컴파일러를 구현해보자.
컴파일: 언어를 다른 언어로 바꿔주는 과정
컴파일러: 컴파일 소프트웨어 도구
다시 말해서, 어떤 언어의 전체를 한번에 읽어들여 다른 언어로 바꿔주는 일종의 번역기라고 생각하면 된다.
방향은 다음과 같다.
C, C++ 과 같은 소스코드 → 기계어로 변환
그러기 위해선, 우리는 고수준 언어인 C, C++과 같은 코드를 기계어로 번역하기 위한 중간 단계의 코드를 작성해야 하는데, 그게 Assembly이다.
과정은 다음과 같다.
고수준 언어 → Assembly Language → binary code
이 컴파일 과정속에 총 4단계의 과정이 진행되는데, 하나씩 살펴보자.
hello.c 코드
#include <iostream>
int main() {
std::cout << "hello world!\n";
return 0;
}이 코드는 전처리 과정을 거친다.
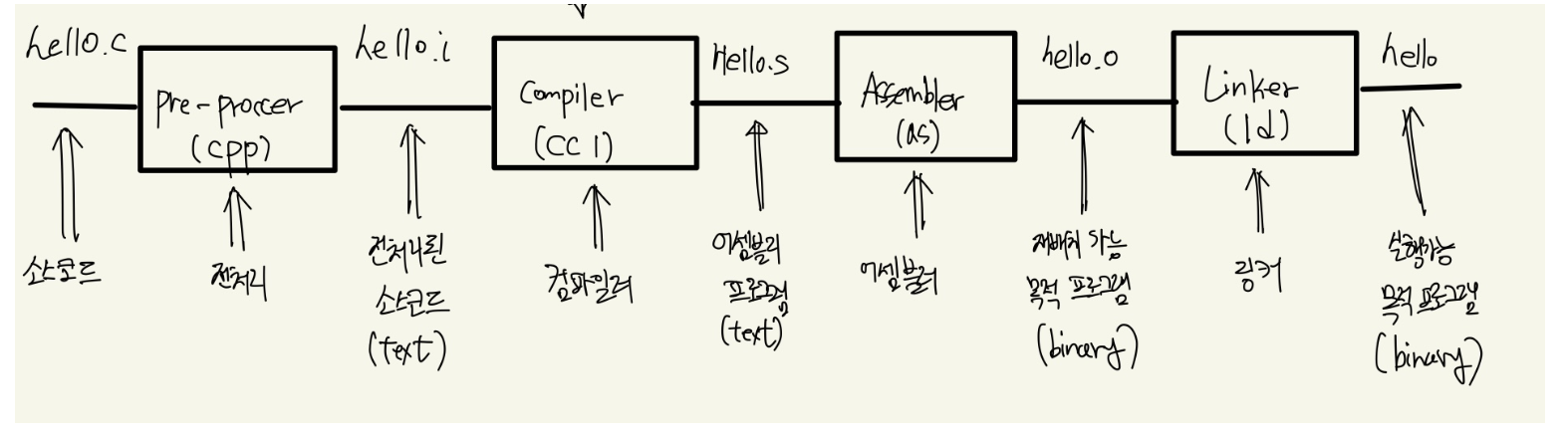
1단계, 전처리
pre-processor(전처리) 단계에서는 다음과 같은 작업을 진행한다.
- 매크로 처리
- 주석 제거
- 조건부 컴파일 처리
단순 텍스트 치환작업만 한다(그냥 필요한것만 추출해내는 거라고 생각)
2단계, 컴파일
Compiler를 통해서 고수준 언어를 어셈블리 언어로 변경한다.
이제 우리가 해야할 일이다. 이 단계에선 다음과 같은 작업이 이루어진다.
- Lexical Analysis (Lexer / Tokenizer) → 문자열을 토큰 단위로 쪼갠다.
