1. K-Means 클러스터링이란 ?
K-Means 클러스터링은 비지도 학습(Unsupervised Learning) 의 일종으로, 주어진 데이터를 K개의 군집(Cluster)로 묶는 알고리즘이다.
비지도 학습(Unsupervised Learning) 이란 정답이 없는 데이터를 가지고 컴퓨터를 학습시키는 방법이다.
( 문제와 정답이 없다는 말 )
각 군집은 하나의 중심(Centroid)을 가지며, 데이터들은 가장 가까운 중심에 속하게 된다. 이 알고리즘의 목표는 각 데이터 포인트와 해당 군집의 중심 사이의 거리의 제곱의 합을 최소화 하는 것이다.
2. 알고리즘 원리
K-Means 클러스터링 알고리즘은 다음과 같은 단계를 따른다.
- 초기화 (Initialization)
- 먼저 몇 개의 군집으로 나눌지 K 값을 설정한다.
- K 개의 중심점(Centroid)을 데이터 공간에 배치한다. ( 데이터 중 무작위로 K개를 선택한다. )
- 할당 (Assignment)
- 모든 데이터 각각에 대하여, K개의 중심점까지의 거리를 모두 계산한다.
- 각 데이터는 가장 가까운 중심점을 "자신의 중심점"으로 선택하고 해당 군집에 소속 된다.
- 업데이트 (Update)
- 각 군집의 중심점을 해당 군집에 속한 모든 데이터 포인트들의 평균 위치로 이동시킨다.
- 반복(Iteration)
- 2,3 단계를 반복한다.
- 중심점의 위치가 더 이상 변하지 않을때 알고리즘을 종료한다.
3. Numpy 를 이용한 구현
import numpy as np
import matplotlib.pyplot as plt
def initialize_centroids(data, k):
# 데이터 중 무작위 K개의 점을 초기 중심점으로 선택한다.
indices = np.random.permutation(data.shape[0])
centroids = data[indices[:k]]
return centroids
def assign_to_cluster(data, centroids):
# 데이터를 가장 가까운 중심점에 할당
distances = np.sqrt(((data - centroids[:, np.newaxis])**2).sum(axis=2))
return np.argmin(distances, axis = 0)
def update_centroids(data, labels, k) :
# 각 클러스터의 평균 지점으로 중심점을 업데이트
new_centroids = np.array([data[labels == i].mean(axis = 0) for i in range(k)])
return new_centroids
def kmeans(data, k, max_iterations=100) :
# K-Means 알고리즘
centroids = initialize_centroids(data, k)
for _ in range(max_iterations) :
labels = assign_to_cluster(data, centroids)
new_centroids = update_centroids(data, labels, k)
# 중심점이 변하지 않으면 종료
if np.all(centroids == new_centroids):
break
centroids = new_centroids
return labels, centroids
if __name__ == '__main__':
# 실습용 2차원 가상 데이터 100개 생성
np.random.seed(42)
data = np.random.rand(100,2)
# K-means 알고리즘 실행
k = 4
labels, centroids = kmeans(data, k)
# 결과 시각화
plt.figure(figsize=(8,6))
colors =['#e6194B','#3cb44b','#ffe119','#4363d8']
for i in range(k):
cluster_data = data[labels ==i]
plt.scatter(cluster_data[:,0], cluster_data[:,1], c=colors[i], label=f'Cluster {i+1}')
plt.scatter(centroids[:,0], centroids[:,1], s=200, c='black',marker='*',label='Centroids')
plt.title('K-Means Clustering Result')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.grid(True)
plt.show()initialize_centroids(data,k): 초기 중심점 K개를 무작위로 설정한다.np.random.permutation(data.shape[0]): data 리스트의 인덱스를 무작위로 섞는다.
assign_to_cluster(data, centroids): 모든 데이터 포인트를 현재 자신과 가장 가까운 중심점에 배정한다.centroids[:,np.newaxis]: 중심점 배열centroid의 차원을(k,2)에서(k,1,2)로 변경한다. 이때,data배열의 차원은(100,2)이다.data - centroids[...]: 브로드캐스팅(Broadcasting)이 작동하여(100,2)크기의 데이터에서(k,1,2)크기의 중심점을 뺀다. 그 결과(k,100,2)크기의 배열이 생성되는데, 이는 k개의 각 중심점과 100개의 모든데이터 사이의 x,y 좌표 차이를 담고 있다.np.sqrt(...): 각 좌표의 차이를 제곱하고axis=2(x,y축)기준으로 더하고 루트를 씌워 유클리드 거리를 계산한다. 결과는(k,100)크기의 배열이 된다.np.argmin(distances,axis=0):(k,100)거리 배열에서axis =0(열 기준)으로 최소값의 인덱스를 찾는다. 최종적으로(100,)크기의 각 데이터가 속한 군집의 번호가 담긴 배열을 반환한다.
update_centroids(data,labels,k): 각 군집의 새로운 중심점을 계산한다.data[labels == i]: 불리언 인덱싱(boolean indexing) 을 사용하여labels배열에서 값이i인 위치를 찾아data배열에서 해당 위치의 데이터들만 추출한다. 즉,i번 군집의 요소들만 추출한다..mean(axis = 0)(열기준): 추출된 데이터를 열 기준으로 산술 평균을 구해 새로운 중심 좌표를 반환한다.
