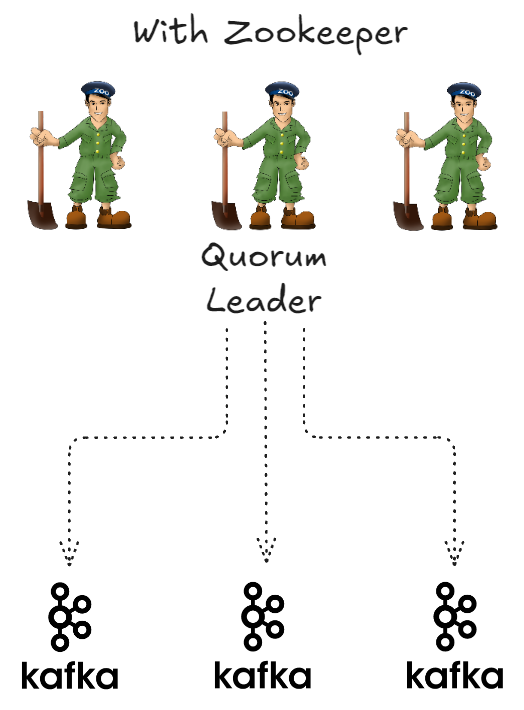
- 주키퍼에는 Kafka 브로커를 관리하는 리더가 있는 주키퍼 Quorum이 있다.
KRaft 기반 아키텍처
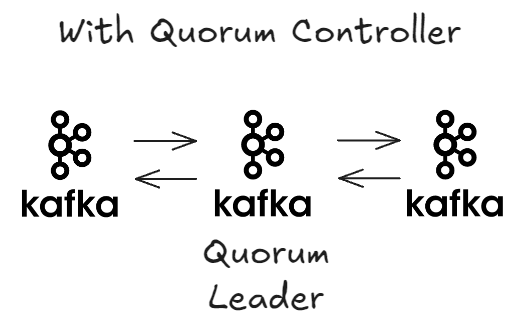
- Quorum Controller가 있는 경우, Kafka 브로커들만 존재하고, 그 중 하나가 Quorum 리더가 된다.
- 아키텍처가 훨씬 단순해졌다.
KRaft 모드와 기존 ZooKeeper 모드 비교
| 구분 | ZooKeeper 모드 | KRaft 모드 (Kafka Raft) |
|---|---|---|
| 메타데이터 관리 | ZooKeeper가 담당 | Kafka 내부 컨트롤러(Controller)가 담당 |
| 구성 복잡성 | ZooKeeper와 Kafka 모두 설치 및 관리 필요 | Kafka만 설치, 관리 |
| 장애 복구 | ZooKeeper 장애 시 전체 클러스터 영향 | 컨트롤러 Quorum 과반수만 살아있으면 동작 |
| 확장성 | 대규모 파티션에서 병목 현상 발생 가능 | 확장성 개선, 더 많은 파티션 처리 가능 |
| 합의 알고리즘 | ZooKeeper의 Zab 프로토콜 | Kafka 내장 Raft 프로토콜 |
KRaft의 성능 개선
블로그에서 가져온 자료에 따르면,
- 제어 셧다운 시간과
- 무제어 셧다운 후의 복구 시간이 상당히 더 우수하다.
전반적으로 KRaft는 엄청난 개선을 가져왔다.
앞으로의 방향과 주의사항
- 앞으로 Kafka는 Zookeeper 없이 동작하게 될 것이다.
- 클라이언트는 절대로 Zookeeper에 직접 연결하지 말아야 한다.
- Kafka 브로커만 연결 엔드포인트로 사용해야 하며, 프로그래밍할 때도 오직 Kafka 브로커에만 연결해야 한다.
- Zookeeper가 사라지는 이유는 Kafka에 비해 안전하지 않기 때문이다.
- 만약 Zookeeper를 사용한다면, Kafka 클라이언트가 아닌 오직 Kafka 브로커로부터의 연결만 수락하도록 해야 한다.
정리
- 최신 Kafka 개발자가 되고 싶다면, Kafka 클라이언트의 구성에서 절대로 Zookeeper를 사용하지 말자
- 프로그래밍 시에도 Zookeeper가 아닌 Kafka 브로커에만 연결하자
