1. File System
1. File
- byte 단위의 linear한 배열
- 메모리와 다르게 persistent함
- 읽고 쓸 수 있음
- 일반파일, 디렉토리, 링크, 특수파일
2. File System
- OS가 File을 관리하고 디스크 상에 구성하는 방식
| 파일 시스템 종류 | 특징 |
|---|---|
| EXT | 리눅스 초기에 사용되던 파일 시스템 |
| EXT2 | 현재 가장 많이 사용하는 파일 시스템, fsck 지원 |
| EXT3 | EXT2 파일 시스템의 수정 버전, 저널링 지원 |
| minix | 과거 Minix에서 사용된 파일 시스템으로 가장 오래되고 기본이 됨 |
| hpfs OS/2 | OS/2의 파일 시스템이며 현재는 읽기 전용임 |
| isofs CD-ROM | ISO 기준을 따르는 표준 CD-ROM의 파일 시스템, 록 브릿지가 기본적으로 지원됨 |
| nfs | 네트워크 파일 시스템 |
| JFS | IBM사가 개발한 저널링 파일 시스템 |
2. File의 유형
1. 일반 파일
- 텍스트, C언어 소스 코드, 쉘 스크립트, 바이너리 프로그램
- 모든 것은 파일로 취급됨
2. Directory
- 디렉토리의 이름 + 파일 및 디렉토리에 대한 포인터를 가진 파일
- 파일의 이름과 inode 번호 목록만 가지고 있음
- <user가 읽을 수 있는 파일이름, 시스템이 읽을 수 있는 파일이름>
- 파일의 경로, 이름이 저장되는 유일한 장소임
- dir은 서로 중첩될 수 있음
| path name | inode number |
|---|---|
| . (현재 dir) | 342 |
| .. (상위 dir) | 8310 |
| bar.txt | 23 |
| project (하위 dir) | 3048 |
3. Link
1. Hard Link
- 두 path name은 동일한 inode number를 사용함
- 하나의 데이터에 여러 개의 이름을 붙인다
- a, b 파일이 hard linked 되었다면 두 파일은 동일함
- 만들 때마다 inode의 reference count가 하나씩 증가함
- dir에 대해서 link할 수 없음 - 순환 구조 방지
🕹️
ln origin hardlink
1. origin이 가리키는 inode number을 확인 → 30
2. hardlink라는 새로운 경로 생성
3. 해당 경로가 30번 inode를 가리키도록 directory entry에 추가함
4. inode의 reference count를 1 증가시킴
5.ls -li→ reference count가 2
2. Soft / Symbolic Link
- second path name을 가리킴
- 원본 파일의 경로 정보
- dangling reference
- 다른 parent를 가짐
- dir에 대해서 link할 수 있음
- 파일 타입 =
l - inode가 아닌 경로를 이용함
- 서로 다른 하드 드라이브, 파티션 간에도 링크 가능
- 하드 링크는 동일한 파티션(FS) 내에서만 가능함
🕹️
ln -s /path/to/origin softlink
1. softlink라는 새로운 파일을 생성함
2. origin을 가리키는 inode와는 별개의 다른 inode number을 할당받음
3. softlink 파일의 내용은 origin의 경로 이름으로 저장됨("/path/to/origin")
💡 사용자가 심볼릭 링크를 열려고 하면?
