✨ 본 포스트는 CONCEPTS OF PROGRAMMING LANGUAGES 교재를 기반으로 작성되었습니다
Language implement System은 구현 방법과 관계없이, 소스 코드 분석을 요구한다
이를 위한 모든 구문 분석은 BNF, 즉 소스 코드의 Sytax를 기반으로 한다
Syntax Analyzer은 크게 두 종류로 분류된다
1. Lexical Analysis
2. Syntax Analysis
1. Lexical Analyzer
1-1. Lexical Analyzer?
- pattern matcher for strings
- 프로그램의 문자열을 인식해 lexeme을 추출 -> 토큰 분석
- parser가 단어마다 LA를 호출해가며 파싱을 함
- 파서가 요청할 때마다 토큰을 분석함
- lexical category는 프로그래머의 마음에 따라 달라질 수 있음
- lexical analyzer 구성을 위한 3가지 방법
- 1️⃣ table 기반 소프트웨어 사용
- 토큰에 대한 formal description 작성
- 저장된 내용을 기반으로 간략하게 패턴 매칭
- 2️⃣ 모든 경우에 대한 state diagram을 그린 후 state diagram을 구현하는 소스 프로그램 작성
- 경우의 수가 너무 많음
- 3️⃣ 토큰을 설명하는 state diagram을 설계 후 state diagram의 테이블 기반 구현 구성
- 1번 + 2번
- 타입에 따라 상태 구분(number, char)
- 대소문자 구분 X, 숫자 값 구분 X
- reserved words
- table로 저장해두고, 값이 들어오면 table loopup을 통해 인지
- state를 최소화함으로써 analyzer 최적화
- 1️⃣ table 기반 소프트웨어 사용
1-2. Parser & AST
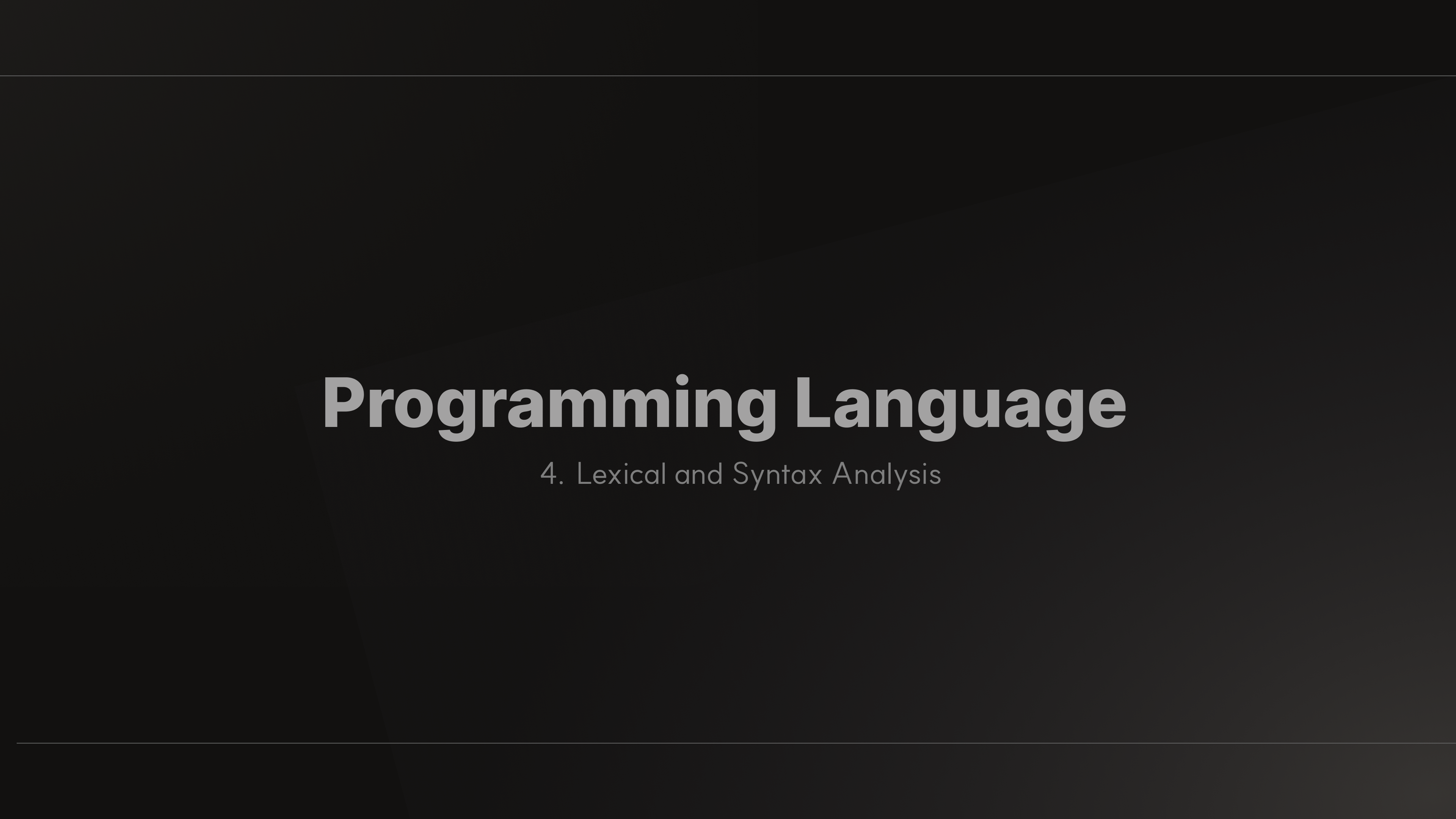
source program 구문 분석의 과정
- lexical analyzer
- input string을 읽고 token으로 분리해 반환
- parser
- input string parsing
- syntax analyzer -> Syntax Error를 찾음
- input에 대한 AST를 생성해 반환
- AST
- 추상 구문 트리
- input string의 구문 구조를 추상적으로 보여주는 트리
- interpreter
- AST를 순회하며 문장의 의미를 따라 해석
- AST를 순회하며 문장의 의미를 따라 해석
2. Parsing Problem
