Apache Kafka를 통한 기업 데이터 통합의 이해
기업 데이터 통합의 어려움
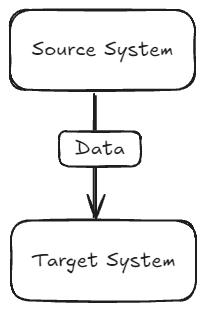
기업에는 데이터베이스와 같은 다양한 소스 시스템이 존재한다. 시간이 지남에 따라 회사의 다른 부서에서 이 데이터를 다른 시스템(타깃 시스템)에 이동시켜야 하는 필요성이 생긴다. 초기에는 이 과정이 간단하다. 누군가 코드를 작성하여 데이터를 추출, 변환, 로딩하는 작업을 수행한다.
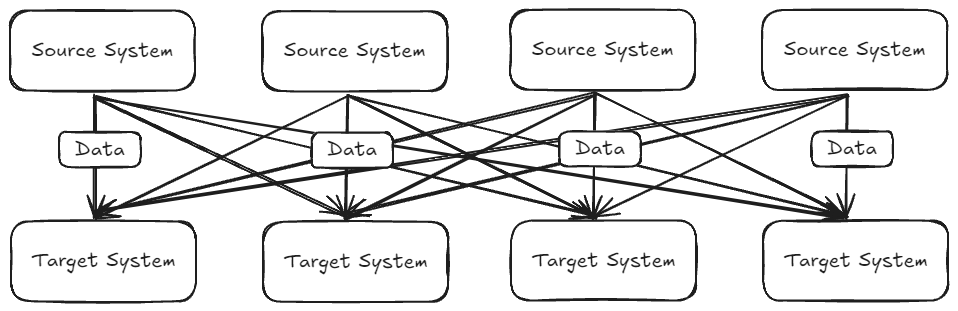
하지만 기업이 성장함에 따라 소스 시스템과 타깃 시스템의 수가 증가하면서 데이터 통합 문제는 복잡해진다. 정보 공유를 위해 모든 소스 시스템이 모든 타깃 시스템에 데이터를 전송해야 하기 때문이다.
기존 아키텍처의 문제점:
- 4개의 소스 시스템과 6개의 타깃 시스템이 있다면 24개의 통합을 구현해야 함
- 각 통합마다 다양한 프로토콜(TCP, HTTP, REST, FTP, JDBC 등) 관련 문제 발생
- 다양한 데이터 형식(Binary, CSV, JSON, Avro, Protobuf 등) 처리 필요
- 데이터 스키마 변경 시 발생하는 문제
- 소스 시스템의 부하 증가
Apache Kafka를 통한 해결책
이러한 문제를 해결하기 위해 Apache Kafka를 이용한 디커플링(decoupling)을 도입할 수 있다. 소스 시스템과 타깃 시스템 사이에 Apache Kafka를 배치하는 것이다.
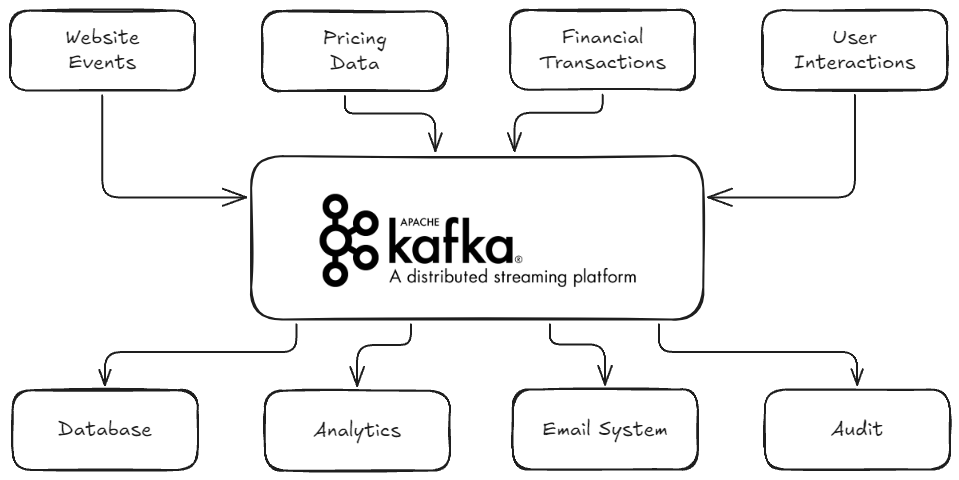
새로운 아키텍처의 작동 방식:
- 소스 시스템은 데이터를 생산하여 Apache Kafka로 전송
- Apache Kafka는 모든 소스 시스템의 데이터 스트림을 보유
- 타깃 시스템은 Apache Kafka로부터 필요한 데이터를 소비
이 구조에서 소스 시스템은 웹사이트 이벤트, 가격 데이터, 금융 거래, 사용자 상호작용 등이 될 수 있으며, 이들은 실시간으로 데이터 스트림을 생성한다. 타깃 시스템으로는 데이터베이스, 분석 시스템, 이메일 시스템, 감사 시스템 등이 있을 수 있다.
Apache Kafka의 장점
Apache Kafka는 LinkedIn에서 개발된 오픈소스 프로젝트로, 현재는 Confluent, IBM, Cloudera, LinkedIn 등의 대기업들이 유지보수하고 있다.
주요 특징:
- 분산형이고 회복력 있는 아키텍처로 고장에 대한 내성 보유
- 시스템 전체를 중단하지 않고도 업그레이드 및 유지보수 가능
- 수평적 확장성을 통해 브로커를 수백 개로 확장 가능
- 초당 수백만 개의 메시지 처리 능력
- 10밀리초 미만의 낮은 레이턴시로 실시간 시스템 구현 가능
Apache Kafka의 활용 사례
Kafka는 전 세계적으로 널리 사용되고 있으며, 2,000개 이상의 기업이 공식적으로 사용하고 있다. Fortune 100대 기업 중 80%가 Apache Kafka를 이용하고 있으며, LinkedIn, Airbnb, Netflix, Uber, Walmart 등의 대기업들이 포함된다.
주요 활용 분야:
- 메시징 시스템
- 활동 추적 시스템
- 다양한 위치에서 메트릭 수집
- 애플리케이션 로그 수집
- 스트림 처리
- 시스템 의존성과 마이크로서비스 디커플링
- 빅데이터 기술(Spark, Flink, Storm, Hadoop 등)과의 통합
- 마이크로서비스 발행/구독
구체적인 활용 사례:
- Netflix: 실시간 TV 쇼 추천 시스템
- Uber: 사용자, 택시, 여행 데이터 실시간 수집 및 수요 예측, 실시간 요금 계산
- LinkedIn: 스팸 방지 및 사용자 상호작용 수집을 통한 실시간 관계 추천
이 모든 사례에서 Kafka는 운송 메커니즘으로 사용되어 기업 내 대량의 데이터 흐름을 가능하게 한다. Apache Kafka를 통해 기업은 복잡한 데이터 통합 문제를 효과적으로 해결하고 실시간 데이터 처리 시스템을 구축할 수 있다.