- Syntax Analysis (Parser) → 토큰을 기반으로 AST 구축
- Semantic Analysis → 타입 검사, 스코프 체크 등 의미적 타당성 검사
- IR 생성 & 최적화 → LLVM IR과 같은 중간 단계로 변경하고 최적화 한다.
- Target 코드 생성: 어셈블리 코드 생성
이걸 우리가 다 할 것이다.
3단계, 어셈블러
어셈블리 → 목적코드로 변환시키는 단계
4단계, 링커
여러 Object파일들을 묶어서 실행가능한 파일로 생성
그러면, 어차피 컴파일을 만들거니까, 컴파일의 순서대로 한번 구현해보자.
컴파일러 만들기
간단한 계산기 컴파일러를 만들어보자.
-
Lexical Analysis (Lexer / Tokenizer) → 문자열을 토큰 단위로 쪼갠다.
- 12 + 34 를 받는다고 생각하자.
- 담겨야 하는 결과는 다음과 같다.
1. 12 → {NUMBER, "12"} 2. + → {PLUS, "+"} 3. 34 → {NUMBER, "34"} 4. 입력 끝 → {END, ""}
그러면 고려사항은 다음과 같다.
- 각 TokenType를 정의해주고, 그 값을 넣어준다. (Type, Value)
- 문자열을 파싱할때, 공백을 제거해주고, 타입 기준으로 나누어준다. 단지 이 2개를 통해서 Lexer 클래스를 만들어보자.
일단 Token먼저 정의하자.
enum class TokenType { NUMBER, PLUS, MINUS, MUL, DIV, LPAREN, RPAREN, END };} struct Token { TokenType type; string value; }각 string을 pos변수를 가지고 파싱할 char를 추출해내자.
일단 기본적으로 두가지 함수만 구현하고 시작하자.
- 빈값인 경우
bool is_space(char c){ return c == ' ' || c == '\t' || c == '\n' || c == '\r' || c == '\f' || c == '\v'; }- 숫자인 경우
bool is_digit(char c){ return '0' <= c && c <= '9'; }- 마지막으로, 생성자까지만
Lexer(const string& input) { this->text = input; }
이제 제대로된 파싱을 해볼 차례이다.
Token getNextToken() {
while(pos < this->text.size()){
char c = text.at(pos);
if(is_space(c)){
pos++;
continue;
}
if('0'<=c && c<='9'){
string num = "";
while( pos < this->text.size() && (is_digit(text.at(pos)))){
num = num + text.at(pos++);
}
return {TokenType::NUMBER, num};
}
if(c == '+'){
pos++;
return {TokenType::PLUS, "+"};
}
if(c == '-'){
pos++;
return {TokenType::MINUS, "-"};
}
if(c == '*'){
pos++;
return {TokenType::MUL, "*"};
}
if(c == '/'){
pos++;
return {TokenType::DIV, "/"};
}
if(c == '('){
pos++;
return {TokenType::LPAREN, "("};
}
if(c == ')'){
pos++;
return {TokenType::RPAREN, ")"};
}
throw runtime_error("Invalid character");
}
return {TokenType::END, ""};
}일단, text를 받으면, pos를 통해서 문자열 하나하나 파싱을 진행하는데, 우리가 종료조건으로 따질것은, 딱 한개이다. segment fault가 발생하지 않을 문자열의 크기만을 이용하고, 이제 세부적인건 세부조건에 따라 변형하면 된다.
12+34는 12, +, 34로 토큰형태로 만들어주면 되는 작업이라고 생각하면 되고, 우리가 할것은 딱 2개이다. 숫지인지, 아니면 연산자인지만 판별해주면 된다.
생성자의 필드는 다음과 같다.
class Lexer {
string text;
size_t pos = 0;
Lexer(const string& input) {
text = input;
}이제 타입에 맞게 파싱만 해주면 된다. 클래스는 Lexer 클래스로 정의한다.