Parser는 AST를 생성하며 동시에 Syntax Error을 찾아내야 하며, 크게 두 가지 종류로 구분할 수 있다
2-1. Top-Down
- root 에서부터 트리 생성
- leftmost derivation
- Trace of Build Parse Tree
LL Parser- table driven implementation
recursive Descent- code implementation
- xA 라는 sentential form이 주어짐
- 첫번째로 나오는 token만을 사용함
- 어떤 derivation rule을 써서 파싱할건지를 결정
2-2. Bottom-Up
- leaf 에서부터 트리 생성
- rightmost derivation의 결과를 보고 역순으로 트리를 생성
- tool의 도움 필요
- input scan 후 필요한 정보를 table에 저장
- 해당 정보를 기반으로 트리를 생성함
LR Parser- 뒤에서부터 sentence → sentential form → start sentential form 으로 이동
3. Recursive-Descent Parsing
3-1. RD Parser
- non-terminal 하나하나에 매칭되는 함수 생성
- BNF | EBNF를 보고 그대로 code implementation
- non-terminal 하나마다 함수를 작성해야 하기 때문에, EBNF 사용이 권장됨
- function
- EBNF form 자체를 그대로 코드로 구현함
- non-terminal이 발견되면, 그에 매칭되는 함수를 호출함
- terminal이 발견되면, 그 자리에서 lexeme 혹은 token을 처리함
- 하나 이상의 RHS가 있는 Rule은 어떤 RHS를 분석할지 결정하는 Process가 필요함
s → a | b | c: N개의 RHS 중 하나 택
s → ab | bc | bb: 하나 택하는 과정이 복잡해짐- RHS에 겹치는 non-terminal 요소가 많아질 수록, RHS 개수가 많아질 수록 복잡도 ⬆️
- 복잡도가 높아질수록 RD Parser으로 구현 불가
- BNF 변경
- LL | LR Parser 사용
3-2. EX) RD Parser
<expr> -> <term> {(+ | -) <term>}
<term> -> <factor> {(* | /) <factor>}
<factor> -> id | int_constant | ( <expr> )위와 같은 Grammar가 있다고 했을 때, 아래는 위의 Grammar를 통해 (sum + 47)/total 이라는 sentence를 파싱하는 과정이다