1. 파일의 타입 읽음
2.l이므로 해당 파일의 내용을 읽음
3. 내용 == 원본 파일의 경로이므로, 경로에 있는 파일을 open
| Hard Link | Soft Link | |
|---|---|---|
| 명령어 | ln origin_file link_name | ln -s origin_file link_name |
| Inode | 동일 | 다름 |
| 내용 | 동일 | 원본의 경로 |
| directory | X (순환 참조 위험) | O |
| 파티션 | 동일한 파티션 내에서만 | 다른 파티션/드라이브 가능 |
| 원본 삭제 시 | reference count가 0이 될 때까지 데이터 유지 | 참조 불가 (링크 깨짐) |
3. File의 이름
1. inode number
- inode : 파일에 대한 정보를 저장하는 구조체
- 각 파일은 하나의 inode number를 가지며, 이는 파일 시스템 내에서 unique함
- 동일한 파일 시스템에서 서로 다른 파일이 같은 inode number을 가진다면 link를 이용한 것임
- 다른 파일 시스템에서는 서로 다른 파일의 inode number가 같을 수 있음
- 파일 시스템은 파일의 이름이 아닌 inode number을 이용함
- 파일과 inode 간의 연결을 삭제하고, inode를 재사용할 수 있음
2. path
- 문자열로 파일의 주소를 나타냄
- inode number보다 친숙함 → 사용자 중심
- directory에 파일의 문자열, 파일의 inode 정보가 맵핑됨
- 경로는 tree 형태의 계층적 구조로 저장됨
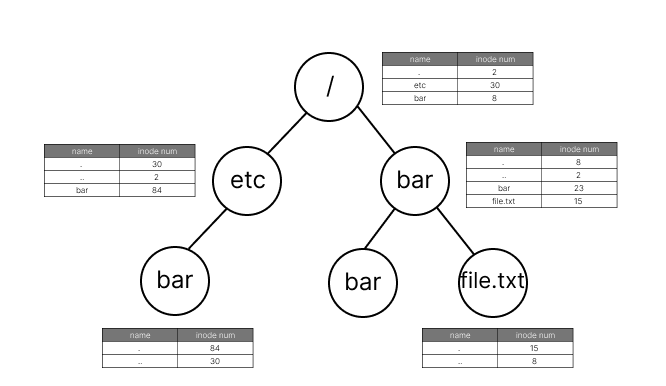
🏃
/bar/file.txt파일을 찾는 과정
1. 보통 1번 혹은 2번 inode는 root inode로 지정됨 (FS마다 상이)
2. 2번 inode를 읽고 해당하는 데이터 블락을 읽음
3./directory의 엔트리에서bar에 해당하는 inode number 찾음 (8)
4. 8번 inode를 읽고 해당하는 데이터 블락을 읽음
5.bardirectory의 엔트리에서file.txt에 해당하는 inode number 찾음 (15)
6. 15번 inode를 읽고 해당하는 데이터 블락을 읽음
7.file.txt의 정보를 읽음!
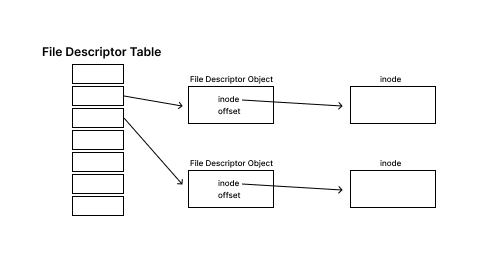
3. file descriptor
- path는 final node를 찾기 위해 traval해야 하기 때문에, 이 횟수를 한 번으로 줄이고자 함
- file descriptor을 open하고, fd에 inode에 대한 포인터와 offset을 저장함
- disk 대신 fd를 이용해 I/O 작업을 수행 → cost 감소
4. Disk 공간 할당
1. Contiguous Allocation
- disk의 연속된 sector에 각 파일을 할당함
- meta data
- 시작 블록
- 파일 크기
- OS가 free space를 찾아 할당함
- IBM OS/360
- 장점
- sequential access 비용이 적음
- overhead 적음
- 단점
- external fragmentation이 많이 발생함
- 빈 공간을 찾아 할당하는 과정이 비효율적일 수도 있음
| fragmentation | external fragmentation | ❌ |
|---|---|---|
| 파일의 크기를 키울 수 있는가 | 일부는 가능 | ➖ |
| sequential access의 비용 | 좋음 | ✅ |
| random access의 속도가 어떤가 | 연산 쉬움 | ✅ |
| meta data의 overhead가 어떤가 | overhead 적음 | ✅ |
2. Small # of Extent
- 파일 별로 연속된 region을 여러 개 할당함
- meta data
- 각 extent를 나타내는 entry를 가지는 array
- 각 entry : 시작 블록, 파일 크기
- 장점
- sequential access 비용이 적음
- overhead 적음
- 1번 방식보다 fragmentation 완화
- 단점
- 로그와 같이 계속해서 확장하는 파일을 담기는 어려움
- external fragmentation → Linked Allocation / Indexed Allocation으로 개선
| fragmentation | external fragmentation 조금 완화 | ❌ |
|---|---|---|