Class Lexer{
string text;
size_t pos = 0;
}파싱할 대상의 text를 받아보자.
int main() {
string str = "12*(34+56)";
Lexer lexer(text);
Token t;
while((t = lexer.getNextToken()).type != TokenType::EOF){
cout << "Token(" << t.value << ")\n";
}이 함수를 실행했을때의 결과는
Token(12)
Token(*)
Token(()
Token(34)
Token(+)
Token(56)
Token())이렇게 나와야 한다.
함수를 하나하나 파헤쳐보자.
기본적으로, 숫자의 길이가 어느정도이기 모르기때문에, 동작 하나하나의 return을 받아야 한다.
while(pos < this->text.size()){
char c = text.at(pos);pos의 위치는 처음부터 시작하지만, iterator형식으로 쓸거기 때문에, 결국 pos값은 필드값으로 계속 갱신해나갈것이다. 그리고, iterator이고, 숫자의 길이도 모르기때문에, 전체를 다 도는 범위로 설정하고, string의 크기보다 크게 된다면, 그경우에 while문을 탈출하면 된다.
if(is_space(c)){
pos++;
continue;
} 우리는 공백은 따로 토큰처리를 하지 않는다. 그렇기 때문에, 공백일경우는 그냥 skip하고 넘어간다.
if('0'<=c && c<='9'){
string num = "";
while( pos < this->text.size() && (is_digit(text.at(pos)))){
num = num + text.at(pos++);
}
return {TokenType::NUMBER, num};
}만약, 문자열에서 뽑아낸 애가 0~9사이의 숫자인 경우라면, 뒤에 숫자가 나올수도 있기 때문에, 그전까지 값을 계속 저장해서 string형식으로 저장한다.
if(c == '+'){
pos++;
return {TokenType::PLUS, "+"};
}
if(c == '-'){
pos++;
return {TokenType::MINUS, "-"};
}
if(c == '*'){
pos++;
return {TokenType::MUL, "*"};
}
if(c == '/'){
pos++;
return {TokenType::DIV, "/"};
}
if(c == '('){
pos++;
return {TokenType::LPAREN, "("};
}
if(c == ')'){
pos++;
return {TokenType::RPAREN, ")"};
}
throw runtime_error("Invalid character");
}
return {TokenType::END, ""};
}만약, 연산자라면, 연산자별로 TokenType과 TokenValue를 같이 저장해서 입력받은 배열 값을 저장한다.
근데, 궁굼해진게 있다.실제 컴파일러는 C또는 C++로 작성된다. 그러면 그 C와 C++는 어떻게 실행될 수 있던것인가? 갑자기 너무 큰 의문이 들었다.
그렇게 해서 알게 된 용어는 자기부트스트랩이라는 용어를 알게되었다.
우리는 이 질문을 던져보자.
❔닭이 먼저냐? 달걀이 먼저냐?
- 자기부트스트랩인 언어 (Java, Go, …)등의 언어를 제외하고 나머지 언어는 C/C++로 작성되어져 있다.
- C++코드를 컴파일 하려면 컴파일러가 필요한데 그 컴파일러는 어디에 있을까?
- 처음에는 C를 컴파일러로 작성해서 C++코드를 C로 변환하는 과정을 거쳤다.
근데, 또 생각해보면, C 도 C로 컴파일 하지 않나?
이 질문에 대한 답은, 확정적으로 C언어 컴파일러는 어셈블리어로 작성되어졌다.
그래서 C를 어셈블리로 만든 컴파일러가 존재했는데, 이 컴파일러로 다시 C컴파일러를 작성했다.
그러면, 닭이 먼저냐? 달걀이 먼저냐? 에 대한 의문이 생기게 되었고, 사용자는 이를 몰라도 결국 자기부트스트랩방식으로 정상적으로 컴파일 코드를 컴파일할 수 있게 되는것이다.
우리는 재귀요정과 같이 컴파일 요정이 있다고 생각하고 이제 컴파일러를 만들기 시작해보자.
(참고로 내가 짜려고 하는건 LLVM/lCang 컴파일러다)


컴파일러를 만들다니 정말 대단하시네요