<expr> -> <term>
-> <factor> / <factor>
-> ( <expr> ) / <factor>
-> ( <term> + <term> ) / <factor>
-> ( <factor> + <term> ) / <factor>
-> ( id + <term> ) / <factor>
-> ( sum + <term> ) / <factor>
-> ( sum + int_constant ) / <factor>
-> ( sum + 47 ) / <factor>
-> ( sum + 47 ) / id
-> ( sum + 47 ) / total
4. LL Parsing
4-1. LL Parsing
- topdown & leftmost derivation
- parsing table, input buffer 사용
- stack을 사용하기 때문에 LR Parser와 비슷한 구조를 띰
- 동작 과정
- input을 스택에 넣음
- parse table의 요소에 해당하게 만들 수 있는지 확인
- 그렇다면 production rule을 이용해 해당 요소로 derivation
- LHS를 RHS로 expand하면서 parse tree를 만들어나감
4-2. Left Recursion Problem
🚨 BNF에서 Left Recursion이 생기면 LL Parse는 무한 루프에 빠질 가능성이 있음
→ Left Recursion이 생기는 문법은 LL | RD Parser로는 구현할 수 없음
→ BNF 자체를 바꿔야 함 | LR Parser로 구현

⬆️ 무한 루프에 걸릴 위험성이 있는 BNF를 수정해 위험성을 없앤 예시
4-3. Pairwise Disjointness Test
-
top-down parser가 구현이 안되는 경우 중 하나는 pairwise disjointness가 부족한 경우임
- 여러 개의 RHS가 존재할 때, 하나의 lookahead token으로 올바른 RHS를 선택할 수 없음을 뜻함
정의
- 맨 앞에 처음 나오는, 즉 가장 왼쪽에 나온 token이 라면, 이에 대해 를 정의함
- 를 BNF의 production rule을 적용시켜 left derivation 할 때, 가장 왼쪽에 나올 수 있는 terminal의 집합
- 즉, 맨 왼쪽에 나오는 모든 terminal은 에 속함
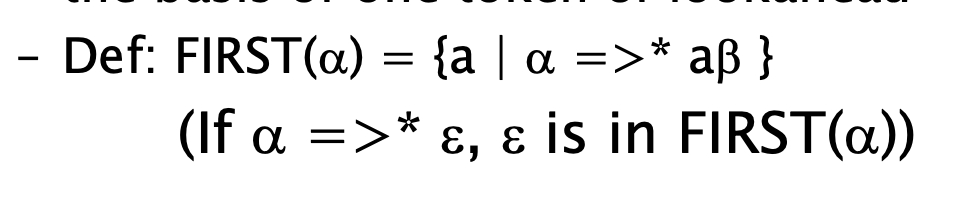
Pairwise Disjointness Test
- 가장 왼쪽에 나올 수 있는 터미널이 똑같이 나오는 경우가 2개 이상 나오면 안됨
