1. Q-Learning 이란?
Q-Learing은 Reinforcement의 대표적인 가치 기반(Value-based) 알고리즘이다.
- 핵심 : "어떤 상태(state)에서 어떤 행동(Action)을 하는 것이 얼마나 좋은가?" 를 Q값으로 학습하는 것이다.
- 목표 : Agent가 Q-Table를 작성하게 하고, 완성된 Q-Table을 활용하여 어떤 상태에 있든 Q-값이 가장 높은 행동(High Value)을 하게 하는 방식이다.
- 학습 방식 : 탐험과 Q값을 활용한 행동을 반복한다.
- 에이전트가상태 S에서행동 A를 한다.- 환경으로부터
보상 R과다음 상태 S'를 받는다. (S , A, R, S')을 바탕으로 Q-table을 업데이트 한다.
- 환경으로부터
2. Bellman Equation (벨만 방정식)
벨만 방정식은 Q-Table을 업데이트하는 공식이다.
그리고, 목표 Q값은 다음 과 같이 계산된다.
3. Q-Table
Q-Table 은 Q-Leaning의 가치 저장소 인 행렬이다.
- ROW : 환경의 모든 가능한 상태
- COL : 할 수 있는 모든 행동
- Value() :
s상태에서a행동을 했을 때,미래까지 포함하여 받을 것으로 기대되는 총 보상의 합
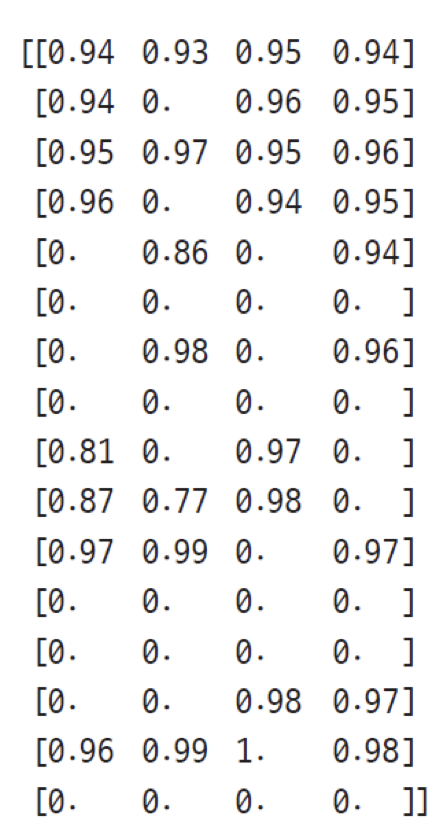
다음은 아래에서 설명할 FrozenLake를 학습한 에이전트의 Q-Table이다.
- 첫번째 요소를 보면,
상황0에서L/D/R/U 행동을 했을 때 얻을수 있는 기댓값이 표시되어있다. - 에이전트는 다음 값을 참고하여 가장 높은 행동인 Right 방향으로 이동할 것이다.
4. FrozenLake Game을 활용한 예시
FrozenLake 게임은 S에서 시작하여 G에 도착하면 이기는 게임으로, F는 지나갈수있으나, H에 도착하면 지는 게임이다.
- Agent 입장에서, F,G는 숨겨져있다.