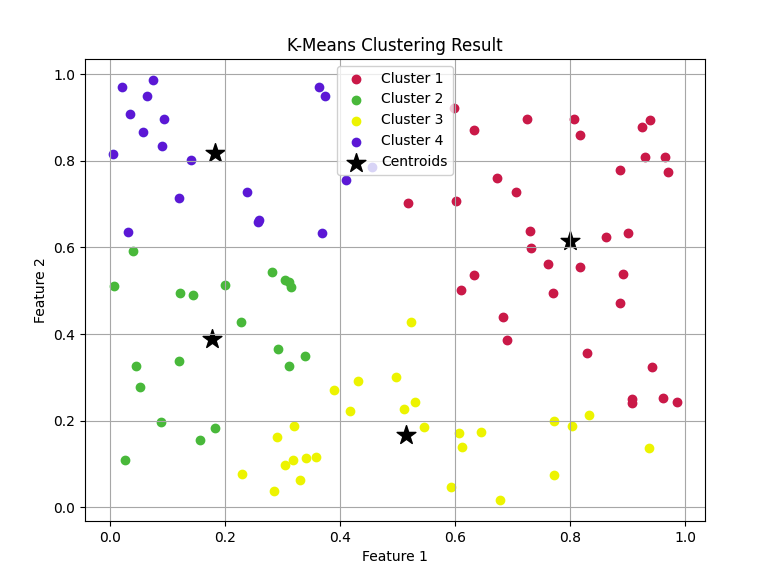
- 시각화된 클러스터링 결과이다.
만약 데이터의 수를 100개가 아닌 10,000개로 한다면 ?
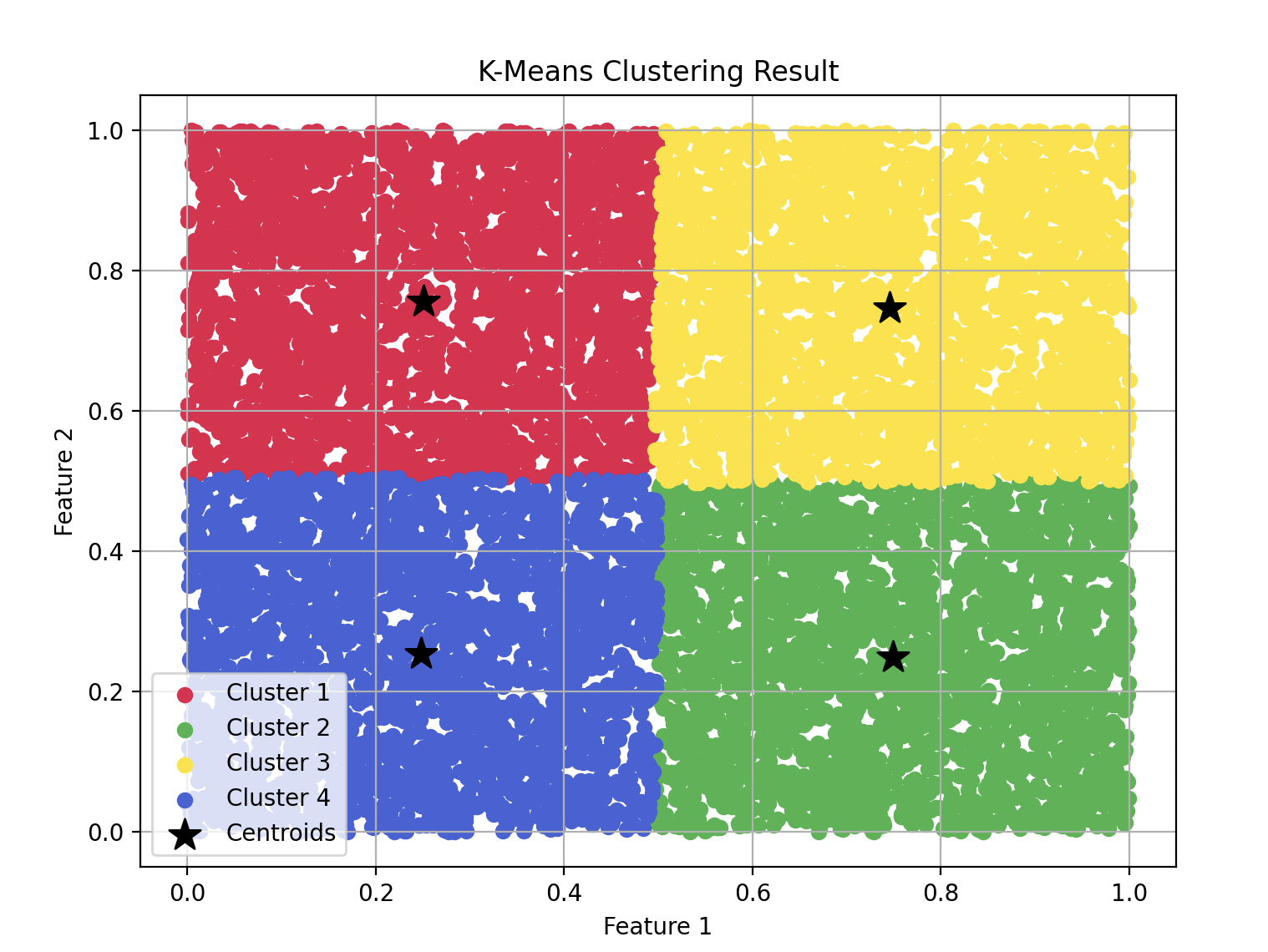
이런 결과가 나타난다 !!! ㄷㄷ...

Bioinformatics and Data science