- 같은 터미널은 반드시 하나의 경우에 의해서만 derivation되어야 하며, 이 경우에만 parse tree를 만들 수 있음

- TEST 성공
A -> aB | bAb | Bb
B -> cB | d- TEST 실패
A -> aB | BAb
B -> aB | b5. Bottom-Up Parsing
5-1. Bottom-Up Parsing
- 아래서부터 위로 parse-tree를 생성함
- rightmost derivation의 역순 → 테이블 이용함
handle- 역순으로 올라올 수 있는 terminal과 non-terminal의 조합
- 일 때 를 찾는것
- rule을 반대로 적용함
simple phrase에 해당됨- 한 번만 했을 때 오른쪽의 sentential form이 나왔다면 는 에 대하여 simple phrase임
- 장점
- left recursion이 나와도 동작함
- pairwise disjointness test에 실패하는 BNF도 동작할 수 있으며 아주 강력함
- Stack, Input Buffer이 필요함
- ACTION, GOTO 에 적혀진 동작을 수행함
- Reduce : 구문 분석 스택 상단의 핸들을 해당 LHS로 교체
- Shift : 다음 토큰을 구문 분석 스택 상단으로 이동
가장 왼쪽에 있는 handle을 production rule의 역으로 대치해 나가며 파싱을 진행함
→ 실제로 적용하기에는 쉽지않음
→ 실제로는 shift, reduce 알고리즘을 기반으로 동작함
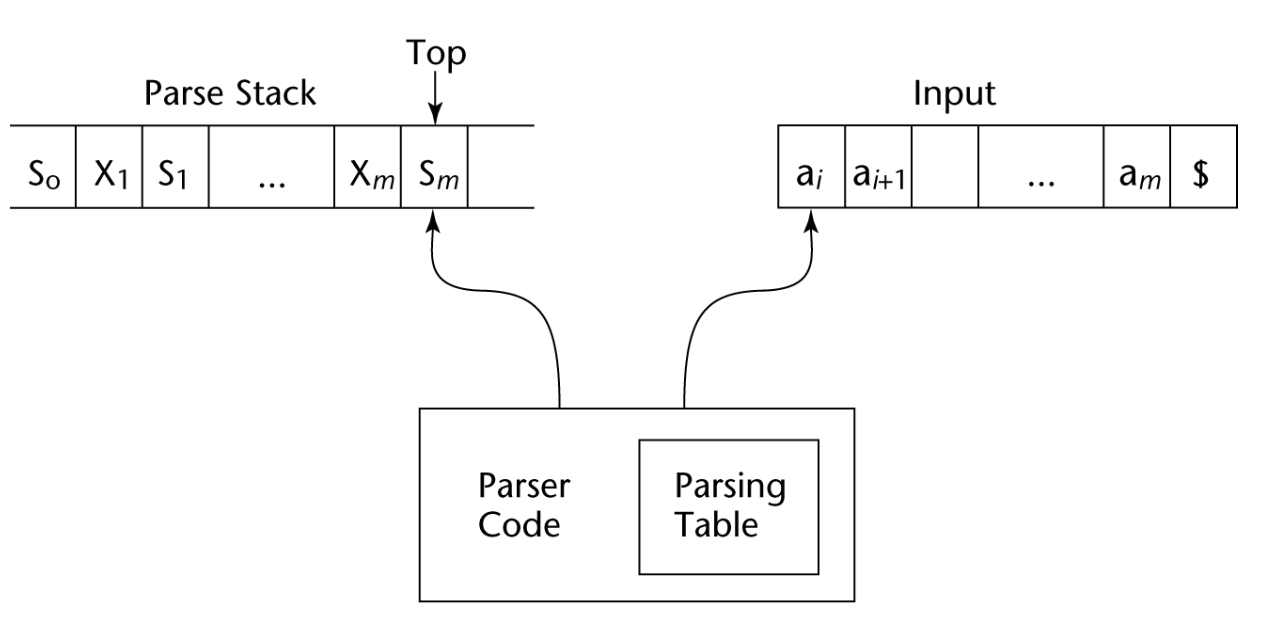
5-2. Structure of LR Parser : Parse Stack
- Parse Stack
- S0 ~ $ 으로 처음과 마지막을 기록
- input으로 String이 들어오면 Stack에 push
- 테이블을 기반으로 stack에 상태(s)와 토큰(x)을 번갈아 넣으며 동작함
0E1+6T9*7F10- 상태0 - 토큰E - 상태1 - 토큰+ - 상태6 - 토큰T - 상태9 - 토큰* - 상태7 - 토큰F - 상태10
5-3. Structure of LR Parser : Parse Table
- software tool이 도와줌
- BNF를 입력하면 그에 해당하는 파서의 파싱 테이블이 주어짐
- S = shift
- shift한 번호를 뒤의 상태로 지정
- stack의 상태 변경
- Input string의 값 버리기
- GOTO X
- R = reduce
- BNF rule 번호에 의해 reduce
- n번 production rule에 따라 RHS를 LHS로 reduce