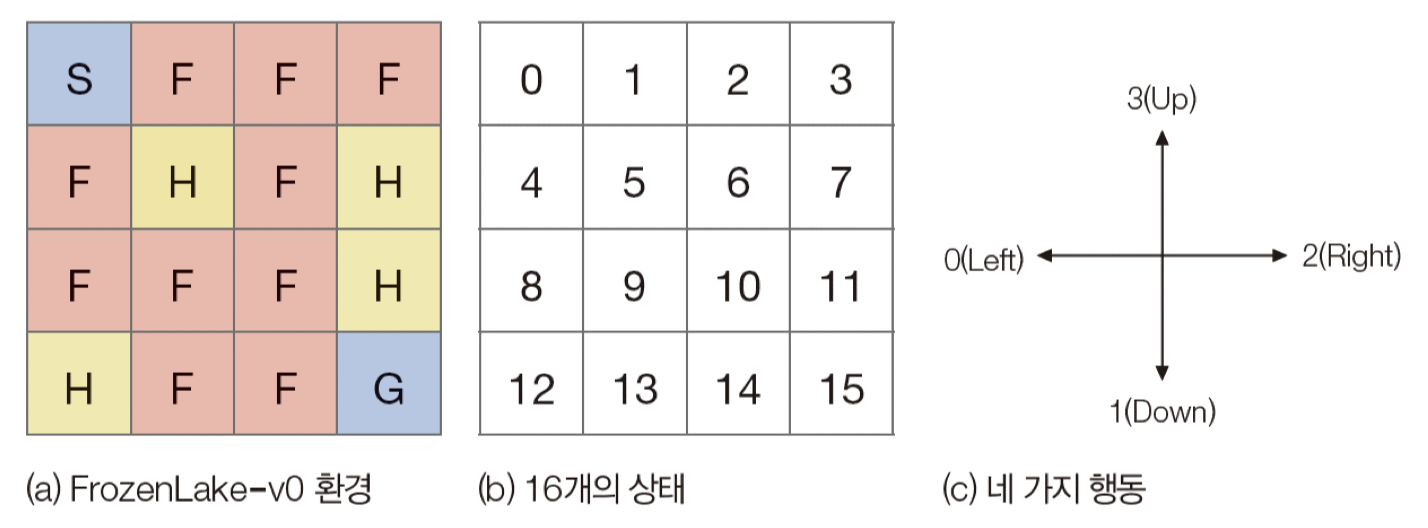
- 44 게임 기준으로, 상태는 16가지, 행동은 4가지(Left,Down,Right,Up)가 있으므로 Q-Table의 크기는 164 행렬이다.
학습중에는, Epsilon-Greedy방식을 채택하였다.
Epsilon-Greedy 정책
이 정책은 학습중에는 탐험과 활용을 적절히 섞어야한다는 것이다.
epsilon: 탐험을 할 확률
if random.uniform(0,1) < epsilon :
탐험 행동을 한다 !
else :
활용 행동을 한다 !학습 초기에는 epsilon을 1.0으로 두엇다가, episode가 진행될수록 줄여나간다.
다시 돌아와서..
아무튼 .. 이런 방식으로 학습을 하고 완성된 16*4 사이즈의 Q-table을 보고, 우리는 최대요소들만을 골라 최적 경로를 찾을 수 있다. 이를 최적 정책(Optimal Policy) 라고 한다.

다음과 같이 해석할 수 있다.
- (0,0) 상태에서, 최적의 행동은 2(right)이다.
5. 코드 구현
import gymnasium as gym
import numpy as np
import random
import time
# 1. Environment Setting
env = gym.make("FrozenLake", is_slippery=False)
# Q-Table init
q_table = np.zeros((env.observation_space.n, env.action_space.n))
# 2. Hyperparameter
num_episodes = 20000
alpha = 0.1 # Leaning Rate
gamma = 0.99 # Discount Factor
# Epsilon - Greedy
epsilon = 1.0
max_epsilon = 1.0
min_epsilon = 0.01
decay_rate = 0.0005 # Epsilon 감소율
# 3. Q-Learning
print("Training Started ...")
for episode in range(num_episodes):
state, info = env.reset()
done = False
while not done:
if random.uniform(0, 1) < epsilon:
action = env.action_space.sample() # 탐험 : 무작위 행동
else:
action = np.argmax(q_table[state, :])
new_state, reward, terminated, truncated, info = env.step(action)
done = terminated or truncated
# Q값 업데이트 - 벨만 방정식 사용
q_table[state, action] = q_table[state, action] + alpha * \
(reward + gamma *
np.max(q_table[new_state, :]) - q_table[state, action])
state = new_state
epsilon = min_epsilon + (max_epsilon - min_epsilon) * \
np.exp(-decay_rate * episode)
print("Training Finished")
print("final Q-Table")
print(np.argmax(q_table, axis=1).reshape(4, 4))
env.close()
# 4. 학습된 에이전트 실행 (검증)
print("\n--- Evaluating Trained Agent ---")
env_eval = gym.make("FrozenLake", is_slippery=False, render_mode="rgb_array")
state, info = env_eval.reset()
done = False
while not done:
# 검증 시에는 Epsilon-Greedy를 쓰지 않고, 오직 Q-Table에서 가장 좋은 행동만 선택
action = np.argmax(q_table[state, :])
new_state, reward, terminated, truncated, info = env_eval.step(action)
done = terminated or truncated
state = new_state
print("Evaluation finished.")
print(f"Final reward: {reward}")
env_eval.close()

Bioinformatics and Data science