| 파일의 크기를 키울 수 있는가 | extent 한계까지 가능 | ➖ |
| sequential access의 비용 | 굿 | ✅ |
| random access의 속도가 어떤가 | 간단함 | ✅ |
| meta data의 overhead가 어떤가 | 조금 | ✅ |
3. Linked Allocation
- 고정된 크기의 블락 단위로 linked-list 구조 할당
- meta data
- head의 위치
- 다음 블락을 가리키는 포인터
- TOPS-10, Alto
| fragmentation | 없음 | ✅ |
|---|---|---|
| 파일의 크기를 키울 수 있는가 | 가능 | ✅ |
| sequential access의 비용 | 데이터 구조에 따라 다름 | ➖ |
| random access의 속도가 어떤가 | 아주 나쁨 | ❌ |
| meta data의 overhead가 어떤가 | (블록 개수 * 포인터 크기) 만큼 낭비가 생김 | ❌ |
4. File Allocation Table
- linked allocation의 확장
- FAT 테이블에 모든 파일에 대한 linked list 정보를 저장함
- meta data
- 파일의 첫 번째 블락 위치
🏃 file.txt를 읽는 과정
1. 디렉토리를 뒤져서file.txt항목을 찾아 시작 블록 번호(4)를 찾음
2. 4번 블록을 읽고 FAT[4]를 확인 해 다음 읽을 블록 번호(9)를 찾음
3. 9번 블록을 읽고 FAT[9]를 확인
4. FAT[9]가 EOF라면 파일을 다 읽었음을 확인
- 장점
- linked list의 매번 따라가야 하는 문제를 개선 (look up)
- 호환성이 좋음
- 단점
- 한 번 읽을 때마다 look up 두 번 소요
- FAT를 메모리에 cache해서 개선 가능
- 내부 단편화
- FAT에 의존하게 됨
- random access 불가 → Indexed Allocation으로 개선
- 한 번 읽을 때마다 look up 두 번 소요
| fragmentation | 내부 단편화 | ➖ |
|---|---|---|
| 파일의 크기를 키울 수 있는가 | 가능 | ✅ |
| sequential access의 비용 | 데이터 구조에 따라 다름 | ➖ |
| random access의 속도가 어떤가 | 아주 나쁨 | ❌ |
| meta data의 overhead가 어떤가 | FAT table | ❌ |
5. Indexed Allocation
- 고정된 크기의 블락 단위 할당
- meta data
- index block (inode)
- block pointer를 가지는 고정된 크기의 배열
- 이 배열은 파일이 생성될 때 공간이 할당됨
- 디렉토리 엔트리는 인덱스 블록의 주소를 가리킴 (name-inode num mapping)
🏃 file.txt를 읽는 과정
1. 디렉토리를 뒤져서file.txt의 디렉토리 엔트리를 찾아 연결된 inode number(3) 찾음
2. 3번 inode를 읽어 그 안에 있는 포인터 배열을 찾음 [10, 5, 22]
3. 10번 → 5번 → 22번 순서대로 블락을 읽어 데이터를 읽음
- 장점
- external fragmentation x
- random access 성능이 좋음
- inode만 읽으면, 포인터 배열을 이용해 원하는 블록 주소로 바로 점프 가능
- 파일 크기 키울 수 있음
- 빈 블록 찾아서 주소 할당하고 포인터 배열에 블락 주소 append
- 단점
- meta data의 overhead가 큼
- 모든 파일은 인덱스 블락 하나를 반드시 할당받아야 함
- 파일 크기 제한
-
인덱스 블락 하나에 저장할 수 있는 포인터 개수가 한정되어 있음
→ Multi-level Indexing으로 개선
-
- meta data의 overhead가 큼
| fragmentation | 내부 단편화 | ➖ |
|---|---|---|
| 파일의 크기를 키울 수 있는가 | 가능 | ✅ |
| sequential access의 비용 | 인덱스 읽고 블락 접근 | ➖ |
| random access의 속도가 어떤가 | 좋음 | ✅ |
| meta data의 overhead가 어떤가 | 파일마다 인덱스 블록 할당 | ❌ |
6. Multi-level Indexing
- indexed allocation의 변형
- 필요에 따라 block 계층을 동적으로 할당함
- 최대 개 사용 가능