- GOTO를 항상 같이 봐야함! → 상태 변경
- Input string 값 유지
- ACCEPT
- parse-tree를 bottom-up으로 LR Parser를 통해 만들기를 성공함
- Input string에 $만 있고 Accept를 만나야 끝남
- 공란에 오는 경우 = SYNTAX ERROR
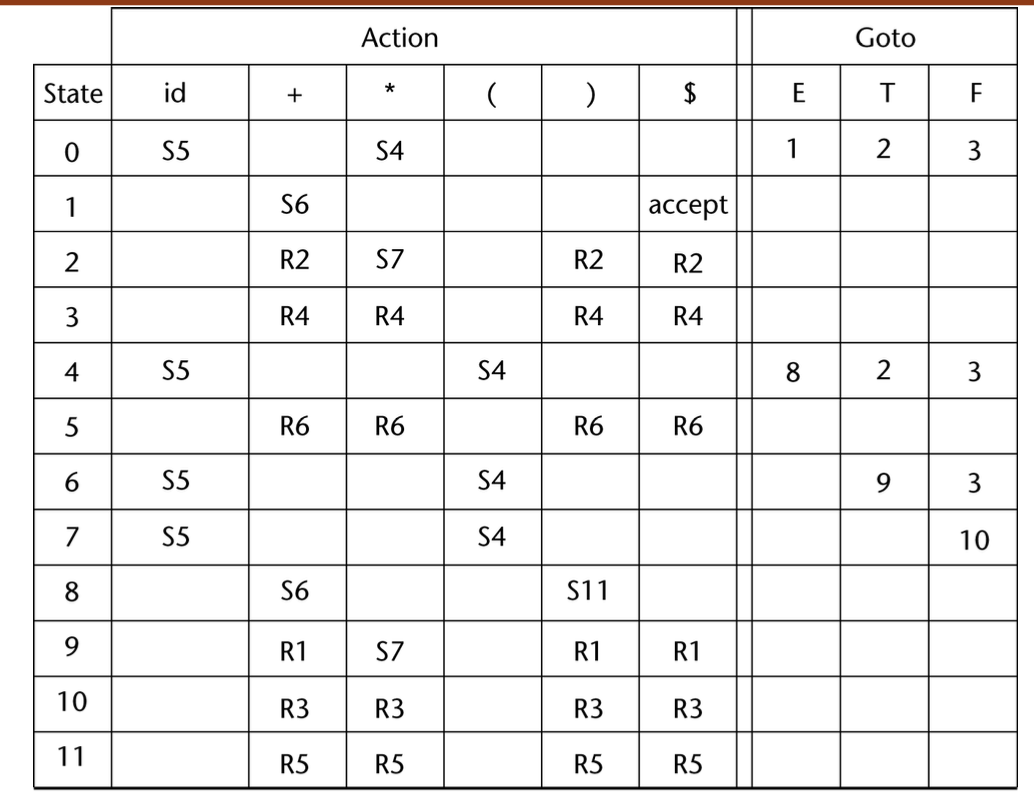
5-4. EX) Process of LR Parsing
| Stack | Input | Action | Description |
|---|---|---|---|
| 0 | id+id*id$ | Shift 5 | push id token to stack / set state 5 |
| 0id5 | +id*id$ | Reduce 6 (use GOTO[0,F]) | token을 F로, state를 3으로 변경 |
| 0F3 | +id*id$ | Reduce 4 (use GOTO[0,T]) | token을 T로, state를 2으로 변경 |
| 0T2 | +id*id$ | Reduce 2 (use GOTO[0,E]) | token을 E로, state를 1으로 변경 |
| 0E1 | +id*id$ | Shift 6 | push + token to stack / set state 6 |
| 0E1+6 | id*id$ | Shift 5 | push id token to stack / set state 5 |
| 0E1+6id5 | *id$ | Reduce 6 (use GOTO[6,F]) | token을 F로, state를 3으로 변경 |
| 0E1+6F3 | *id$ | Reduce 4 (use GOTO[6,T]) | token을 T로, state를 9으로 변경 |
| 0E1+6T9 | *id$ | Shift 7 | push * token to stack / set state 7 |
| 0E1+6T9*7 | id$ | Shift 5 | push id token to stack / set state 5 |
| 0E1+6T9*7id5 | $ | Reduce 6 (use GOTO[7,F]) | token을 F로, state를 10으로 변경 |
| 0E1+6T9*7F10 | $ | Reduce 3 (use GOTO[6,T]) | token을 T로, state를 9으로 변경 |
| 0E1+6T9 | $ | Reduce 1 (use GOTO[0,E]) | token을 E로, state를 1으로 변경 |
| 0E1 | $ | Accept | Success to Parsing |