- 12개의 포인터는 맨 처음 블락에 직접 저장함 (데이터 블락 가리킴)
- 13번째부터는 인덱스 블락을 가리키는 인덱스 블락을 가리킴 → 단일 간접
- meta data
- 포인터 개수는 FS마다 상이함 (아래 예시는 리눅스 EX2 기준)
- 직접 블록 12개
- 초기에 static하게 할당됨
- 단일 간접 블록
- 13번째 포인터가 필요할 때 동적으로 할당됨
- 인덱스 블록, 즉 포인터 배열을 가리킴
- 이중 간접 블록
- 14번째 포인터가 필요할 때 동적으로 할당됨
- 인덱스 블록을 가리키는 인덱스 블록을 가리킴
- 삼중 간접 블록
- UNIX FFS-based file system, ex2, ex3
- 장점
- 불필요한 포인터에 대한 낭비가 없음
- 빠른 접근
- 단점
- indirect block 포인터를 계산하기 위한 disk access 횟수가 커짐
- 메모리 캐시 도입 시 속도 개선 가능
- indirect block 포인터를 계산하기 위한 disk access 횟수가 커짐
5. File System의 구조
1. Super Block
- 파일 시스템의 기본적인 크기나 형태에 대한 정보를 저장함
- 파일 시스템은 해당 블록의 정보를 이용해 파일 시스템을 활용하고 유지함
- block size
- inode 개수
- root(
/)의 inode number
- 해당 sector에 대해 오류가 뜨면 해당 디스크는 사용할 수 없음
- 나머지 정보 중 읽을 수 있는 정보를 읽어 rebuild하면 recovery 일부 가능
2. Bitmap
- Block Bitmap
- 블록의 할당 상태를 나타냄
- inode Bitmap
- inode의 할당 상태를 나타냄
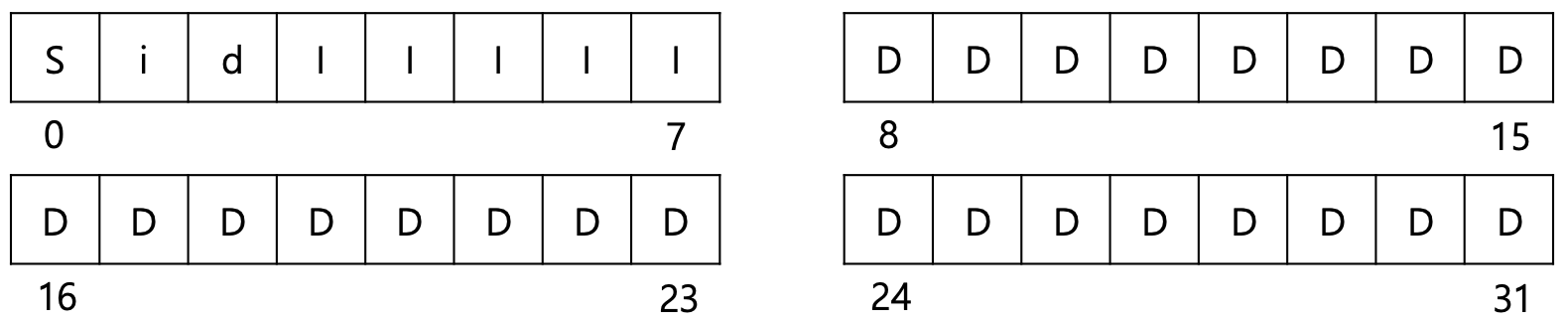
3. inode
- 파일에 대한 정보를 저장하는 구조체
- 고유 number를 가지고, 이는 file system 내에서 unique함
- 보통 256byte 단위
- disk block 크기가 4KB라면 한 block에 16개 들어감
- 삭제 후, 재사용 가능
ls -i
| number | 해당 inode의 파일 시스템 내부에서의 고유한 번호를 가리킴 |
|---|---|
| size | 파일 사이즈 (Byte 단위) |
| mode | 파일의 모드, 접근 권한 정보, 파일 종류, 스티키 비트 |
| link | 링크된 파일 개수 등의 정보 |
| time stamp | 생성된 시간, 수정된 시간 |
| data block pointer | 가리키는 data block에 대한 포인터 |
| sector address | 파일이 존재하는 실제 디스크의 위치 정보 |
4. Data Block
- 데이터를 저장함
6. File API
1. Create
/etc/file.txt
- root inode Read
- root data Read
/directory entry에서 etc directory의 inode number 확인
- etc inode Read
- etc data Read
- file.txt라는 이름이 이미 중복되어 있는지 확인
- inode bitmap Read
- 빈 inode를 찾음
- inode bitmap Write
- 빈 inode에 대한 정보 작성
- etc data Write
- file inode에 대한 경로 + inode directory entry 추가
- file inode Read
- 기존 invalid한 데이터가 남아있지 않은지 확인
- file inode Write
- 파일 정보 작성
- etc inode Write
- etc data의 파일이 수정되었으므로, updated time 수정
2. Open
- root inode Read
- root data Read
- etc의 inode number 확인
- etc inode Read
- etc data Read
- file의 inode number 확인
- file inode Read
3. Write
- file inode Read
- data bitmap Read
- data bitmap Write
- file data Write
- file inode Write
4. Read
- file inode Read
- file data Read
- file inode Read
- last accessed time update
5. Close
- disk상의 수행은 없음
- file descriptor close
